[Stataによるデータ分析入門]固定効果モデルの推定xtreg,feとreghdfeの違い

Stata社が用意したコマンドで固定効果モデルを推定する場合にはxtreg ,fe コマンドを利用しますが、同じ結果を出力できるreghdfeコマンドのほうが何かと便利でよく使われています。本稿では両者の違いについて紹介します。
xtreg,feとreghdfeの使い方
今、yit=a+bXit+Zi+uitという固定効果モデルを推定するとします。個体番号をID、時点を示す変数をyearとします。このとき、xtreg ,feコマンドで固定効果モデルを推定するには、
tsset ID year
xtreg y x,fe robust
xtreg y x i.year,fe robustと入力します。ここでtssetはパネルデータ構造を認識させるコマンドで、個体番号と時点番号がそれぞれID、yearであることをStataに認識させています。このコマンドは一度実行すれば、再度実行する必要はありません。2行目のxtreg y x,feは個体固定効果のみを導入した推定式、3行目はi.yearで年次ダミー(年次固定効果)を導入した二次元固定効果モデルです。feの後ろのrobustは「頑健な標準誤差」(robust standard error)を出力せよというオプションです。固定効果モデルでは、個体番号でクラスタリングした標準誤差を用いることが望ましいことが知られていますが、xtreg, feでrobustオプションを指定すると、個体番号でクラスタリングした標準誤差が出力されます。
※標準誤差の個体番号によるクラスタリングについては「Stataによるデータ分析第3版」P.Xを参照してください。
一方、reghdfeはユーザー関数と呼ばれるStataのユーザーが作成したコマンドです。hdfeはhigh dimensional fixed effectの略なので、reghdfeは「高次の固定効果を含む回帰モデル」という意味になります。このコマンドを利用するには、予めコマンドラインに以下を入力して、ftoolsとreghdfeをインストールしておく必要があります。
ssc inst ftools
ssc inst reghdfeそして、reghdfeでは、以下のようにabsorbオプションで個体番号と時点番号の変数を指定する固定で固定効果モデルの推定が可能です。
reghdfe y x,absorb(ID) vce(cl ID)
reghdfe y x,absorb(ID year) vce(cl ID)ここで1行目は個体固定効果のみが含まれるモデル、2行目は個体固定効果と年次固定効果の2つを考慮した二次元固定効果モデルです。vce(cl ID)は標準誤差を個体番号でクラスタリングして計算せよという意味で、xtreg ,feコマンドでrobustオプションをつけたときと同じ結果が得られます。
xtreg,feとreghdfeの違い
両者の違いについてみていきましょう。第一は、二次元固定効果モデルの書き方です。xtreg,feでは個体固定効果モデルは自動的に導入されますが、時間固定効果を含める場合には分析者が説明変数に年次ダミーを追加する必要があります。一方、reghdfeの場合、absorbオプションに個体番号と時点番号に対応する変数を記入すればOKです。第二に、出力される決定係数が異なります。xtreg,feでは、固定効果の説明力を除いた上で、説明変数XがYの変動をどの程度説明しているかを示す決定係数が表示されます。そのため、固定効果の説明力が高い場合、xtreg,feが出力する決定係数は低い値になることがあります。一方、reghdfeが出力する決定係数は、説明変数X+固定効果がどの程度Yの動きを説明するかを示すので、推計式そのものの説明力を示します。分析結果を評価する上では後者のほうが理解しやすいかと思います。
具体例
「Stataによるデータ分析第3版」の事例を使って両コマンドの違いを見てみましょう。chapter5-2.doファイルでは二国間貿易額ltradeを被説明変数、説明変数に輸出国と輸入国のGDP(lgdp_o, lgdp_d)、FTAの有無を示すダミー変数(fta)を説明変数とする固定効果モデルの推定を行っています。以下は、xtreg, feによる推計結果です。R-sqが決定係数です。
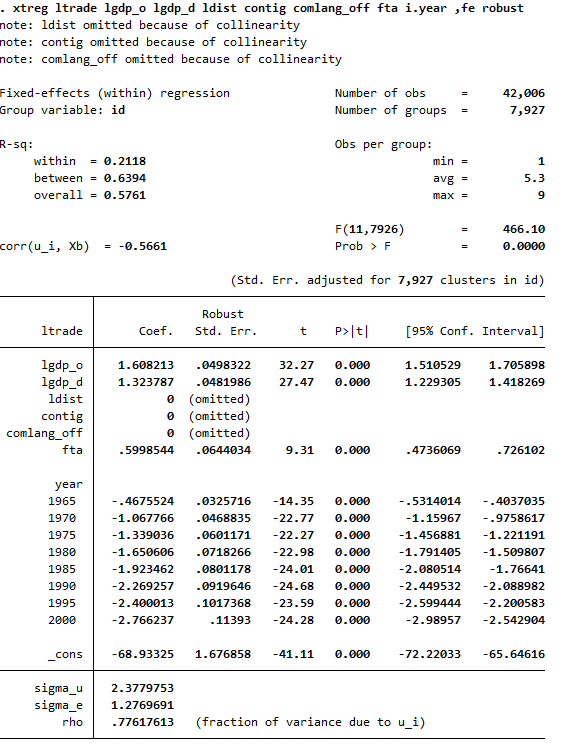
一方、reghdfeによる推計結果が以下に示されています。

いずれも係数、標準誤差、t値が等しいことが分かります。しかし、決定係数がかなり異なる数値になっていることに気づくでしょうか?xtreg,feでは、within, between, overallの3つが示されていますが、一番大きいoverallでも0.57です。一方、reghdfeでは自由度修正済み決定係数で0.8471です。この2つのコマンドでは決定係数の計算方法が異なるのですが、前述した通り、後者では固定効果の説明力を考慮した値になっており、モデル全体としての説明力を示す指標になっているので、理解しやすいかと思います。
なお、xtreg,feとreghdfeでは、Numbner of Obs(サンプル数)も異なっていますが、そもそも固定効果モデルでは、1時点しかデータがない個体については係数の推定には利用できません。reghdfeの結果には、dropped 975 singleton observationsという表記が出ていますが、これは1時点しかデータがない個体のサンプル(signleton)を除外した推計したよ、という意味で、Number of Obsには実際に推定に用いられたサンプル数が表示されています。
Stataによるデータ分析入門第3版のWEB補論の一覧はこちら。
この記事が気に入ったらサポートをしてみませんか?