Yuri2Vecを作った話

この記事は百合 Advent Calendar 2020の6日目の記事です。
Yuri2Vecと言いつつベクトルではないです。
なんでこんなものを作ったのか
百合は好きだけれどもあんまり思い入れが強いわけでもないため作品紹介などができそうになかったので、ものづくり方面に持ってった結果こんなもの作ることになりました。
概要&仕組み
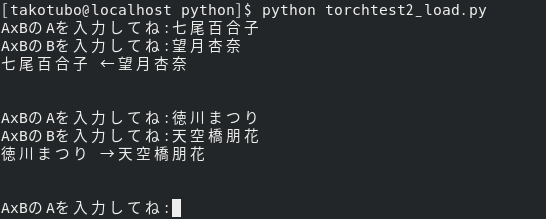
上の画像の感じに名前を2つ入力すると矢印で受け攻めを示してくれます。
基本的に学習結果が勝手に出しているだけですが、使ったデータ的にアイドルマスターミリオンライブ シアターデイズ内50人のアイドル分は私の意思が反映されています。その範囲に文句があればTwitterでどうぞ、返り討ちにします。
仕組みとしては
1. 名前をword2vecを使ってベクトル化
2. 学習済みモデルに入力して値を出す
3. 値を参考に矢印の向きを決める
という感じ
遊び方
GitHubページからソース類をダウンロード
Readmeに従ってword2vecモデルの作成後、実行
実行環境は書いてる通りか下の環境に合わせれば動くはずです
本当はword2vecのファイルも含めたかったけどできなかったので何かしらの方法が見つかればそのうち追記します
開発環境&ライブラリ
・CentOS8
・Python3.8
・gensim3.8.3
・mecab-python3 1.0.3
・pandas1.1.4
・pytorch1.7.0
・wikiextractor0.1
・word2vec0.11.1
その他あったかもしれないけど忘れました
やったこと
注意 : ここからソースコードが出てきますが適当に作ったのでめちゃくちゃ汚いです。優しい目で見てやってください。
まず最初にword2vecのモデルを用意しました。
word2vecは言葉をベクトルに変換して言葉の類似性とか属性とかをわかりやすく出してくれる便利な奴のことです。
今回は言葉の方向性とか属性とかを出すのに使ったことになってるはずです。
word2vecのモデルは適当なサイトを参考にwikipediaのデータを学習させて作るやつでやりました。
そのモデルを使って学習用データの作成するのが以下のプログラム
import pandas as pd
from gensim.models import KeyedVectors as kv
wv = kv.load_word2vec_format("wiki.vec.pt", binary=True)
df = pd.read_csv("marged_data.csv")
data = [[]]
for index, row in df.iterrows():
vec1 = wv[row[1][0]]
for i in range(1, len(row[1])):
vec1 = vec1 + wv[row[1][i]]
vec1 = vec1.tolist()
vec2 = wv[row[2][0]]
for i in range(1, len(row[2])):
vec2 = vec2 + wv[row[2][i]]
vec2 = vec2.tolist()
vec = list(vec1)
vec.extend(vec2)
vec.append(row[3])
data.append(vec)
vec = list(vec2)
vec.extend(vec1)
vec.append(1 if row[3] == 0 else 0)
data.append(vec)
del data[0]
result = pd.DataFrame(data)
result.to_csv("train_data.csv", index=False)「名前, 名前, 0か1」のデータを「200次元ベクトルx2, 0か1」のデータに変換しています。0か1はそのカプの受け攻めの向きを表しています。
次にやったのがYuri2Vecの本体のモデル作成
機械学習なんか知ったこっちゃない状態から始めたためいろんなサイトの切り貼りして、入出力確認してを繰り返してどうにか作りました。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import pandas as pd
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.fc1 = nn.Linear(200*2, 1000)
self.fc2 = nn.Linear(1000,1)
def forward(self, x):
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return x
class YuriData(Dataset):
def __init__(self, csv_path):
df = pd.read_csv(csv_path)
data = df.iloc[:, :-1].values
labels = df.iloc[:, -1]
self.data = data
self.labels = labels
def __getitem__(self, index):
return self.data[index], self.labels[index]
def __len__(self):
return len(self.data)
dataset = YuriData('train_data.csv')
dataloader = DataLoader(dataset, batch_size=len(dataset), shuffle=True)
for x_batch, y_batch in dataloader:
print(x_batch.shape, y_batch.shape)
model = Model()
optimizer = optim.Adam(params=model.parameters(), lr=0.001)
criterion = nn.MSELoss()
epoch = input("epoch:")
epoch = int(epoch)
for e in range(epoch):
for i ,(data, target) in enumerate(dataloader):
optimizer.zero_grad()
output = model(data.float())
target = target.view(-1,1)
loss = criterion(output, target.type(torch.float32))
loss.backward()
optimizer.step()
print(loss)
torch.save(model.state_dict(), 'weight.pth')
モデルは入力400、中間層1000、出力1と適当な形にしました。
最終的に動かすのが以下のコード
wv = kv.load_word2vec_format("wiki.vec.pt", binary=True)
model = Model()
param = torch.load('weight.pth')
model.load_state_dict(param)
while True:
name1 = input("AxBのAを入力してね:")
name2 = input("AxBのBを入力してね:")
vec1 = wv[name1[0]]
for i in range(1, len(name1)):
vec1 = vec1 + wv[name1[i]]
vec1 = vec1.tolist()
vec2 = wv[name2[0]]
for i in range(1, len(name2)):
vec2 = vec2 + wv[name2[i]]
vec2 = vec2.tolist()
vec = list(vec1)
vec.extend(vec2)
arr1 = np.array(vec)
vec = list(vec2)
vec.extend(vec1)
arr2 = np.array(vec)
data1 = torch.from_numpy(arr1.astype(np.float32)).clone()
data2 = torch.from_numpy(arr2.astype(np.float32)).clone()
out1 = model(data1)
out2 = model(data2)
yuri_vec = '→' if out1.item() > out2.item() else '←'
print(name1 + " " + yuri_vec + " " + name2 + "\n\n")入力をモデルに突っ込んで出力から矢印を決めています。
本当は閾値で分けようと思ったけれどうまくいかなかったので、名前の順を入れ替えた値と比較して値の大きい向きを採用する形に。
そうして完成したものが最初上の方にあるやつです。
作った感想とか
pytorchもword2vecもそもそもpythonすら初心者だったのでめちゃくちゃ苦労しました。なので多分機械学習部分はあんまりいい出来にはなってない気がします。とりあえず入力データにだけは適合させるために過学習上等でぶん回したので有識者には怒られるかもしれないなって感じです。
参考文献
この記事が気に入ったらサポートをしてみませんか?