
短単位自動解析用辞書を作る(5)

設定ファイルの準備
いよいよ解析用辞書の学習フェーズです。『MeCab』用の辞書の学習にはseed として以下の設定ファイルが必要です。
dicrc
char.def
*.csv (語彙ファイル)
unk.def
rewrite.def
feature.def
今回の目的は最新版『UniDic』の軽量化と設定ファイルの不備の修正なので、『unidic-csj-202302_full』のものを修正して使いました。
dicrc は、ほぼ別モノに差し替えていますが、主な変更点は下記の通り。
eval-size が 12 になっていたので 10 に修正
基本10素性で一意識別できますし、逆にできないものはできないものについて今回の Gold アノテーション(『UniDic』の自動解析結果)から細かく学習するのもやりすぎと、Hidden に学習されることを願った
eval-size から削ったのは orthBase(書字形基本形)と pronBase(発音形基本形)のカラム
verbose 出力の復活(-Overbose)。タブ区切り出力(-Ounidic, -Ochamame)の排除
char.def は『UniDic』から変更なしで使います。ちなみに最新の ver. 202302では、
KATAKANA 1 1 3 #20221130change Length 2->3/ogisoという変更が入っており、グルーピングをONしつつ、3文字までのカタカナ文字列も未知語ノードに加えます(元は2文字)。
語彙ファイル lex.csv は、
エントリ「アルミホイル」「アルミサッシ」「デフレスパイラル」の削除
を行なっています。また left-id, right-id, 生起コストのカラムは 0,0,0 に初期化しておきます。
unk.def は『UniDic』のものをそのまま使用しています。lex.csv と同じく left-id, right-id, 生起コストのカラムは 0,0,0 に初期化しておきます。
rewrite.def は、
[left rewrite] と [right rewrite]が逆なので修正。
BOS/EOS の書き換えルールが dicrc の bos-feature にマッチしないので当該行の * の個数修正
feature.def は『UniDic』のものをそのまま使用します。性能に関わるところではありませんが、コロン「:」が抜けていたところに ver. 202302 では修正が入っていました。
『unidic-csj-202302_full』には、CRF の学習済みモデルファイル model.def が同梱されており、モデルの追加学習(『MeCab』用語で「再学習」)もできます。ですが今回そのモデルファイルは捨て、0 からモデルを学習させます。これは『MeCab』の再学習の性質に起因します。(再学習の手法に関してはリンク先論文の footnote 2を参照)
再学習は, 現在のパラメータをできるだけ変更せずに新しい学習データにできるだけ適応するような学習が行われます. 適応先のコーパスの性質が元のコーパスのそれと大きく変わる場合は、元の学習データに対する精度が低下する恐れがあります. ご了承下さい
簡単に言えば、『UniDic』に同梱の model.def は学習が完了していて、再学習してもパラメータが大きく動いてくれないのです。感覚としては学習が7割か8割のところで止まっているほうが、性能を上げつつパラメータを連接表圧縮に向けた方向に動かす余地があります。
学習
モデルの学習の流れを図にしました。(参考:『MeCab』の学習手順)
ややこしいので解説していきます。
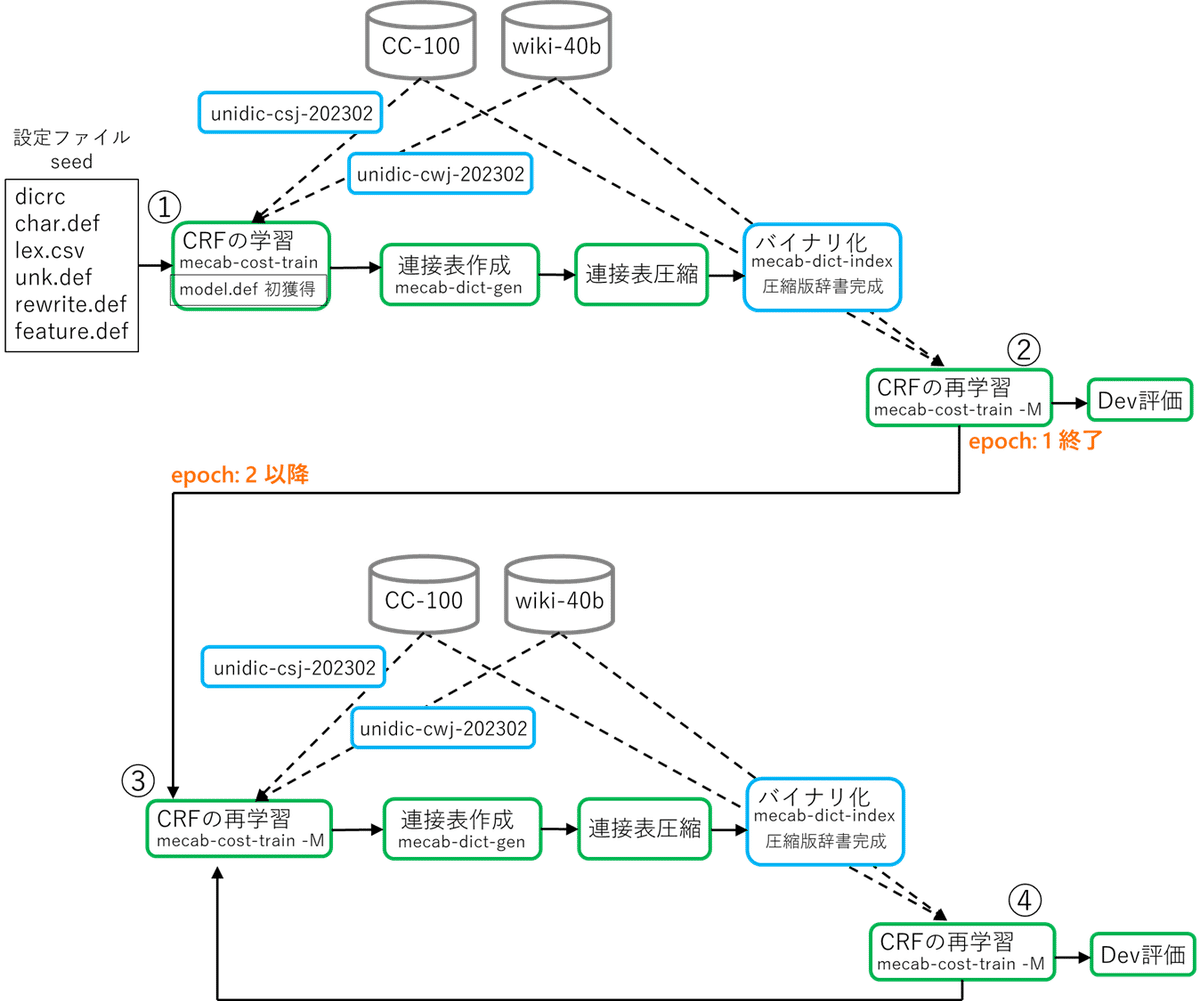
まずは用意した設定ファイル(seed)を基に、
『unidic-csj-202302』で短単位自動アノテーションした『CC-100』と、『unidic-cwj-202302』で短単位自動アノテーションした『wiki-40b』で
CRF の学習(mecab-cost-train)を行ないます。(図1 中の①)
『MeCab』の学習には大体10~20万文あればよく、今回用意した『CC-100』『wiki-40b』ではオーバーサイズ、かつ『MeCab』の CRF はバッチ学習なのでメモリにも乗りません。なのでそれぞれ10万文ずつ切り出します。合わせて20万文です。
正則化のハイパーパラメータ C = 1.0(その他の学習時ハイパーパラメータは以降を含めすべてデフォルト)
小ネタですが、『UniDic』の ver. 2.0 くらいまでは『MeCab』の元論文準拠で C=1.2 を使用していました。ただしこれは IPA辞書向けにハイパラ探索した結果の値であり、コーパス整備に向けて新しい『UniDic』作るたびにハイパラ探索するのも大変なので、ver. 2.1くらいからデフォルトの 1.0 で統一しました。
今回2種類の『UniDic』の解析結果を混ぜて使っていますが、以前説明したようにこれは学習を遅らせるためです。『UniDic』(線形CRF)の解析結果を同じ『UniDic』(線形CRF)の設定ファイルで学習すると、学習に困難がなく、すぐ模倣して(同じ結果を出せるように)収束してしまうのです。
学習が終わった後は、mecab-dict-gen で連接表を作成し、第3回で説明したleft-id と right-id をクラスタリングして、連接表の圧縮をします。
クラスタリングには Repeated Bisection を使っています。よくわからないものを使うより、単に使い慣れたツールを使っているだけです。
実験的に、
・left-id: 1/3, right-id: 1/3, matrix: 1/10
・left-id: 1/10, right-id: 1/10, matrix: 1/100
の 2 種を試しています。
圧縮した連接表で辞書をバイナリ化(mecab-dict-index)すれば epoch: 1 の圧縮版辞書完成です。
圧縮辞書を使って先ほど使った『CC-100』10万文と『wiki-40b』10万文を自動解析し、得たばかりの model.def を再学習します。(図1 中の②④)
ここでも正則化のハイパラ C=1.0 にしました。
これで「連接表が圧縮される」ことが間接的に学習プロセスに組み込まれます。
以上で epoch: 1 終了です。
epoch 2 以降は毎回『CC-100』と『wiki-40b』から新たに別の10万文を選んでくるとこから始まります。同じテキストデータを使いまわしていると、解析結果をすぐに覚えて、これもまた再学習で大きなパラメータ更新が起きなくなります。
これを再び今回の gold アノテーションである『unidic-c.j-202302』で自動解析し、学習に使います。(図1 中の③)
ここでの学習は epoch: 1 の最後で更新された model.def の再学習で、圧縮方向に向いたパラメータを gold 方向へと引き戻す効果を狙っています。
ここでも正則化のハイパラ C=1.0 です。
以下、繰り返しです。
学習時に使用したスクリプトをこちらに置きました。
図1 全体を担っているのが train.py です。
(参考程度に置いているハードコーディングなので、git clone してもそのままでは動かないのでご注意を)
内部で
・matrix.def をクラスタリングのためにベクトルに変換するスクリプト、
・クラスタリング結果から matrix を再構築するスクリプト
を呼んでいます。
Dev データでの評価
各 epoch での圧縮状態の辞書の性能を Dev 用に学習には使わず横に避けておいた『CC-100』と『wiki-40b』の Gold アノテーション(『UniDic』解析結果)で測り、解析性能の F1 値を折れ線にしました。
縦軸が F1 値。横軸が epoch です。青い線が Dev データとして『wiki-40b』のみを使って評価した場合。オレンジの線がDev データ として『CC-100』のみを使って評価した場合。緑が 2つの Dev データを混ぜて評価した場合です。
形態素解析器の評価方法についてはこちらを参照。評価には『MevAL』を使っています。
まずは right-id のサイズを 1/10 、left-id のサイズを1/10 で matrix サイズを1/100 にした結果。

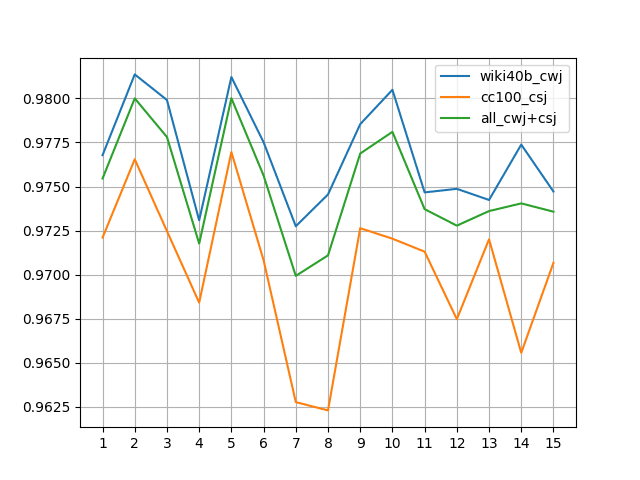


次に right-id のサイズを 1/3 、left-id のサイズを1/3 で matrix サイズを1/10 にした結果。




後者の方が顕著ですが、性能は右肩下がりです。これはハイパーパラメータC を ①②③④のすべての学習時に 1.0 で固定したため epoch: 1 の①で学習がほとんど終わっているからです。Gold の学習がすぐに終わってしまっていて、圧縮方向にばかり学習している結果です。またwiki40-bの方が1文(1行)の長さが長いため、優勢な結果になっています。
解決手段は簡単で、C の値を小さくして、epoch: 1 で学習しきらないように感覚 7~8割で学習を止めて、続く再学習時の C も低い値でパラメータ更新を遅らせます。
ハイパラ設定で言うなら、最初の学習時のみ C=0.1(①)、連接表圧縮再学習では C=0.01(②④)、それを整える Gold 再学習時は C=0.005(③) に設定しました。
また『wiki40-b』の学習を弱くするため、『wiki40-b』だけ10万文を5万文に変更しました。
その結果がこちら(↓)。
まずは right-id のサイズを 1/10 、left-id のサイズを1/10 で matrix サイズを1/100 にした結果。
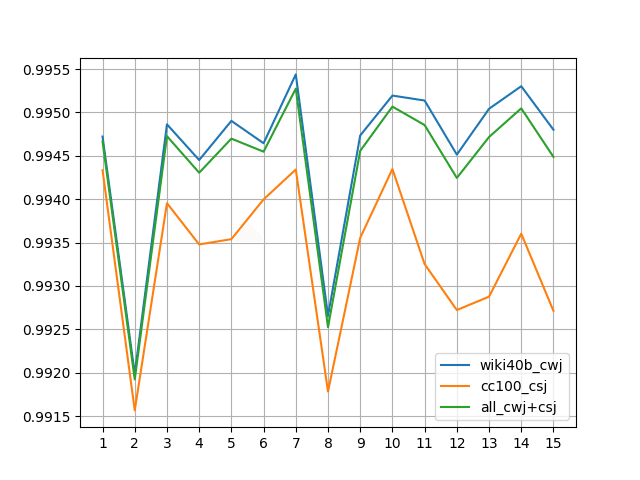



次に right-id のサイズを 1/3 、left-id のサイズを 1/3 で matrix サイズを1/10 にした結果。(F1値)。




先ほどより安定しました。縦軸のスケールが揃っていないことに注意してください。青とオレンジで折れ線のカタチが似ている箇所があるのは双方で共通に出現する単語を積極的に修正している影響です。
短単位自動解析用辞書『suwad-1.0』はこのハイパラ C を調整した matrix サイズ 1/100 版の epoch: 7 の結果で公開しています。
『suwad-1.0』を人手アノテーションの『BCCWJ』を使って解析性能評価した結果がこちら。unidic-cwj-3.1.1 の参考性能がこちらなので、評価に使用しているテキストサイズの差を考えると大体同じくらいの性能が実現できています。
注目ポイントは今回、『BCCWJ』を学習時に直接的には一切使用していないのに、『BCCWJ』の解析性能が悪化していないという点です。