
短単位自動解析用辞書を作る(3)

連接表を圧縮する(その2)
前回書いた圧縮法で、『UniDic』の matrix.def は、
21,202x18,859 (5.9GB) → 18,157x15,572 (4.2GB)
と、約70%のサイズに圧縮できました。
ただ、これでもまだサイズが大きいので、さらに小さくしてきます。
前回の圧縮方法は、
まず matrix.def の行を成す right-id に着目し、列を成す left-id をインデックスとした連接コストのベクトルとみたとき、同一のベクトルを持つ right-id を 1 つにまとめ上げる。
その後、列を成す left-id に着目し、行を成す right-id をインデックスとした連接コストのベクトルとみたとき、同一のベクトルを持つ left-id を 1 つにまとめ上げる。
これによって解析精度に影響を与えないまま、matrix.def の圧縮を実現していました。
今回も単純のために次のようなごくごく小さい matrix.def、right-id.def、left-id.def で説明していきます。
今回も例なので、品詞とその連接コストは深く考えずに適当に書いています。
$ cat right-id.def
0 BOS/EOS
1 名詞
2 動詞
3 形容詞
$ cat left-id.def
0 BOS/EOS
1 名詞
2 動詞
3 形容詞
$ cat matrix.def
4 4
0 0 0
0 1 1.0
0 2 0
0 3 1.1
1 0 1.0
1 1 0
1 2 1.0
1 3 0
2 0 0.9
2 1 1.1
2 2 1.0
2 3 1.0
3 0 1.0
3 1 1.1
3 2 1.0
3 3 0.9この matrix.def を図にすると以下のようになります。
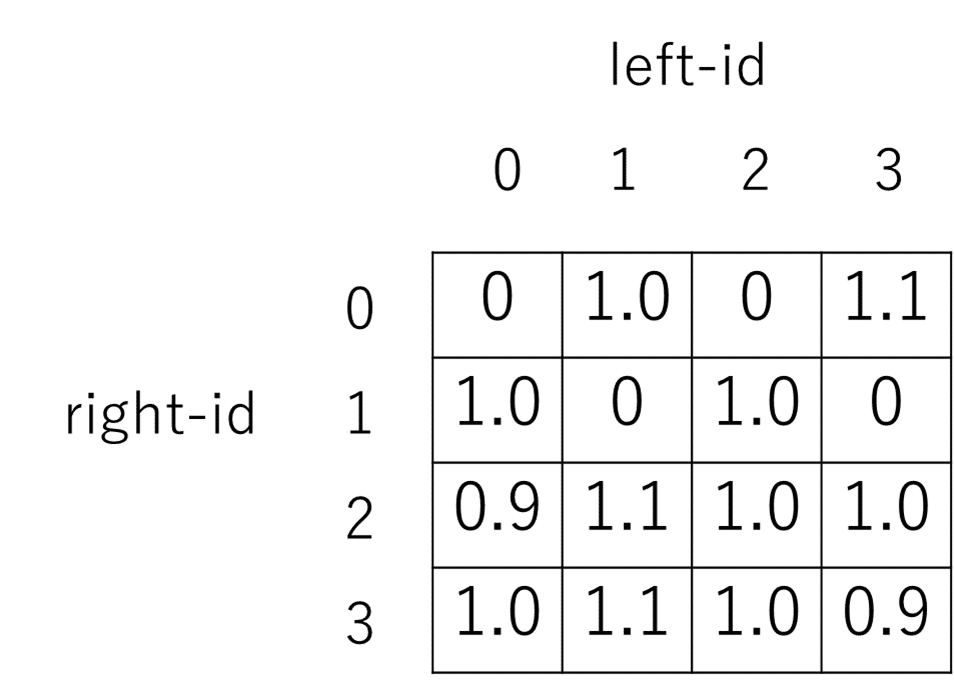
right-id から見ても、left-id から見ても完全に値が一致するベクトルは見つけられないため、前回の方法ではこれ以上圧縮できません。
しかしよく見ると、right-id から見た時、right-id=2 のベクトルと right-id=3 のベクトルはよく似ているので、まとめあげてもいいかもしれません。

left-id から見ると、こちらは left-id=0 のベクトルと left-id=2 のベクトル、 left-id=1 のベクトルと left-id=3 のベクトルがよく似ているので、これらもまとめあげてもいいかもしれません。

これを
right-id から見たベクトルのクラスタリング、
left-id から見たベクトルのクラスタリング
で、それぞれ置き換えます。クラスタリングにもいろいろありますが、今回は使い慣れたもので RepeatedBisection を使いました。
(一般的な k-means の方が、とか言われるかもしれませんが、個人的にはこっちを普段からよく使ってるので使いました)
(また、行列計算による圧縮は、もとの right-id、left-id との対応が保持できないので早々に却下しました )
あとはクラスタ数をもとの right-id 数の 1/10、left-id 数の 1/10 で指定して実行すれば、各 id との対応を保ったまま、matrix.def を 1/100 のサイズに圧縮できます。
まとめ上げた後の行ベクトル、列ベクトルの値は、クラスタ内の id で最も若い id のものを使用しました。
(クラスタ内平均をとる・セントロイドを使うことも考えましたが、各クラスタの挙動が既存の id の挙動のいずれかに集約された方が、コントロールしやすかったからです)

上記のクラスタリングを実行した結果、matrix.def は 1,886x2,121 まで圧縮出来ました。
ただし、何も考えずに連接行列中の近しい行、列をまとめ上げただけなので、当然この連接表を使った解析性能は圧縮前より落ちます。わざわざケースバイケースで分離できるように細かく作ってある表を無理やりまとめこめば、圧縮前は分離できていたケースとケースの解析がどちらかに倒れてしまうので当然です。
なので、この連接表を 1/100 に圧縮した状態でも解析性能が落ちないように、モデルの再学習(追加学習)を行います。
『MeCab』の学習機能には matrix.def のサイズを最小化する最適化はありません。しかし圧縮した状態の連接表を使って生テキストを自動解析した結果で連接表圧縮前のモデルを再学習すれば、mecab-dict-gen した後の連接表が小さくなるプロセスを学習に組み込めます。
1)Goldのアノテーションで『MeCab』の学習プロセスを一度走らせる
2)→連接表をクラスタリングで圧縮する
3)→圧縮した連接表で生テキストを解析しその解析結果でモデルの再学習をする
4)→Goldのアノテーションでモデルの再学習をし、モデルを整える
以下、2)~4)の繰り返し。
1)と3)、4)と3)で使うテキストは同じが良さそうですし、過学習を避けるために、1)と毎回の4)は全部違うデータを使った方がよさそうです。そうして、
Goldアノテーションで初期値を学習→圧縮アノテーションでモデル内の差異がある部分をだけ捻じ曲げる→新しいGoldアノテーションで学習して整える→圧縮アノテーションでモデル内の差異がある部分をだけ捻じ曲げる→……
この繰り返しで、学習後に連接表を圧縮しても解析性能が落ちないモデルが獲得できると期待できます。
(downstream タスクに連接表の圧縮を設定、downstream タスクの学習とメインの日本語形態素解析の学習を miniバッチで交互に行なっているようなものです)
しかし、問題が残ります。
手元に、『UniDic』の学習で使われたデータがない。
次回はその解決についてのお話をします。
この記事が気に入ったらサポートをしてみませんか?