『Python実践データ分析100本ノック』ノック68〜70

今回は、『Python実践データ分析100本ノック』で学んだことをアウトプットしていきます。
ノック68:ロジスティクスネットワーク設計問題を解いてみよう
ノック67までは、輸送ルートと生産計画の最適化問題を、それぞれ個別に考えてきました。しかしながら、実際のロジスティクスネットワーク(物流ネットワーク)を考える場合、それらを同時に考える必要があります。
最終的に製品を販売する小売店(商店P、Q)があり、そこで販売される製品群(製品A、B)には一定の需要が見込まれており、それらの需要量に基づいて工場(工場X、Y)での生産量は決められます。
それぞれの製品をどの工場のどの生産ライン(レーン0、1)で製造するのかについては、各工場から小売店への輸送費や、製造コストなどを加味して決められます。
こうしたロジスティクスネットワークの最適化を行うには、どのような最適化問題を定式化するのがよいでしょうか?商品の需要が既に決まっているのであれば、もっとも重要なのは、いかにコストを下げるかでしょう。
したがって、輸送コストと製造コストが、需要を満たしつつ最小になるように定式化します。
すなわち、目的関数としては輸送コストと製造コストの和を与え、制約条件としては各商店での販売数が需要数を上回ることを考えます。
ここでは、ortoolpyというライブラリを用いて、関数logistics_networkによって最適設計を行っていきます。
import numpy as np
import pandas as pd
製品 = list('AB')
需要地 = list('PQ')
工場 = list('XY')
レーン = (2, 2)
# 輸送表
tbdi = pd.DataFrame(((j, k) for j in 需要地 for k in 工場), columns=['需要地', '工場'])
tbdi['輸送費'] = [1, 2, 3, 1]
print(tbdi)
# 需要表
tbde = pd.DataFrame(((j, i) for j in 需要地 for i in 製品), columns=['需要地', '製品'])
tbde['需要'] = [10, 10, 20, 20]
print(tbde)
# 生産表
tbfa = pd.DataFrame(((k, l, i, 0, np.inf) for k, nl in zip(工場, レーン) for l in range(nl) for i in 製品),
columns=['工場', 'レーン', '製品', '下限', '上限'])
tbfa['生産費'] = [1, np.nan, np.nan, 1, 3, np.nan, 5, 3]
tbfa.dropna(inplace=True)
tbfa.loc[4, '上限'] = 10
print(tbfa)
from ortoolpy import logistics_network
_, tbdi2, _ = logistics_network(tbde, tbdi, tbfa)
print(tbfa)
print(tbdi2)うーん。
どうも以下の部分が理解できない…
# 生産表
tbfa = pd.DataFrame(((k, l, i, 0, np.inf) for k, nl in zip(工場, レーン)
for l in range(nl) for i in 製品),
columns=['工場', 'レーン', '製品', '下限', '上限'])まず、Zip関数について忘れているようなので、こちらのサイトで復習。
Zip関数の使い方: 複数のリストの要素をまとめて取得
forループの中で複数のイテラブルオブジェクト(リストやタプルなど)の要素を同時に取得して使いたい場合は、zip()関数の引数にそれらを指定する。
names = ['Alice', 'Bob', 'Charlie']
ages = [24, 50, 18]
for name, age in zip(names, ages):
print(name, age)
# Alice 24
# Bob 50
# Charlie 18本書のコードでは、
for k, nl in zip(工場, レーン)の部分で、nlには、数値の2が2回登場することになり、さらに、
for l in range(nl)の部分で、lには、0, 1の順で数値(「レーン番号」と呼ぶ方が正確かも)が入ることになるのかな?
もし私の理解が間違っていたら、ご指摘いただければ幸いです。
本書のコード実行結果

関数logisitcs_networkを用いると、生産表にValYという項目が作られ、最適生産量が格納され、また、輸送費表にValXという項目が作られ、最適輸送量が格納されます。
ノック69と70で、これらの結果が妥当かどうかを確認していきます。
ノック69:最適ネットワークにおける輸送コストとその内訳を計算しよう
輸送コストは、関数logistics_networkの戻り地として、tbdi2にデータフレーム形式で格納されています。「輸送費」のカラムと、最適輸送量を格納する「ValX」のカラムを掛け合わせることで、輸送コストが計算できます。
print(tbdi2)
trans_cost = 0
for i in range(len(tbdi2.index)):
trans_cost += tbdi2['輸送費'].iloc[i] * tbdi2['ValX'].iloc[i]
print('総輸送コスト:' + str(trans_cost))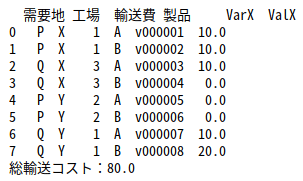
計算結果から、総輸送コストは80(万円)と計算されました。
内訳としては、なるべく輸送量の少ない工場X→商店P、工場Y→商店Qのルートを使用し、それだけでは、商店Qにおける製品Aの需要が若干まかないきれないので、工場Xから商店Qへ、製品Aを10だけ輸送しています。
工場Yでの生産には限界があり、また、生産表によると、工場Xの製品Aの生産コストは他に比べて低いことから、この組み合わせは、概ね妥当と判断して良さそうです。
ノック70:最適ネットワークにおける生産コストとその内訳を計算しよう
生産コストは、関数logistics_networkの計算後、tbfaに格納されます。「生産費」のカラムと、最適生産量を格納する「ValY」のカラムを掛け合わせることで、生産コストが計算できます。
print(tbfa)
product_cost = 0
for i in range(len(tbfa.index)):
product_cost += tbfa['生産費'].iloc[i] * tbfa['ValY'].iloc[i]
print('総生産コスト:' + str(product_cost))
総生産コストは120(万円)となりました。
内訳としては、なるべく生産コストの低い工場Xでの生産量を増やしたいということから、工場Xでの製品Aの生産量を20に、また製品Bの生産量を10にしていると考えると合理的ですね。
生産コストだけを考えると、すべての製品を工場Xのみで製造したいところですが、輸送コストとの兼ね合いから、ある程度は、需要量の多い商店Qへの輸送コストの低い工場Yを稼働させないわけにはいかないようです。
結果として、工場Yでの製品Aの製造量は10に、製品Bの製造量は20になっています。生産コストと輸送コストのバランスを考えると、概ね妥当そうですね。
サポート、本当にありがとうございます。サポートしていただいた金額は、知的サイドハッスルとして取り組んでいる、個人研究の費用に充てさせていただきますね♪