LDA(線形判別分析)

LDA(線形判別分析)とは?
LDA(線形判別分析)は、統計学および機械学習において使用される手法で、クラス間の分離を最大化するような方法でデータを低次元に射影することによって、クラス識別や次元削減を行うものです。
この記事ではscikit-learnライブラリに実装されているLinearDiscriminantAnalysisクラスを利用して線形判別分析を行ってみたいと思います。
データセットの読み込み
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target今回はscikit-learnのデータセットにあるiris(アヤメ)データセットを利用します。特徴量としては4個、データポイントは150個のデータです。また目的変数として3種の花の種類があります。
データセットの分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)訓練用とテスト用にデータを分割します。
LDAの学習
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X_train, y_train)LinearDiscriminantAnalysisクラスを出力する次元数を2に設定して初期化しています。LDAモデルの学習を行います。
学習したLDAモデルでデータを射影
X_lda = lda.transform(X)transformメソッドは、データをLDAによって見つけた最適な射影軸に射影します。
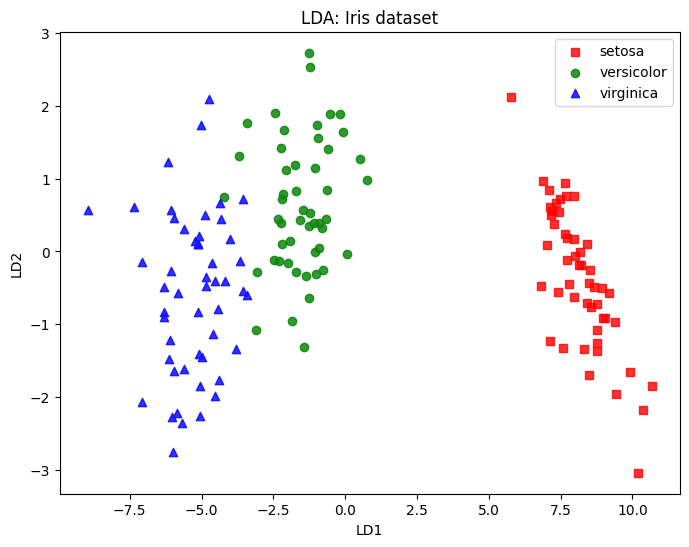
射影した結果を視覚化
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
marker_shapes = 'so^'
colors = ['red', 'green', 'blue']
labels = iris.target_names
for i, label in enumerate(labels):
plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], alpha=0.8, c=colors[i], marker=marker_shapes[i], label=label)
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.title('LDA: Iris dataset')
plt.legend(loc='best')
plt.show()