
LangChain と Claude3 Haiku で Q&A精度向上の試み

はじめに
前回に引き続きのLangChain と今回は Claude3 Haiku を用いたQ&Aシステムの検証です。Claude3 Haikuについては以前の記事で GPT-3.5 よりも精度が高いことが判明しています。今回は実際のAPIを利用することで、Q&Aシステムに近づけて工夫の余地がないかを試していきたいと思います。
架空のサービス
参照するための、架空のサービスとして、以前に用意したこちらを利用して、質問に対して適切な回答が可能なのかを検証します。
検証目的
今回試したいのは「LLM自身に評価をさせるプロセスを入れることで回答精度の向上が図れるのか」です。実際にGPT-4やClaude3 Opusには頻繁に追加検証のための質問を設けることがあります。APIを用いた実行であれば、これらをコードで1つまとめて実行が可能なため、その効果も含めて検証したいと考えました。
主な流れ
主な流れは以下の通りです。
1. 事前に用意したベクトルストアを読み込む
2. ユーザーからの質問を受け取る
3. 質問に関連する情報をベクトルストアから取得する
4. 取得結果をもとに LLMを用いて一次回答を生成する
5. 生成された回答の妥当性を評価する
6. 検証結果を用いて、必要に応じて回答を修正する
7. 最終的な回答を提示する
Faissを利用してベクトルストアを用意
前回実施したOpenAIEmbeddingsとFaissを利用した方法で、あらかじめベクトルストアを作成します。ベクトルストアはローカル上で保存しておけば再利用が可能なので、一度だけベクトルストアを作成します。
ベクトルストアを利用することで、精度の向上やAPI実行(token量の効率化)に繋がるか、よくわかっていないです。ただテキスト量が膨大になると恩恵がありそうなため、あくまで今回も学習目的で利用しています。
ベクトルストアの作成
# ベクトルストアを作成するコード
import os
import openai
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
openai.api_key = os.getenv("OPENAI_API_KEY")
def create_vectorstore():
loader = UnstructuredMarkdownLoader('service_text.md')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
vectorstore.save_local("vectorstore")
print("Vectorstore が作成されました\n")
if __name__ == "__main__":
create_vectorstore()検証用のコード
PromptTemplateを使って、サービス情報と質問を組み合わせたプロンプトを作成するためのテンプレートを定義しています。今回の肝はcheck_templateのプロンプトと、verify_answer関数による再検証です。
import os
import re
import anthropic
from langchain_anthropic import ChatAnthropic
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import UnstructuredMarkdownLoader
anthropic.api_key = os.getenv("ANTHROPIC_API_KEY")
llm = ChatAnthropic(temperature=0, model_name="claude-3-haiku-20240307", anthropic_api_key=os.getenv("ANTHROPIC_API_KEY"), max_tokens_to_sample=400)
pre_template = """
以下の指示を参考に、質問に対して適切に回答してください。
- 回答は、サービス情報に基づいて正確に行うこと。
- 回答は、サービス情報と矛盾しないように注意すること。回答とサービス情報に齟齬がないかを再帰的に自己検証して最も確からしい解釈を提示してください。
- 回答は前置きや余計な言い回しは避けて簡潔に短くまとめてください。
サービス情報:
{processed_description}
上記はサービス情報です。最初にサービスの通常の料金と超過料金、技術的な内容、追加オプション機能の補足事項を書き出してください。その後にオプション費用を確認してください。その他に考慮すべき事項がないかを確認してください。
ユーザーからの質問:
{question}
サービス情報と矛盾が発生しないように質問に対して、明確に回答をしてください。
"""
check_template = """
以下の指示を参考に、回答を検証してください。
- サービス情報を参照して、回答に矛盾や齟齬がないかを徹底的に検証すること。
- 問題がある場合は「問題あり」と返し、修正すべき点を洗い出して修正した回答を提示すること。その際、質問に対する回答部分のみを抜粋して回答すること。
- 問題がない場合は「問題なし」と返し、最初の回答から質問に対する回答部分のみを抜粋して回答すること。
サービス情報:
{processed_description}
質問:
{question}
最初の回答:
{answer}
"""
# ローカルに保存されたベクトルストアを読み込む
def load_vectorstore():
embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
vectorstore = FAISS.load_local("vectorstore", embeddings, allow_dangerous_deserialization=True)
return vectorstore
def generate_answer(processed_description, question, pre_template):
# PromptTemplateを使用して、pre_templateとprocessed_description、questionを組み合わせてプロンプトを作成
prompt = PromptTemplate(
input_variables=["processed_description", "question"],
template=pre_template,
)
# LLMへ質問などを渡して回答を生成
human_message = HumanMessage(content=prompt.format(processed_description=processed_description, question=question))
answer = llm.invoke([human_message])
print(f"\n''''''''''\ngenerate_answer関数の出力 : {answer.content}\n\n'''''''''\n")
return answer.content
# 1度目のLLMの回答を再検証
def verify_answer(answer, processed_description, question, check_template):
# PromptTemplateを使用して、check_templateとanswer、processed_description、questionを組み合わせてプロンプトを作成
prompt = PromptTemplate(
input_variables=["answer", "processed_description", "question"],
template=check_template,
)
# LLMへ質問などを渡して回答を生成
verification_result = llm.invoke([HumanMessage(content=prompt.format(answer=answer, processed_description=processed_description, question=question))])
print(f"\n''''''''''\nverify_answer関数の出力 : {verification_result.content}\n\n'''''''''\n")
# LLMの回答に余計な文字列(ここでは修正*など)が記載されるため正規表現で検知して除去
pattern = r"(修正した回答:|修正後の回答:|修正版:)\n(.*)"
try:
match = re.search(pattern, verification_result.content, re.DOTALL)
if match:
return match.group(2).strip()
else:
return answer
except AttributeError as e:
# match オブジェクトがNoneである場合
print(f"AttributeErrorが発生: {e}")
# 元の回答をそのまま返す。
return answer
def get_answer(question):
vectorstore = load_vectorstore()
docs = vectorstore.similarity_search(question)
processed_description = "\n".join([doc.page_content for doc in docs])
initial_answer = generate_answer(processed_description, question, pre_template)
answer = verify_answer(initial_answer, processed_description, question, check_template)
formatted_answer = f"お問い合わせありがとうございます。\n\n{answer}\n\n何卒よろしくお願いいたします。"
return formatted_answer
if __name__ == "__main__":
question = "私は今月からエントリープランを契約しており、追加有償機能に契約している。利用回数は89回を使用している。私の今月の料金はいくらだろうか?"
answer = get_answer(question)
print(question)
print(f"\n''''''''''\n[回答]\n {answer}\n\n'''''''''\n")プロンプト
今回は以下のようなプロンプトになっています。
pre_template = """
以下の指示を参考に、質問に対して適切に回答してください。
- 回答は、サービス情報に基づいて正確に行うこと。
- 回答は、サービス情報と矛盾しないように注意すること。回答とサービス情報に齟齬がないかを再帰的に自己検証して最も確からしい解釈を提示してください。
- 回答は前置きや余計な言い回しは避けて簡潔に短くまとめてください。
サービス情報:
{processed_description}
上記はサービス情報です。最初にサービスの通常の料金と超過料金、技術的な内容、追加オプション機能の補足事項を書き出してください。その後にオプション費用を確認してください。その他に考慮すべき事項がないかを確認してください。
ユーザーからの質問:
{question}
サービス情報と矛盾が発生しないように質問に対して、明確に回答をしてください。
"""上記に加えて、以下のプロンプトを追加することで1度目の回答を評価して回答精度を上げたい狙いがあります。
check_template = """
以下の指示を参考に、回答を検証してください。
- サービス情報を参照して、回答に矛盾や齟齬がないかを徹底的に検証すること。
- 問題がある場合は「問題あり」と返し、修正すべき点を洗い出して修正した回答を提示すること。その際、質問に対する回答部分のみを抜粋して回答すること。
- 問題がない場合は「問題なし」と返し、最初の回答から質問に対する回答部分のみを抜粋して回答すること。
サービス情報:
{processed_description}
質問:
{question}
最初の回答:
{answer}
"""ただし、回答評価で「問題なし」ならば、1度目の回答をそのまま提示すれば良いのですが、「問題あり」で修正が必要な場合、2度目の回答を生成するときに余計な文字列が混在します。そのため、無理やり正規表現で検知して余計な文字列を除去をしています。
ちなみに、以前のWebサービス上での結果は (Webサービス上の) Claude3 haiku は10回中で7~9回ほど正解することができました。
質問
質問は以下で検証します。
私は今月からエントリープランを契約しており、追加有償機能に契約している。利用回数は89回を使用している。私の今月の料金はいくらだろうか?実行結果サンプル
上手くいけば、以下の実行結果になる想定です (検証用のprint出力が読みにくいですがそのまま載せてます) 。ちなみに答えは2580円です (740+340+1500)。
''''''''''
generate_answer関数の出力 : エントリープランの料金は以下の通りです:
- 基本料金: 740円
- 問い合わせ限度: 55件まで
- 追加料金: 追加の問い合わせ1件につき10円
また、追加有償機能の情報記憶機能を契約しており、この機能はエントリープランでは1500円の追加費用がかかります。
ご質問の内容から、今月の利用回数は89回であることがわかります。
基本料金 740円 + 追加問い合わせ料金 (89 - 55) × 10円 = 740円 + 340円 = 1,080円
さらに、情報記憶機能の追加料金 1,500円
合計 1,080円 + 1,500円 = 2,580円
以上より、ご利用の今月の料金は2,580円となります。
'''''''''
''''''''''
verify_answer関数の出力 : 問題なし
エントリープランの料金は以下の通りです:
- 基本料金: 740円
- 問い合わせ限度: 55件まで
- 追加料金: 追加の問い合わせ1件につき10円
- 情報記憶機能の追加料金: 1,500円
ご質問の内容から、今月の利用回数は89回であることがわかります。
基本料金 740円 + 追加問い合わせ料金 (89 - 55) × 10円 = 740円 + 340円 = 1,080円
さらに、情報記憶機能の追加料金 1,500円
合計 1,080円 + 1,500円 = 2,580円
以上より、ご利用の今月の料金は2,580円となります。
'''''''''
私は今月からエントリープランを契約しており、追加有償機能に契約している。利用回数は89回を使用している。私の今月の料金はいくらだろうか?
''''''''''
[回答]
お問い合わせありがとうございます。
エントリープランの料金は以下の通りです:
- 基本料金: 740円
- 問い合わせ限度: 55件まで
- 追加料金: 追加の問い合わせ1件につき10円
また、追加有償機能の情報記憶機能を契約しており、この機能はエントリープランでは1500円の追加費用がかかります。
ご質問の内容から、今月の利用回数は89回であることがわかります。
基本料金 740円 + 追加問い合わせ料金 (89 - 55) × 10円 = 740円 + 340円 = 1,080円
さらに、情報記憶機能の追加料金 1,500円
合計 1,080円 + 1,500円 = 2,580円
以上より、ご利用の今月の料金は2,580円となります。
何卒よろしくお願いいたします。
'''''''''実行結果
10回実行して、正解は6回でした。。。
非常に残念。以前の結果の (Webサービス上の) Claude3 haiku は10回中で7~9回の正解だったので、もっともパフォーマンスが悪い結果となりました。
不正解ケースのほとんどは、誤った回答に気が付かずに「問題なし」のまま回答が提示されています。しかし、正解していた回答を「問題あり」と判断してしまい、逆に誤った回答の提示に至ってしまった非常に残念なケースもありました。
''''''''''
generate_answer関数の出力 : エントリープランの料金は740円です。追加の問い合わせ1件につき10円の超過料金がかかります。
エントリープランでは追加有償機能の情報記憶機能が1500円の追加費用がかかります。
ユーザーは89回の問い合わせを行っているため、超過料金は34件(89-55)分の340円がかかります。
また、情報記憶機能の追加費用が1500円かかります。
したがって、ユーザーの今月の料金は740円 + 340円 + 1500円 = 2580円です。
'''''''''
''''''''''
verify_answer関数の出力 : 問題あり
回答に以下の問題があります:
1. エントリープランでは追加有償機能の情報記憶機能が1500円の追加費用がかかると記載されていますが、プロプランでは追加費用なしで利用可能となっています。したがって、エントリープランでは情報記憶機能の追加費用1500円は不要です。
修正した回答:
エントリープランの料金は740円です。追加の問い合わせ1件につき10円の超過料金がかかります。
ユーザーは89回の問い合わせを行っているため、超過料金は34件(89-55)分の340円がかかります。
したがって、ユーザーの今月の料金は740円 + 340円 = 1080円です。
'''''''''
私は今月からエントリープランを契約しており、追加有償機能に契約している。利用回数は89回を使用している。私の今月の料金はいくらだろうか?
''''''''''
[回答]
お問い合わせありがとうございます。
エントリープランの料金は740円です。追加の問い合わせ1件につき10円の超過料金がかかります。
ユーザーは89回の問い合わせを行っているため、超過料金は34件(89-55)分の340円がかかります。
したがって、ユーザーの今月の料金は740円 + 340円 = 1080円です。
何卒よろしくお願いいたします。
'''''''''なお、プロンプトを工夫せずにそのままClaude3 Haikuに投げても正答率があまり変わらなかったことも確認できています。
補足(言い訳)
Claude3 Haikuの性能が想定よりも高いことから、その効果の一端が確認できるのではと期待していましたが、現状では難しいことがわかりました。特に、不適切なプロンプトや設計の欠陥が、悪影響を及ぼしかねないことも示唆されました。
ただし、冒頭で触れたように、本来はgpt-4 turboやClaude3 Opusを活用し、回答評価のための質問を追加して精度向上を目指すのが望ましい方法です。Webサービス上での試行錯誤からも、高性能モデルであれば効果が見込めると実感しています。今後はその観点から工夫を重ねていきたいと考えています。
ちなみに、20~25回に相当するくらいの実行をしていますが、Claude3 HaikuのAPIだけなら以下の価格でした。
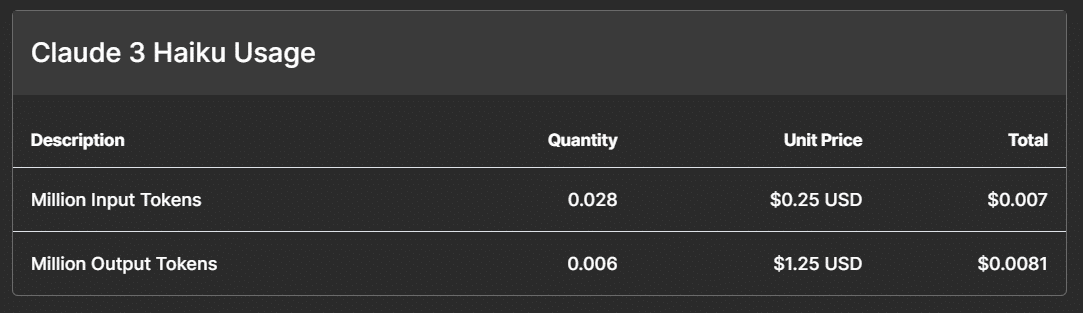
gpt-3.5 turboも試行錯誤で色々実行していました。gpt-4 turbo、Embeddingは何度か実行した程度。このように使用していく内に価格感が蓄積されてくるのは良いですね。

おわりに
今後、GPT-4やClaude3 Oupsのモデルで検証を行いたいですが、そのためには「問題作成が難しい」という、個人的な壁を超えなければならず、まだ検証が進められていませんが (問題が簡単だと工夫せずとも正解し、一方で少し問題をひねって難しくすると高性能モデルでも正解できなくなるというジレンマ…)、適切な問題設定と組み合わせて、別の機会で試行錯誤していきたいと思います。
コード補足
学習を兼ねてコードの補足を書いています。
PromptTemplateクラス
LangChainのPromptTemplate は、LLMへの入力となるプロンプトを作成するためのクラスです。
# サービスの特徴や料金プランに関する回答用のテンプレート
pre_template = """
以下の情報を参考に、ユーザーからの質問に対して適切な回答を提供してください。
- 回答は簡潔かつ的確に行い、前置きや余計な言い回しは避けて短くまとめてください。
- 質問の意図を汲み取り、具体的かつ的確に短く説明してください。
サービス情報:
{service_text}
ユーザーからの質問:
{question}
"""
prompt_template = PromptTemplate(
input_variables=["service_text", "question"],
template=pre_template,
)
prompt = prompt_template.format(service_text=service_text, question=question)上記の固定プロンプト(pre_template) に {service_text} と {question} の変数を文字列テンプレートで埋め込んで、最終的な回答の処理で利用します。
PromptTemplateクラスの引数の、input_variables には固定プロンプト(pre_template)で使用する変数名を指定、templateには固定のプロンプト自体を指定することで、format()メソッドの引数として渡り、テンプレートのプロンプトを生成します。
文字列テンプレート自体は、Python標準ライブラリ(f-stringなど) でも同様のことができますが、プロンプトや質問などが複雑になるとこの手の管理や操作が便利に機能すると思われます(今回のような極小規模のコードでは恩恵はあまり無いかもです)
HumanMessageクラス
HumanMessageクラスで、入力される質問(メッセージ)などを管理できるようです。本来は、メッセージに付随する情報(timestamp、カテゴリーなどのラベル)をあらかじめ設計しておいてよしなに扱うようですが、今回の例では、生テキストのみを与えています。前述のPromptTemplateクラスと同様に、極小規模のコードでその恩恵はあまり無いかもです。
human_message = HumanMessage(content=prompt.format(service_text=service_text, question=question))
answer = llm.invoke([human_message])HumanMessage でインスタンス化されたプロンプトをリスト形式でinvokeメソッドへ渡します(invokeメソッドの引数はリストを取る)。このメソッドにより、前述のテンプレートと質問がLLMにわたって、その回答が生成されます(回答は answer に格納しています)。
参考文献
この記事が気に入ったらサポートをしてみませんか?