コロナによる日経平均株価への影響を感情分析により予測してみた

・はじめに
初めまして、製薬業界に勤めているCeuticalと申します。
Aidemy Premiumにて「データ分析コース」を3ヶ月受講いたしました。
Aidemy Premiumを受講しようと思ったきっかけは、近年、AI、機械学習、ビックデータ等に関するワードを耳にするようになり、製薬業界でも取り入れていく流れになってきているためです。
このコースを通して基礎基本を学び、今後の仕事に生かしていきたいと思っております。
初心者であるため、間違っている箇所も多々あるかと思いますが、下記にて実装した内容を記載しております。
・実行環境
Jupyter Notebook
Python 3.7.3
・用語について
形態素解析・・・自然言語処理の一部で、自然言語で書かれた文を言語上で意味を持つ最小単位(形態素)に分け、それぞれの品詞や変化などを判別することです。日本語を形態素解析する場合、MeCabやjanome等が用いられます。今回は、MeCabを用いて形態素解析を行なっていきます。
ロジスティック回帰・・・そもそも「回帰分析」とは、蓄積されたデータをもとに、y = ax + b といった式に落とし込むための統計手法です。そして「ロジスティック回帰」は、 いくつかの要因(説明変数)から「2値の結果(目的変数)」が起こる確率を説明・予測することができる統計手法です。結果が将来「起きる」「起きない」のどちらかを予測したいときに使われる手法です。今回は、株価が上がるか下がるかを判断すためにこちらの手法を用いて行います。
・流れ
*まず初めに各国の製薬会社のデータを取得し、グラフ化してコロナによる株価の変動を確認します。参考程度です。
(1)Twitterからツイートを取得する。
(2)ツイートの形態素解析及び印象の評価等の感情分析を行い、可視化する。
(3)日経平均株価のデータを取得し、データの整理をする。
(4)株価の予測を行う。
*各国の製薬会社の株価を確認する
pandasを用いて、yahooから各々のデータを取得する。
各データの詳細
RHHBY:エフ・ホフマン・ラ・ロシュ(スイス)
TAK:武田薬品工業(日本)
ABBV:アッビィ(アメリカ)
GSK:グラクソ・スミスクライン(イギリス)
import pandas as pd
import pandas_datareader.data as web
ticker_symbols=['RHHBY', 'TAK', 'ABBV', 'GSK']
startdate='2019-01-01'
today=datetime.today().strftime('%Y-%m-%d')
def getMystock(stocks=ticker_symbols, start=startdate, end=today, col='Adj Close'):
data = web.DataReader(stocks, data_source='yahoo', start=start, end=end)[col]
return data
my_stock = getMystock()
df = pd.DataFrame(my_stock).dropna()
df結果
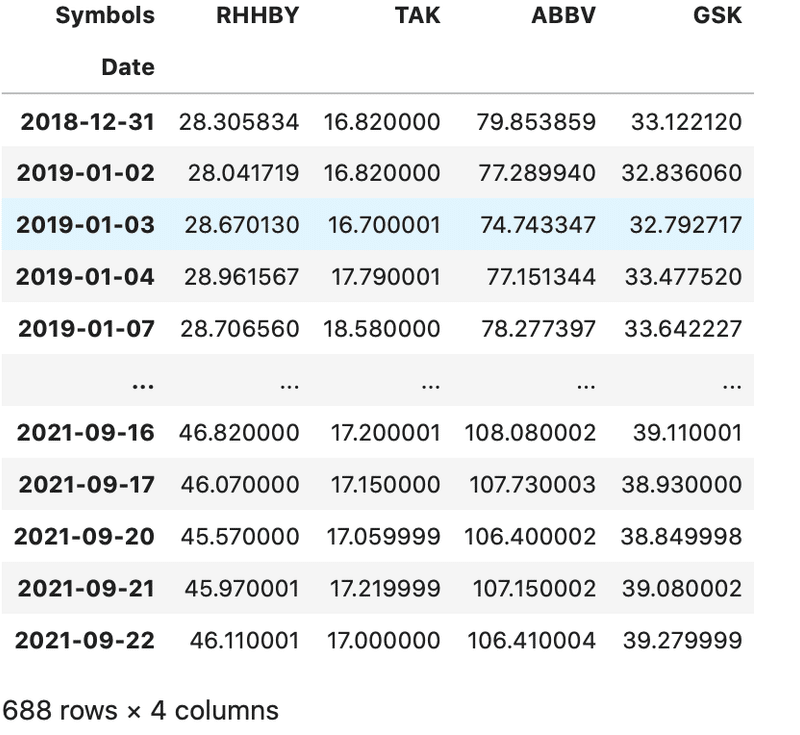
sklearn MinMaxScakerを用いて、各々のデータを比較できるように正則化を行う。
from sklearn.preprocessing import MinMaxScaler
stock_R = df.drop(['TAK', 'ABBV', 'GSK'], axis=1)
stock_T = df.drop(['RHHBY', 'ABBV', 'GSK'], axis=1)
stock_A = df.drop(['RHHBY', 'TAK', 'GSK'], axis=1)
stock_G = df.drop(['RHHBY', 'TAK', 'ABBV'], axis=1)
scaler = MinMaxScaler([0, 1])
scaler.fit(stock_R)
stock_R_Scaler = scaler.transform(stock_R)
scaler.fit(stock_T)
stock_T_Scaler = scaler.transform(stock_T)
scaler.fit(stock_A)
stock_A_Scaler = scaler.transform(stock_A)
scaler.fit(stock_G)
stock_G_Scaler = scaler.transform(stock_G)matplotlibを用いて、各のデータをグラフ化した。
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(18, 8))
plt.title('Adj Close Price History')
plt.plot(stock_R_Scaler, label=ticker_symbols[0])
plt.plot(stock_T_Scaler, label=ticker_symbols[1])
plt.plot(stock_A_Scaler, label=ticker_symbols[2])
plt.plot(stock_G_Scaler, label=ticker_symbols[3])
plt.xlabel('time(day)', fontsize=16)
plt.ylabel('Adj Close Price', fontsize=16)
plt.legend(loc='upper left')
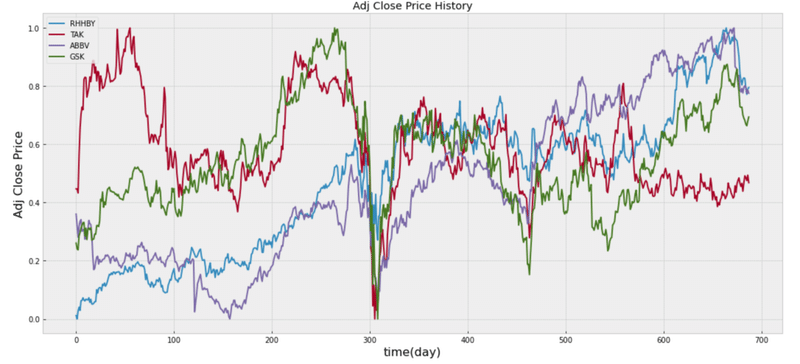
plt.show()結果
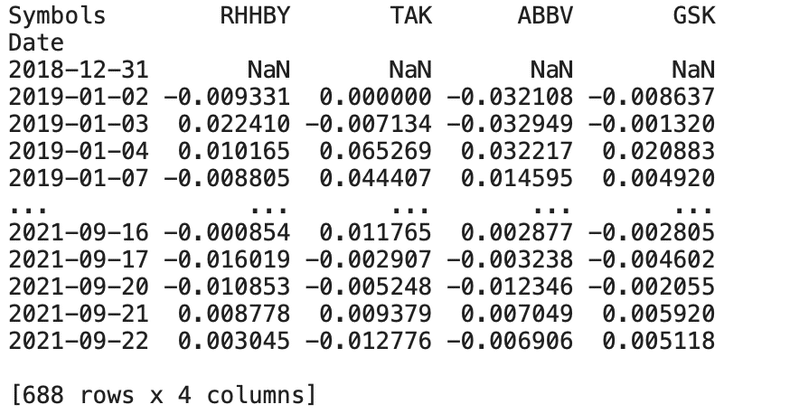
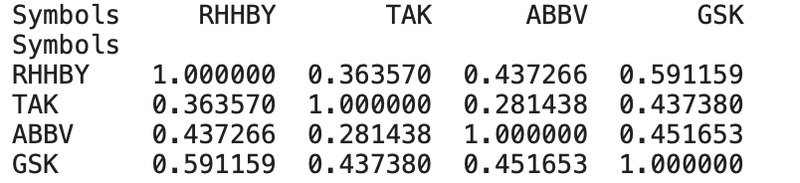
各々のデータの関係性を調べるため、相関行列、1日の変化率、共分散、標準偏差を確認してみます。
daily_rate_change = (df.pct_change(1))
print(daily_rate_change)
print(daily_rate_change.corr())
print(daily_rate_change.cov())
print(daily_rate_change.std())1日の変化率
相関行列
共分散
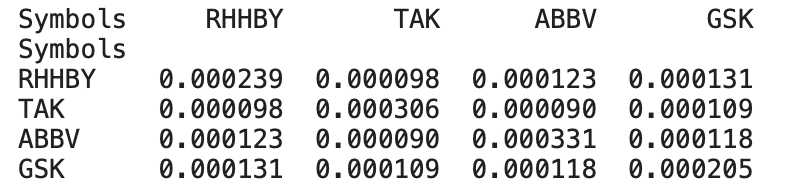
標準偏差

上記のデータから、各国の大手製薬会社全ての株価が一時期下がっていることが確認できる。しかし、徐々に回復していき、国外の製薬会社はコロナの影響は受けているもののコロナ前の株価より高くなっている企業も存在している。国内の医薬品市場ではコロナによって株価が下がってからなかなか上がらないことが確認できる。
今回は各国の製薬業界の数社に焦点を当ててコロナの影響を確認したが、国内全体にどのような影響を与えたかを日経平均株価で確認し、感情分析を用いて株価の予測を行なっていきます。
(1)Twitterからツイートを取得する。
Twitter APIを用いて、ツイートを取得し、コロナが始まる年の2019年1月1日からのツイートをcsvファイルに保存します。
#特定のアカウントからツイート取得
import tweepy
import csv
consumer_key = '' # Consumer Keyを記載してください
consumer_secret = '' # Consumer Secretを記載してください
access_token = '' # Access Tokenを記載してください
access_secret = '' # Accesss Token Secertを記載してください
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
#ツイート取得
tweet_data = []
tweets = tweepy.Cursor(api.user_timeline,screen_name = "@",exclude_replies = True)
for tweet in tweets.items():
tweet_data.append([tweet.id,tweet.created_at,tweet.text.replace('\n',''),tweet.favorite_count,tweet.retweet_count])
# tweets_corona.csvという名前で保存してください。
with open('./tweets_cov.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["id", "text", "created_at", "fav", "RT"])
writer.writerows(tweet_data)
df = pd.read_csv('./tweets_cov.csv')
df = df.loc[:986]
df.to_csv("./tweets_cov_new.csv", index=False)(2)ツイートの形態素解析及び印象の評価等の感情分析を行い、可視化する。
極性辞書として単語感情極性対応表を用いるため、極性辞書のダウンロードを行います。
# 岩波国語辞書のダウンロード
import urllib.request
import zipfile
# URLを指定
url = "https://storage.googleapis.com/tutor-contents-dataset/6050_stock_price_prediction_data.zip"
save_name = url.split('/')[-1]
# ダウンロードする
mem = urllib.request.urlopen(url).read()
# ファイルへ保存
with open(save_name, mode='wb') as f:
f.write(mem)
# zipファイルをカレントディレクトリに展開する
zfile = zipfile.ZipFile(save_name)
zfile.extractall('.')次に、Mecabを用いて、形態素解析を行い、pn値の平均を求めます。
#感情分析
import MeCab
import re
# MeCabインスタンスの作成
m = MeCab.Tagger('')
# テキストを形態素解析し辞書のリストを返す関数
def get_diclist(text):
parsed = m.parse(text)
lines = parsed.split('\n')
lines = lines[0:-2]
diclist = []
for word in lines:
l = re.split('\t|,',word)
d = {'Surface':l[0], 'POS1':l[1], 'POS2':l[2], 'BaseForm':l[3]}
diclist.append(d)
return(diclist)
# 形態素解析結果の単語ごとのdictデータにPN値を追加する関数
def add_pnvalue(diclist_old, pn_dict):
diclist_new = []
for word in diclist_old:
base = word['BaseForm']
if base in pn_dict:
pn = float(pn_dict[base])
else:
pn = 'notfound'
word['PN'] = pn
diclist_new.append(word)
return(diclist_new)
# 各ツイートのPN平均値を求める
def get_mean(dictlist):
pn_list = []
for word in dictlist:
pn = word['PN']
if pn!='notfound':
pn_list.append(pn)
if len(pn_list)>0:
pnmean = np.mean(pn_list)
else:
pnmean=0
return pnmean取得したツイートデータと辞書を読み込み、ツイートごとの平均値を求め、matplotlibを用いてグラフ化します。
import matplotlib.pyplot as plt
%matplotlib inline
import pandas as pd
import numpy as np
# 取得したツイートの読み込み
df_tweets = pd.read_csv('./tweets_cov_new.csv', names=['id', 'date', 'text', 'fav', 'RT'], index_col='date')
df_tweets = df_tweets.drop('text', axis=0)
df_tweets.index = pd.to_datetime(df_tweets.index)
df_tweets = df_tweets[['text']].sort_index(ascending=True)
# 岩波国語辞書の読み込み
pn_df = pd.read_csv('./6050_stock_price_prediction_data/pn_ja.csv', encoding='utf-8', names=('Word','Reading','POS', 'PN')) #word_listにリスト型でWordを格納してください 。
word_list = list(pn_df['Word']) #pn_listにリスト型でPNを格納してください 。
pn_list = list(pn_df['PN']) #pn_dictとしてword_list , pn_listを格納した辞書を作成してください。
pn_dict = dict(zip(word_list, pn_list))
# means_listという空のリストを作りそこにツイートごとの平均値を求める
means_list = []
for tweet in df_tweets['text']:
dl_old = get_diclist(tweet)
dl_new = add_pnvalue(dl_old, pn_dict)
pnmean = get_mean(dl_new)
means_list.append(pnmean)
df_tweets['pn'] = means_list
df_tweets = df_tweets.resample('D').mean()
# 日付をx軸PN値をy軸にしてプロット
x = df_tweets.index
y = df_tweets.pn
plt.plot(x,y)
plt.grid(True)
# df_tweets_cov.csvという名前でdf_tweetsを出力
df_tweets.to_csv('./df_tweets_cov.csv')結果
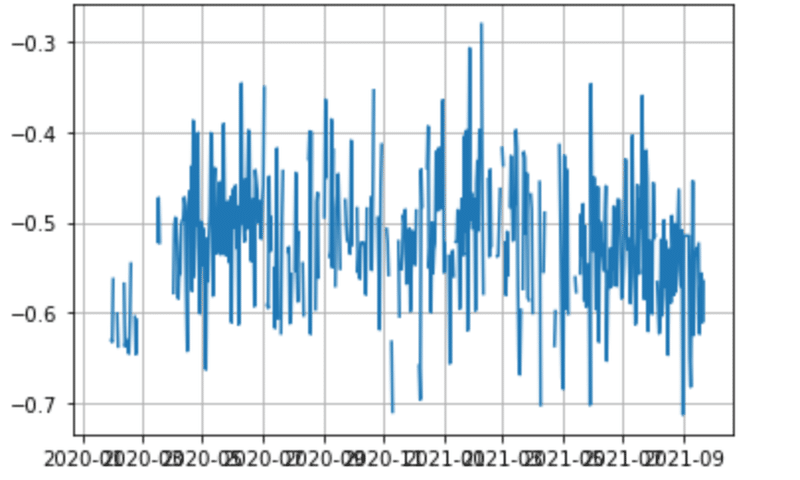
上記のグラフを確認すると負の値が多いですが、これは辞書にネガティブな意味合いの語彙が多く含まれているためです。数字の散らばり具合を見たいのでこの結果に標準化を行います。
#標準化処理
df_tweets = pd.read_csv('./tweets_cov_new.csv', names=['id', 'date', 'text', 'fav', 'RT'], index_col='date')
df_tweets = df_tweets.drop('text', axis=0)
df_tweets.index = pd.to_datetime(df_tweets.index)
df_tweets = df_tweets[['text']].sort_index(ascending=True)
# means_listという空のリストを作りそこにツイートごとの平均値を求める
means_list = []
for tweet in df_tweets['text']:
dl_old = get_diclist(tweet)
dl_new = add_pnvalue(dl_old, pn_dict)
pnmean = get_mean(dl_new)
means_list.append(pnmean)
# numpy配列に変換
means_list = np.copy(means_list)
# 標準化を行う
x_std = (means_list - means_list.mean()) / means_list.std()
df_tweets['pn'] = x_std
df_tweets = df_tweets.drop('text', axis=1)
df_tweets.index = pd.to_datetime(df_tweets.index)
# 1日ごとにpn値を平均でまとめて、欠損値は線形補間を行う
df_tweets = df_tweets.resample('D').mean().interpolate()
# matplotlibを用いてグラフ化
x = df_tweets.index
y = df_tweets.pn
plt.plot(x,y)
plt.grid(True)
# df_tweets_cov.csvという名前でdf_tweetsを再び出力
df_tweets.to_csv('./df_tweets_cov.csv')結果
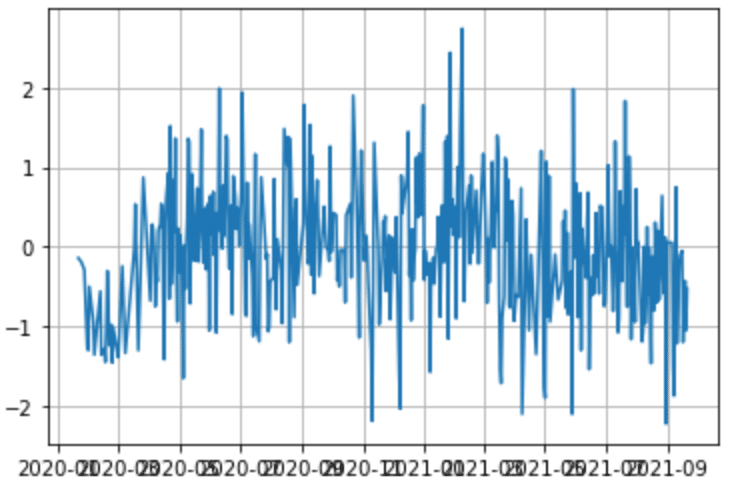
(3)日経平均株価のデータを取得し、データの整理をする。
日経平均株価の過去のcsvデータを取ってきて保存し、時系列データの終値のみを取り出す。
#日経平均株価の過去のcsvデータを取ってきて保存
import pandas as pd
from io import StringIO
import urllib
url = "https://indexes.nikkei.co.jp/nkave/historical/nikkei_stock_average_daily_jp.csv"
def read_csv(url):
res = urllib.request.urlopen(url)
res = res.read().decode('shift_jis')
df = pd.read_csv(StringIO(res))
# 必要のない最後の行を取り除いています
df = df.drop(df.shape[0]-1)
return df
# dfというdataframeで保存
df = read_csv(url)
# カラムから'始値', '高値', '安値'を取り除いて、ソートを行う
df["データ日付"] = pd.to_datetime(df["データ日付"], format='%Y/%m/%d')
df = df.set_index('データ日付')
df = df.drop(['始値', '高値', '安値'], axis=1)
df = df.sort_index(ascending=True)
#csvにて保存し 、出力
df.to_csv("./time_data_cov.csv")
print(df)結果
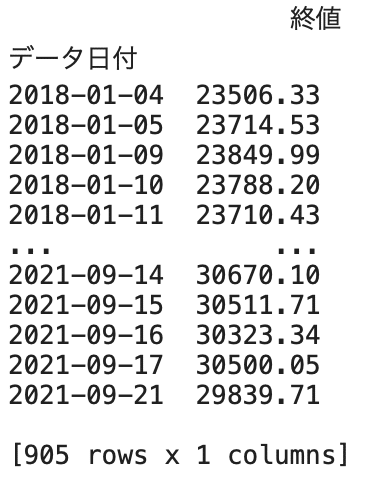
日経平均株価のデータと感情分析を行ったデータを結合し、欠損地を削除する。
#time_data_cov .csvとdf_tweet_covデータを結合し、欠損値を削除
import pandas as pd
df = pd.read_csv("./time_data_cov.csv" , index_col="データ日付")
# 二つのテーブルを結合し、Nanを消去
df_tweets = pd.read_csv('./df_tweets_cov.csv', index_col='date')
table = df_tweets.join(df, how='right').dropna()
# table.csvとして出力してください
table.to_csv("./table_cov.csv")
print(table)結果
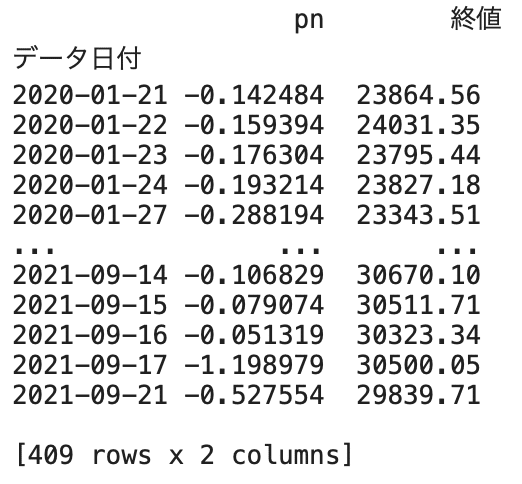
(4)株価の予測を行う。
それでは株価の予測を行なっていきます。特徴量は過去3日の日経平均株価の時系列の変化とPN値の変化を用いています。
訓練用データとテスト用データの二つに分け、訓練データを標準化し、訓練データの平均と分散を用いてテストデータの標準化を行なっていきます。
#訓練データとテストデータの二つに分け 、訓練データを標準化したのち、訓練データの平均と分散を用いてテストデータの標準化
from sklearn.model_selection import train_test_split
import pandas as pd
table = pd.read_csv("./table_cov.csv",index_col='データ日付')
X = table.values[:, 0]
y = table.values[:, 1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False)
X_train_std = (X_train - X_train.mean()) / X_train.std()
X_test_std = (X_test - X_train.mean()) / X_train.std()
# df_trainというテーブルを作りそこにindexを日付、カラム名をpn値、終値にしてdf_train_cov.csvという名前で保存。
df_train = pd.DataFrame(
{'pn': X_train_std,
'終値': y_train},
columns=['pn', '終値'],
index=table.index[:len(X_train_std)])
df_train.to_csv('./df_train_cov.csv')
# テストデータについても同様にdf_test_cov.csvという名前で保存。
df_test = pd.DataFrame(
{'pn': X_test_std,
'終値': y_test},
columns=['pn', '終値'],
index=table.index[len(X_train_std):])
df_test.to_csv('./df_test_cov.csv')株価の予測を行なっていきます。
#株価の予測
rates_fd = open('./df_test_cov.csv', 'r')
rates_fd.readline()
next(rates_fd)
exchange_dates = []
pn_rates = []
pn_rates_diff = []
exchange_rates = []
exchange_rates_diff = []
prev_pn = df_test['pn'][0]
prev_exch = df_test['終値'][0]
for line in rates_fd:
splited = line.split(",")
time = splited[0]
pn_val = float(splited[1])
exch_val = float(splited[2])
exchange_dates.append(time)
pn_rates.append(pn_val)
pn_rates_diff.append(pn_val - prev_pn)
exchange_rates.append(exch_val)
exchange_rates_diff.append(exch_val - prev_exch)
prev_pn = pn_val
prev_exch = exch_val
rates_fd.close()
INPUT_LEN = 3
data_len = len(pn_rates_diff)
test_input_mat = []
test_angle_mat = []
for i in range(INPUT_LEN, data_len):
test_arr = []
for j in range(INPUT_LEN):
test_arr.append(exchange_rates_diff[i - INPUT_LEN + j])
test_arr.append(pn_rates_diff[i - INPUT_LEN + j])
test_input_mat.append(test_arr)
if exchange_rates_diff[i] >= 0:
test_angle_mat.append(1)
else:
test_angle_mat.append(0)
test_feature_arr = np.array(test_input_mat)
test_label_arr = np.array(test_angle_mat)今回はロジスティック回帰を用いて予測を行います。
# train_feature_arr, train_label_arr,test_feature_arr, test_label_arrを特徴量にして、予測モデル(ロジスティック回帰)を用いて予測精度を計測する。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(train_feature_arr, train_label_arr)
print("--Method: LogisticRegression--")
print("Cross validatin scores:{}".format(model.score(test_feature_arr, test_label_arr)))結果
![]()
今回は上記の結果となりましたが、今回はデータ量も少なく、説明変数も少ないため改善の余地はまだまだあると思います。
特徴量として各国のGDPや各会社の経営状況、為替相場等を入れるみると良いのかもしれません。
また、違うモデルで行なったり、グリッドサーチ、パラメータチューニングを行うことにより、より高い精度を出せるのではないかと思います。
まとめ
データ取得〜予測まで一通りアウトプットすることができ、非常に良い勉強になりました。
まだまだ初心者ですが簡単なデータ分析ができるようになり少し自信がつきました。
これからも日々勉強しレベルアップしていけるよう努力し、仕事で活用できるようにしていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?