『Python実践データ分析100本ノック』ノック46〜50

今回は、『Python実践データ分析100本ノック』で学んだことをアウトプットします。
ダミー変数化
性別などのカテゴリー関連のデータをカテゴリカル関数と呼びます。これらのデータを活用するためには、フラグ化することが必要で、これをダミー変数化と言います。
pandasの、get_dummies()を使用すると一括でダミー変数化が可能です。文字列データを列に格納し、簡単にダミー変数化してくれます。
predict_data = pd.get_dummies(predict_data)
predict_data.head()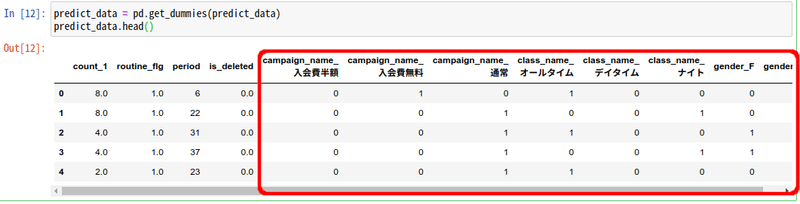
ダミー変数ですが、一点注意が必要です。例えば、男性・女性を表現する際、女性列(gender_F)に1が格納されていれば女性ですが、0であれば男性と理解でき、わざわざ男性列(gender_M)は必要ありません。
会員区分なども同様で、2つとも0であれば、3つ目のflgが立った状態と同じであることが分かります。そのため、それぞれ1つは消す必要があります。
ここでは、campaign_name_通常、class_name_ナイト、gender_M列を削除することにします。
del predict_data['campaign_name_通常']
del predict_data['class_name_ナイト']
del predict_data['gender_F']
predict_data.head()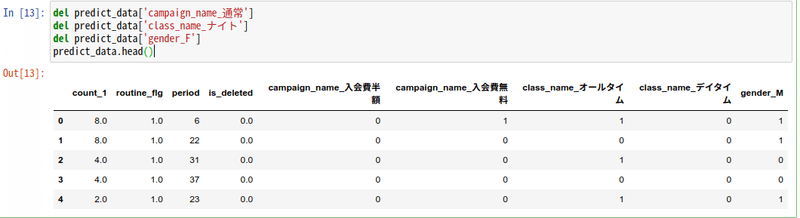
ノック47:決定木を用いて退会予測モデルを作成してみよう
from sklearn.tree import DecisionTreeClassifier
import sklearn.model_selection
exit = predict_data.loc[predict_data['is_deleted'] == 1]
conti = predict_data.loc[predict_data['is_deleted'] == 0].sample(len(exit))
X = pd.concat([exit, conti], ignore_index=True)
y = X['is_deleted']
del X['is_deleted']
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y)
model = DecisionTreeClassifier(random_state=0)
model.fit(X_train, y_train)
y_test_pred = model.predict(X_test)
print(y_test_pred)1から2行目はライブラリのインポートです。1行目は決定木を使用するためのライブラリです。2行目は学習データと評価データを分割するのに必要なライブラリです。
次のブロックの2行では退会と継続のデータ件数を揃えています。継続は2842件、退会は1104件だったのを、継続のデータからランダムに抽出して1104件に抑えて、比率が50対50になるようにしています。
その次のブロックでは、先程バラバラにしたデータを結合したのち、is_deleted列を目的変数のyと、is_deleted列を削除したデータを説明変数のXとしています。さらに、学習データと評価データの分割を行っています。
最後のブロックでは、モデルを定義し、fitに学習用データを指定し、モデルの構築を行っています。その後、構築したモデルを用いて評価データの予測を行い、最後に出力しています。
出力結果を見ると、0か1が表示されており、1は退会、0は継続と予想されたのを意味します。
実際に正解との比較を行うために、実際の値y_testと一緒にデータフレームに格納しておきましょう。
results_test = pd.DataFrame({'y_test':y_test, 'y_pred':y_test_pred})
results_test.head()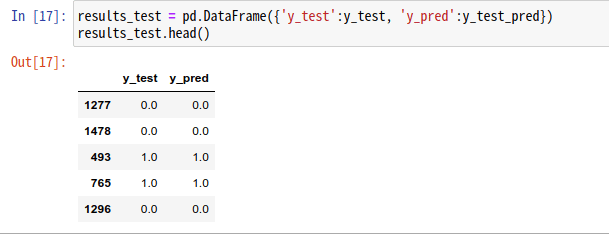
ノック48:予測モデルの評価を行ない、モデルのチューニングをしてみよう
機械学習の目的は未知へのデータへの適合なので、学習用データで予測した精度と評価用データで予測した精度の差が小さいのが理想的です。そこで、それぞれのデータを用いた際の精度を並べることにします。
精度はscore()を用いることで簡単に算出することができます。
print(model.score(X_test, y_test))
print(model.score(X_train, y_train))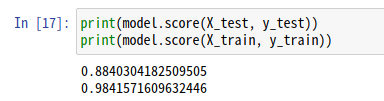
出力結果を見てみると、学習用データを用いた場合が98%で、評価用データを用いた予測精度が88%となっています。学習用データに適合しすぎており、過学習傾向にあります。
その場合、データを増やしたり、変数を見直したり、モデルのパラメータを変更したりすることで理想的なモデルに持っていきます。今回は、モデルのパラメータをいじってみます。
決定木は、最も綺麗に0と1を分割できる説明変数及びその条件を探す作業を、木構造状に派生させていく手法です。分割していく木構造の深さを浅くしてしまえばモデルは簡易化できます。
X = pd.concat([exit, conti], ignore_index=True)
y = X['is_deleted']
del X['is_deleted']
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y)
model = DecisionTreeClassifier(random_state=0, max_depth=5)
model.fit(X_train, y_train)
print(model.score(X_test, y_test))
print(model.score(X_train, y_train))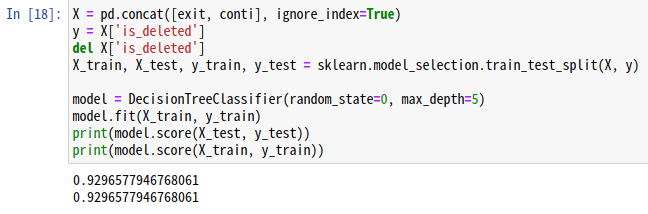
上記のコードブロックにおいて、モデルを定義する際にmax_depthを5に指定してます。これによって、決定木の深さは5階層で止まります。
max_depthを指定しない方が学習用データでの評価は高いですが、過剰適合によって評価用データの精度が低くなっています。
出力結果から、max_depthを指定し、モデルを簡易化することで未知のデータにも適応できる良いモデルができました。
ノック49:モデルに寄与している変数を確認しよう
model.feature_importance_で重要変数を取得します。
importance = pd.DataFrame({'feature_names': X.columns, 'coefficient': model.feature_importances_})
importance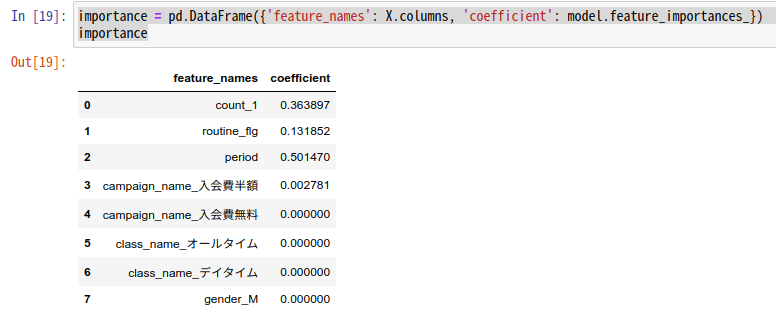
ノック50:顧客の退会を予測しよう
適当に、1ヶ月前の利用回数3回、定期利用者、在籍期間10,キャンペーン区分は入会費無料、会員区分はオールタイム、性別は男で入力データを作成し、予測をすることにします。
count_1 = 3
routine_flg = 1
period = 10
campaign_name = '入会費無料'
class_name = 'オールタイム'
gender = 'M'if campaign_name == '入会費半額':
campaign_name_list = [1, 0]
elif campaign_name == '入会費無料':
campaign_name_list = [0, 1]
elif campaign_name == '通常':
campaign_name_list = [0, 0]
if class_name == 'オールタイム':
class_name_list = [1, 0]
elif class_name == 'デイタイム':
class_name_list = [0, 1]
elif class_name == 'ナイト':
class_name_list = [0, 0]
if gender == 'F':
gender_list = [1]
elif gender == 'M':
gender_list = [0]
input_data = [count_1, routine_flg, period]
input_data.extend(campaign_name_list)
input_data.extend(class_name_list)
input_data.extend(gender_list)カテゴリカル変数をif文で分岐し、ダミー変数を作成しています。
それらのデータをextend()を用いて、1つのリストに格納します。
extendについては、こちらのサイトが参考になりました。
リストのメソッドextend()で、末尾(最後)に別のリストやタプルを結合できる。すべての要素が元のリストの末尾に追加される。
予測は、1か0の結果だけでなく、確率で表すこともできます。
print(model.predict([input_data]))
print(model.predict_proba([input_data]))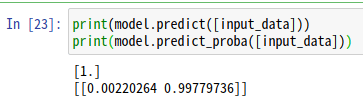
実行すると、最初に予測した分類結果。今回の場合、1、つまり退会が予測されています。2行目で出力しているのが、それぞれ0/1の予測確率が出力されています。
今回の結果では、98%の確率で退会と予想しているということです。
今回の学びのまとめ
○性別などのカテゴリー関連のデータをカテゴリカル関数と呼ぶ。
○カテゴリカル変数を活用するためには、フラグ化することが必要で、ダミー変数化と言う。pandasの、get_dummies()を使用すると一括でダミー変数化が可能。文字列データを列に格納し、簡単にダミー変数化してくれる。
○機械学習では、学習用データで予測した精度と評価用データで予測した精度の差が小さいのが理想的。精度はscore()を用いることで算出できる。
○リストのメソッドextend()で、末尾(最後)に別のリストやタプルを結合できる。すべての要素が元のリストの末尾に追加される。
サポート、本当にありがとうございます。サポートしていただいた金額は、知的サイドハッスルとして取り組んでいる、個人研究の費用に充てさせていただきますね♪