
Googleより、新しいオープンソース生成AI "Gemma2"登場。 Llama3との競争がいよいよ始まりました!

いよいよ、Googleより新型のオープンソース生成AI "gemma2"が登場しました(1)。既に予告はあったのですが、思ったより早く出てきました。以下のように27Bモデルはリーダーボードで12位と大型モデルに肉薄する大変優秀な成績を誇っています。テクニカルレポート(2)もありましたので、早速どんな進化があったのか見てみることにしましょう。

1. モデル・アーキテクチャ
Gemma2 はおなじみの decoder-only transformer architectureを採用してます。GPT4と同じですね。また一度に入力・出力できる情報量を示すcontex windows は 8192 tokensとなってます。モデルの構造は概ねGemma1と同じとなってますが、テクニカルレポートによると以下のポイントが新しくなっているようです。
"私たちは、Local Sliding Window Attentionと Global Attentionを交互に各層で使用します。Local Attention層のSliding Windowのサイズは4096トークンに設定され、一方でGlobal Attention層のスパンは8192トークンに設定されています。"

2.Pre-training
Gemma2のトレーニングデータは以下のようになっています。
27Bモデル : 主に英語のデータ13兆token
9Bモデル : 8兆token
2.6Bモデル: 2兆token
”これらのtokenは、ウェブ文書、コード、科学論文など、さまざまなデータソースから得られています。このモデルはマルチモーダルではなく、最先端の多言語モデルとしてトレーニングされているわけではありません。また、トークンナイザーはGemma 1やGeminiと同じで、分割された数字、保持された空白、およびバイトレベルのエンコーディングを持つ"SentencePiece"です。語彙は256,000個です。”とのことです。
また、9B・2.6Bモデルに知識蒸留が採用されました。私の考えではこれがgemma2の最も進化したポイントかと思います。Googleには既に大型の生成AIが稼働しているので、その利点も活かして小型のモデルの性能をあげようというGoogleならではの戦略ですね。テクニカルレポートで詳しく説明されています。
"教師として使用される大規模モデルが与えられた場合、各トークン𝑥がそのコンテキスト𝑥𝑐が与えられた時の教師の確率、つまり𝑃𝑇(𝑥 | 𝑥𝑐)から蒸留することで、より小さな9B・2.6Bモデルを学習します。より正確には、教師と生徒の確率間の負の対数尤度を最小化します:
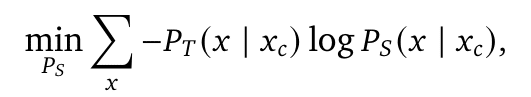
ここで、𝑃𝑆は生徒のパラメータ化された確率です。実際には、教師に対して一度推論を実行し、確率を保存します。語彙には25万6千のエントリーがあるため、教師の確率のサンプリングされた部分集合のみを保存します。"
3.Post-training
この部分では他の生成AIでもよく見られる手法が使われています。テクニカルレポートによると以下のプロセスで実施されています。
"ポストトレーニングにおいては、事前学習済みモデルを指示調整済みモデルへとfine-tuningします。まず、テキストのみの英語のみの合成データと人間が生成したプロンプト-応答ペアの混合データに対して教師ありfine-tuning(SFT)を適用します。次に、これらのモデルの上にRLHF(強化学習による人間フィードバック)を適用します。この際、報酬モデルは英語のみの選好ラベル付きデータで学習され、policyはSFTと同じプロンプトに基づいています。最後に、各段階後に得られたモデルを平均化して、全体的な性能を向上させます。"
注目すべきは、再度知識蒸留が採用されている点です。
”合成プロンプトと実際のプロンプト、そして主に教師モデルによって合成的に生成された応答に対してbehavioral cloningを実行します”
今後大型モデルから小型モデルへの知識蒸留が一般的に使われていくのかも知れません。楽しみですね。
いかがでしたでしょうか?Gemma2は小型でも高い潜在能力を持っているモデルのようで期待できます。2.6Bモデルも近々リリースされることが期待されます。ちなみに、Gemma2を作成したGoogleと前回取り上げたLlama3を作成したMetaはオープンソースの世界では "Tensorflow vs PyTorch" の8年越しのライバル関係にあります。生成AIでも同様な戦いが始まったようですね。次回はGemma2モデルでいろいろなことを試してみたいと思います。お楽しみに。Stay tuned!
1) Gemma 2 is now available to researchers and developers, Google, 27 June 2024
2) Gemma 2 technical paper, Google DeepMind, 27 June 2024
3) Effective Approaches to Attention-based Neural Machine Translation, Minh-Thang Luong Hieu Pham Christopher D. Manning Computer Science Department, Stanford University, 20 Sep 2015
4) Longformer: The Long-Document Transformer, Iz Beltagy, Matthew E. Peters, Arman Cohan, Allen Institute for Artificial Intelligence, 2 Dec 2020
5) On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes, Rishabh Agarwal12∗ Nino Vieillard1∗ Yongchao Zhou13 Piotr Stanczyk1† Sabela Ramos1† Matthieu Geist1 Olivier Bachem1 1Google DeepMind 2Mila 3University of Toronto, 17 Jan 2024
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.