
【AI画像生成まとめ】(初心者向け)Google Colabを使って、Stable Diffusionを使って好きな画像&動画を作ろう!

Stable Diffusionを使ってAI画像生成
以前にGoogle Colabを使ってStable diffusionでアバターを自由に作る方法について書いていた。
その後、色々触っているうちにスキルが向上して、画像だけでなく、動画もそこそこ作れるようになった。方法自体は、メカニズムは複雑であるが、すごく簡単なので備忘録がてらまとめていきたい。
Automatic1111 でSDXL使えそうな感じだったので、#BreakDomainXL v02試してみた。
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) September 2, 2023
イラストの表現は豊かですごくオシャレ!
ちょっとしたデザイナーよりは芸術性も豊かな気がする。#AIart #AIイラスト好きと繋がりたい pic.twitter.com/UHTGGSe919
Deforumで、筋肉を進化させた自分の写真を元に動画作ってみた!
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) July 31, 2023
顔が変わるのがまだ解決していないけど、大分いい感じの動画では?#img2video #deforum #stablediffusion #AIart https://t.co/VlLus8CMUu pic.twitter.com/6AM8GGm5M3
LORAで自分の写真学習させてから、大学時代の年代の自分を実験的にStable Diffusionで動画生成...
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) August 6, 2023
こんな感じだったかな??<- 実際よりも垢抜けてます笑
これに自分の思考パターンを学習させたLLMのっければデジタルツインすぐにできてしまいそうに思えてくる。#aiart #stablediffusion pic.twitter.com/SKESQiUtPq
Google ColabでStable Diffusionをいじるときの注意点
まずGoogle Colab Proに課金すること
Stable DiffusionのWebUIであるAutomatic 1111がすごく使いやすく、情報も豊富
Mov2mov, ControlNet, DeforumなどのExtensionはWebUIを一度立ち上げてからインストールする必要があり、その後再度WebUIを立ち上げ直さないといけない
同じ顔を使って画像生成したいような時はLORAを追加学習させたり、ControlNetのReference-only 機能を使用する
動画生成はmov2movやDeforumnなどの機能を使用
LORAや一部モデルはGoogle Driveに入れて使用することもでき便利。このためGoogleドライブをマウントさせた方が良い
がGoogle Colab使用時の注意点である。
この中で一番重要なのは課金すること!
以前はGoogle Colabで無料で使用できたのであるが、画像生成をする人が多くなって計算機資源の消費がバカにならなくなり、今年から課金しないとフルスペックでWebUIが使えなくなった(課金していないと警告やエラーが出まくり、またプロセスが短時間で止まる)
その他の注意点については、以下で述べることにする
Automatic 1111によるWebUI
以前のnoteでも書いた通り、Automatic 1111が非常に使いやすい
詳細は以上のブログをみていただくとわかるが
Google ドライブをマウント
from google.colab import drive
drive.mount('/content/drive')Automaticのgit cloneとモデル、VAEの読み込みと立ち上げ
#AUTOMATIC1111読み込み
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
#モデル読み込み
!wget https://huggingface.co/ckpt/chilloutmix/resolve/main/chilloutmix_NiPrunedFp32Fix.safetensors -O /content/stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors
#!cp /content/drive/MyDrive/SD-MODELS/BlazingRealDrive_V01c.safetensors /content/stable-diffusion-webui/models/Stable-diffusion/BlazingRealDrive_V01c.safetensors
#!cp /content/drive/MyDrive/SD-MODELS/BreakDomainXL_V04a.safetensors /content/stable-diffusion-webui/models/Stable-diffusion/BreakDomainXL_V04a.safetensors
#VAE 読み込み
!wget https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.ckpt -O /content/stable-diffusion-webui/models/VAE/vae-ft-mse-840000-ema-pruned.ckpt.safetensors
#web UIの立ち上げ
%cd /content/stable-diffusion-webui
!python launch.py --share --xformers --enable-insecure-extension-accessがメインパートである。
この二つを動かして、

アウトプット欄に出てくるPublic URLをクリックするとwebUIが立ち上がる。またコメントアウトしてあるが、
!cp /content/drive/MyDrive/SD-MODELS/BlazingRealDrive_V01c.safetensors /content/stable-diffusion-webui/models/Stable-diffusion/BlazingRealDrive_V01c.safetensors
#!cp /content/drive/MyDrive/SD-MODELS/BreakDomainXL_V04a.safetensors /content/stable-diffusion-webui/models/Stable-diffusion/BreakDomainXL_V04a.safetensorsのようにGoogle driveにあるモデルを読み込んでも良い(これは必須でないので必要でない方は読み飛ばしてください)。
この後エクステンションのインストールの際に、webUIが止まるので、再度立ち上げ直す必要が出てくる。
立ち上げる前にLORA(後で出てきます)を読みこみたいなら(これは必須でないので必要でない方は読み飛ばしてください)、以下のようなセルを実行したのち
!cp /content/drive/MyDrive/LoRA/output/testLora.safetensors /content/stable-diffusion-webui/models/Lora再度UIを立ち上げ直す
%cd /content/stable-diffusion-webui
!python launch.py --share --xformers --enable-insecure-extension-accessこの4つのセルをGoogle Colabのノートブックに仕込んでおけば大概のことはできるはずである。
Deforum, ControlNet, Mov2movのインストール方法
次に特殊なControlNetやDeforumなどのエクステンションであるが、UIを立ち上げてから、インストールしてそれをUIに反映させる手法が一番簡単である。
Web UIがたちあがったら、メニューの端にあるExtensionsをクリック

Mov2movについては
Install from URLのタブをクリック
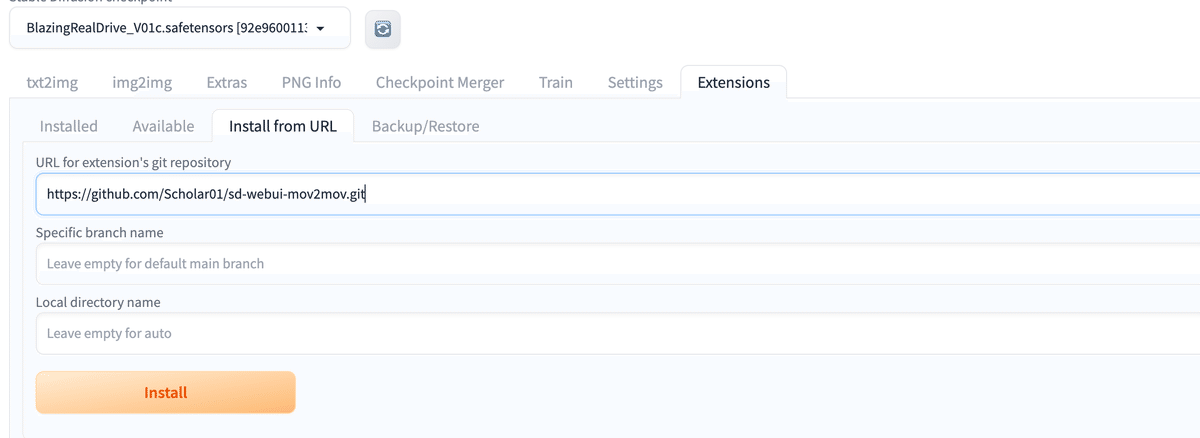
URL for Extension's git repositoryの欄に
https://github.com/Scholar01/sd-webui-mov2mov.git
を入力し、installをクリックする。
インストールにはしばらく時間がかかる。
DeforumとControlNetについては
Availableのタブをクリックし
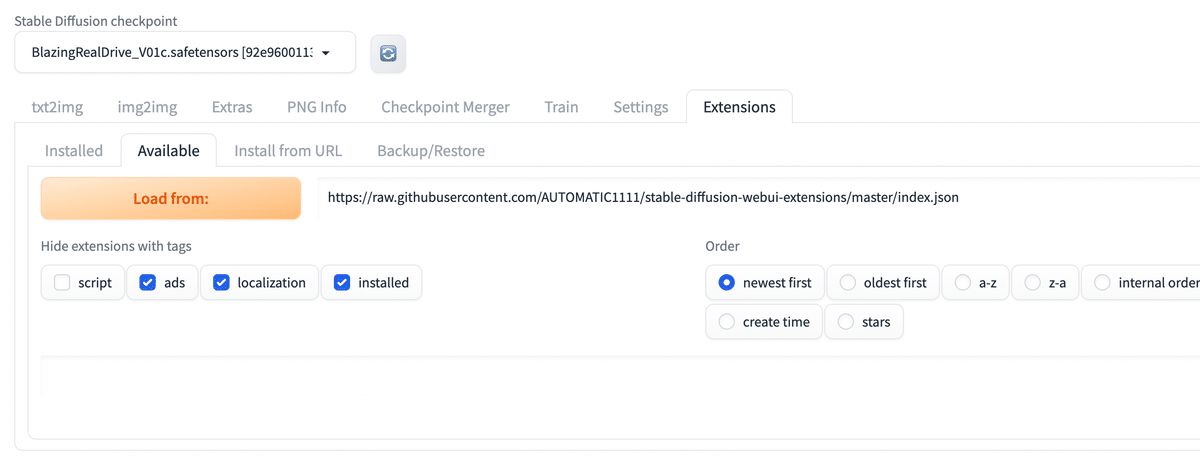
Load from
をクリック
すると以下のように利用可能なエクステンションのリストが出てくるので
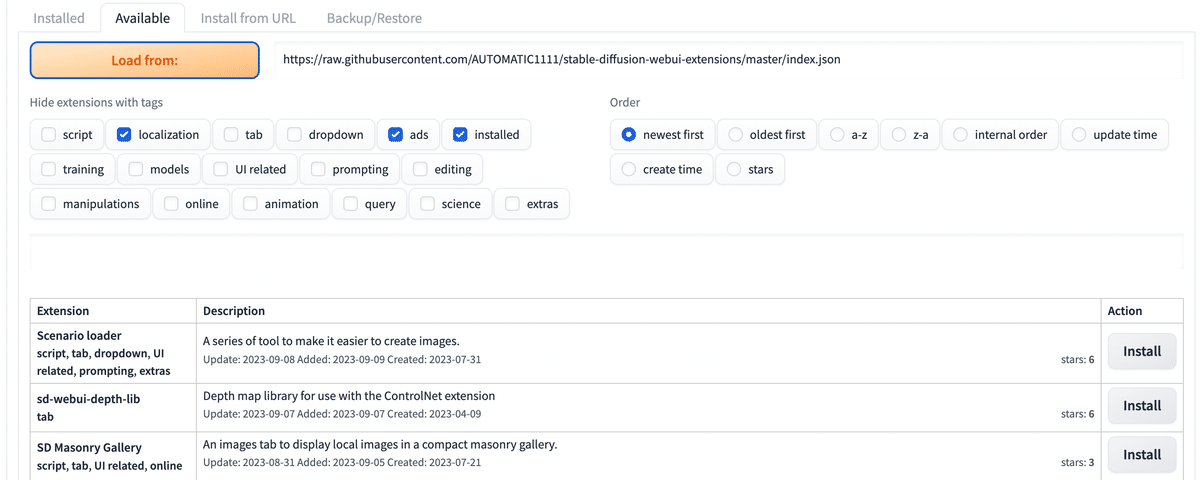
この中からDeforumのエクステンションを検索してインストールボタンをクリック

インストールが終わるのを待って、
controlNetの UIを検索(17個あるエクステンションのうちの一つです。またDeforumをつかうのにControlNetが必要になるので、この二つはセットでインストールすると良いです)

してインストールボタンをクリック
インストールが終わったら、
installedのタブをクリック
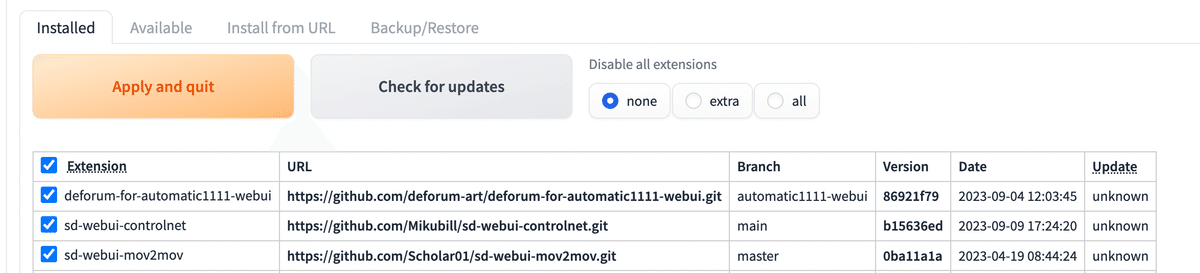
3つのエクステンションがインストールされているのを確認後、apply and quitをクリックします。
すると以下のように UIが止まるので
再度コラボのノートブックの方に戻って、以下の二つもしくは最後のセルを実行すると環境設定&立ち上げは完了します。
!cp /content/drive/MyDrive/LoRA/output/testLora.safetensors /content/stable-diffusion-webui/models/Lora%cd /content/stable-diffusion-webui
!python launch.py --share --xformers --enable-insecure-extension-accessうまく行っているのと、mov2mov, Deforum, Loraがタブで出てくるのですが、最近Automatic1111がバージョンアップされたせいか、mov2movはエラーが出てしまうようです。
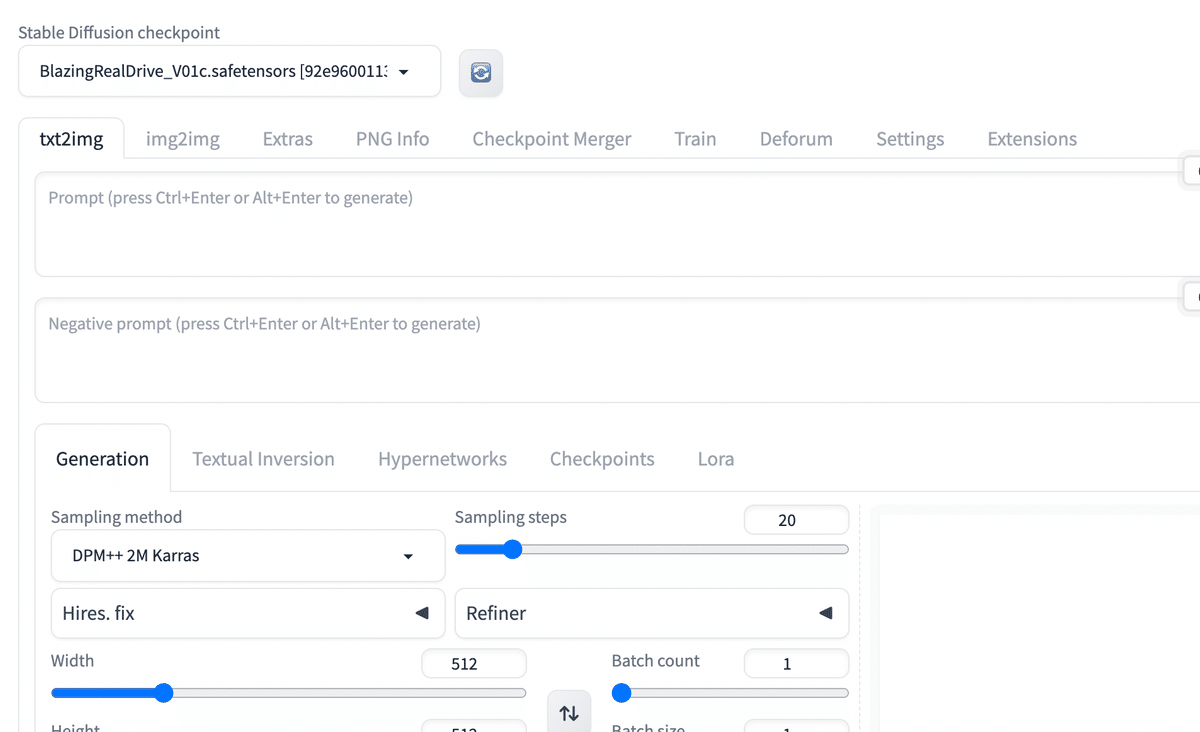
LORAに関してはLORAのタブをクリックして、必要なLORAをクリックすれば自動的に呪文が生成されます
<lora:testLora:1>
この:1の部分は、LORAを反映させる強度ですので、適宜調整してみると良いです。
以上が自分が行なっているインストール&設定方法です。
これで静止画&動画生成の大体のことができるようになっています。
各種Extensionの使い方に関しては他のブログの方が詳しく書いてあるので参考にしてみてください。
各種Extensionの使い方
Mov2movの使い方(なお現時点でmov2movにエラーが出る模様)
Deforumの使い方
https://youtube.com/watch?v=AIjLdiFSEww…
Reference-only (ControlNet) の使い方
自作LORAの作り方(Kohya-trainerを使います)
LORAの使い方
モデルについて
あとカスタムマージモデルとして、BDさんのモデルが面白いので使ってみると良いかもしれません。
作品例紹介
以上のような形で、エクステンションを多用すると色々と面白いことができる
Google colabでのmov2movによる動画生成、大分マスターしてきた!
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) July 29, 2023
✅被写体が大きい画像を選ぶ
✅人数1-2人が限度
✅ゆっくりした動きの方がまずは良い
✅元動画に引っ張られる#aianime #stablediffusion https://t.co/7ejeK2rEH8 pic.twitter.com/ZMT1nEzxzT
Anti-Aging? なんか若返ったかな?顔が変わるのはいただけない。。#deforumstablediffusion #AIart https://t.co/u6C47sPRSV pic.twitter.com/Wpu5YYxZdM
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) July 31, 2023
自分の写真を元に理想像作ってみた…
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) August 2, 2023
美容外科クリニックとかボディメークとかのプランニングに使えないかな…
あとメタ失敗したけどそのうちセカンドライフみたいなメタバースができたらみんなこういうやつつくるんだろうな…#img2video #deforum #stablediffusion #AIart https://t.co/TQdNzeSQmX pic.twitter.com/uUW0Nl67Ok
https://twitter.com/tokitky/status/1687931758736465920
自分の写真を追加学習させて自作LORA作ってから、画像生成やってみ端だけどある程度の特徴掴めているのに、美妙に似ていない感w
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) August 5, 2023
とりあえずやり方分かったからよしとしよう!
✅自作LORA学習法https://t.co/ilfoukio6b
✅Google ColabでのLORA使用方法https://t.co/x7YG4gOVsZ pic.twitter.com/3jWFb6khsE
LORAで自分の写真学習させてから、大学時代の年代の自分を実験的にStable Diffusionで動画生成...
— Toshi⁷ MD,PhD 🇺🇸|アメリカで医学研究&開発 (@tokitky) August 6, 2023
こんな感じだったかな??<- 実際よりも垢抜けてます笑
これに自分の思考パターンを学習させたLLMのっければデジタルツインすぐにできてしまいそうに思えてくる。#aiart #stablediffusion pic.twitter.com/SKESQiUtPq
まとめ
現時点のWeb UIを使えば、高度な画像生成の技術を手軽に扱えることがわかる。他の生成AIもそうだと思うけれど、段々とAIの原理を理解する人とAIをブラックボックス使う人の間に乖離が生まれてくる。
AI絵師の人たちの作人を見ていると、奥にある数学を理解することよりも、次々に出てくる技術をうまく乗りこなしてプロダクトを作る方が意義があるのではないか?最近画像生成AIをいじってみた感想である。
#BreakDomainXL _V02g#AIイラスト #AIArtworks
— Kaski_Anna@ (@G_Eskeles) August 17, 2023
Tシャツプロンプトを詰めてみました。 pic.twitter.com/UHtH5Qx09B
君はピーターパン
— モカMelody Mocha (@MelodyMocha0) August 28, 2023
You are my peterpan#AIart #生成AI #AIかわいい部 pic.twitter.com/Cb13NTKDrL
#AI背景部 #まちまちコンテスト
— アクシズの趣味の部屋 (@rx93tff) August 24, 2023
今日は遅くなってしまいましたが参加します。
ウユニ塩湖的な感じです。
画像使用OKです! https://t.co/s8BDoMLbEx pic.twitter.com/4ppYp8K7jU
この記事が気に入ったらサポートをしてみませんか?