[Stataによるデータ分析入門]多項ロジット・モデル

本稿は、「Stataによるデータ分析入門第3版」の第4章、および逆引き事典の「条件付きロジット・モデル、多項ロジット・モデル」補論です。
第4章では、被説明変数が0か1のような二値選択に用いる分析手法としてロジット・モデル(logit)とプロビット・モデル(probit)を紹介しました。また、逆引き事典の「条件付きロジット・モデル、多項ロジット・モデル」では、被説明変数が複数の値をとる多項ロジット・モデル(Multinomial Logit, 以下Mlogit)とStataにおける推計コマンドmlogitについて紹介しましたが、ここではより詳細な情報を提供します。
使用するデータとMlogitモデルの特徴
次のデータは逆引き事典の「条件付きロジット・モデル、多項ロジット・モデル」でも紹介した自動車のブランド選択で、
被説明変数: car
・ 1.米国車(フォード、GM等)、2.日本車(トヨタ、日産等)、3.欧州車(ベンツ、ルノー等)
説明変数
・sex(男性なら1)・income(所得)
です。データは以下からダウンロードできます。
Mlogitでは、説明変数が、すべて「被説明変数の選択肢に依存しない変数」になっている必要があります。たとえば、一般に職種選択では、各職種ごとに異なる「期待される収入」が重要な要素になります。こうした変数は「被説明変数の選択肢に依存する変数」ですが、上記のデータには含まれていません。こうした変数を使う場合は条件付きロジットモデルを使用します。
もう一つの特徴は、Mlogitモデルは、「ある選択肢を基準として、その対比で、それ以外の選択肢が選ばれる確率を推計する」、というものです。ここは抽象的なので、先に推計方法と推計結果を紹介しましょう。
Stataによる推計方法
StataによるMlogitの推計は、mlogitコマンドを使います。
mlogit y x1 x2 x3
Option:base(#) 基準となる選択肢を指定
使用するデータ:choice-mlogit.dta
被説明変数car:1.米国車、2.日本車、3.欧州車
説明変数
・sex(男性なら1)・income(所得)
以下、Stataのコードと推計結果です。
cd c:\data
use choice-mlogit.dta,clear
mlogit car income sex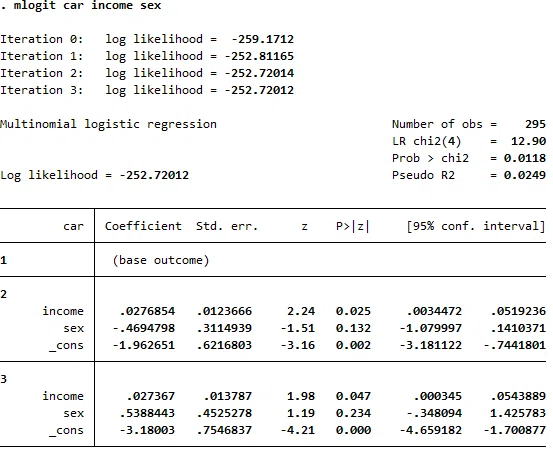
mlogitコマンドの推計結果では、被説明変数の選択肢ごとに係数が出てきます。選択肢1だけ係数がないのは、選択肢1を基準としているからです。係数の読み方ですが、
・選択肢2(日本車)では、incomeの係数がプラスで、P値が5%を下回っており統計的に有意です。sexは負ですがP値は10%を上回っていますので統計的に有意であるとはいえません。読み方ですが、基準である選択肢1(米国車)との対比なので、所得の高い人ほど米国車より日本車を選ぶ、と読みます。
・選択肢3(欧州車)の場合も同様で、incomeの係数が正でP値が5%を下回っています。こちらも、選択肢1(米国車)との対比で、所得の高い人は米国車より欧州車を選択する、と読みます。
基準はbaseオプションで変更できます。たとえば日本車を基準にするならば、mlogit car income sex, base(2)と入力します。

この場合、日本車との比較で、どのような人が米国車や欧州車を選ぶかを示します。興味深いのは、選択肢3の結果で、sexの係数がプラスでP値が5%未満で統計的に有意になっています。この結果は、男性は日本車より欧州車を選ぶ、女性は欧州車より日本車を選ぶ傾向にあることを示しています。
限界効果の計算
説明変数の影響度合いについては、ロジット・プロビット・モデルと同様、marginsコマンドを使って計算する必要があります。限界効果は基準となる選択肢についても計算することが可能ですので、こちらのほうが解釈しやすいかもしれません。
margins, dydx(*) predict(outcome(1)) predict(outcome(2))
predict(outcome(3))以下は、職種選択モデルについて限界効果を計算したものです。たとえば、incomeの1には-0.0060892という数値がみえますが、これは所得が1増えると、米国車を選択する確率が0.6%下がると読むことができます。なお、限界効果は、mlogitの基準となる選択肢の設定の影響を受けません。米国車を基準にしても日本車を基準にしても同じ結果が得られます。

多項ロジット・モデルの係数の意味
Mlogitモデルでは、選択肢zを選ぶ確率を${ Choice==z }$とするとき
$${ \frac{Prob(Choice==2)}{Prob(Choice==1)}=\beta_{21} +\beta_{21} X_1+\beta_{31} X_3 }$$
という式を推定しています。そのため基準となる選択肢を指定する必要があります。
データについて補足
ここで使用するデータはStata社から提供されているデータを以下のようにchoice.dtaを加工して用意したものです。
webuse choice.dta,clear
keep if choice==1
drop choice size dealer
save choice-mlogit.dta,replaceStataによるデータ分析入門第3版のWEB補論の一覧はこちら。
この記事が気に入ったらサポートをしてみませんか?