
気になる生成AI備忘録-vol.4-Google Research開発の動画生成AI「Lumiere」

■気になる生成AI備忘録とは
個人的に気になる生成AIのポスト(X)をまとめた備忘録を共有する連載シリーズです。
より気になるもの・深追いしたいトピックは当サイト『はじめての生成AI比較.com』にてUP予定
今回は、Google Researchが開発した、テキストと画像から動画を生成する動画生成AI「Lumiere」について、各項目を日本語化・気になる箇所を補足しました。
Google Researchの動画生成AI「Lumiere」紹介ページ、日本語訳と解説

テキストから動画生成
ビデオの上にカーソルを合わせると、入力された文章 (プロンプト) を確認できます。
補足:これは、Lumiereがプロンプトで説明された内容をもとに、動画を生成できることを示しています。カーソルを合わせると、実際にその入力プロンプトを見ることができます。

画像から動画生成
ビデオの上にカーソルを合わせると、入力された画像と文章 (プロンプト) を確認できます。
補足:これは、Lumiereが既存の画像とプロンプトの説明をもとに、新しい動画を生成できることを示しています。カーソルを合わせると、該当情報を確認できます。

特定のスタイルでの生成
単一の参考画像を使用して、Lumiere は微調整されたテキストから画像生成モデルの重みを活用して、ターゲットスタイルの動画を生成できます。
ビデオの上にカーソルを合わせると、プロンプト (文章) を確認できます。
補足:これは、Lumiereが特定のスタイルに合わせて動画を生成できることを示しています。例えば、参考画像として漫画の絵を使えば、その絵に似た動画を生成できるということです。カーソルを合わせると、どのようなプロンプトで指示したのかを確認できます。

紹介
私たちは、Lumiereを紹介します。Lumiereは、テキストから動画を生成する拡散モデルで、動画合成における重要な課題である、リアルで多様で一貫性のある動きを表現するために設計されています。この目的のために、私たちは、 Space-Time U-Net アーキテクチャを導入しました。このアーキテクチャは、モデル内を 1 回通すだけで、動画全体の時間の長さを一度に生成します。これは、既存のビデオモデルとは対照的なアプローチで、既存のモデルはまず時間的に離れたキーフレームを合成し、その後で時間超解像度処理を行うため、全体的な時間的整合性を達成することが本質的に困難です。空間と時間 (重要) のダウンサンプリングとアップサンプリングの両方を使用し、事前学習されたテキストから画像生成拡散モデルを活用することで、私たちのモデルは複数の空間時間スケールで処理を行い、フルフレームレート低解像度ビデオを直接生成することを学習します。私たちは、最先端のテキストから動画生成の結果をデモし、私たちの設計が、イメージから動画、動画ペイントイン、スタイライズされた生成を含む幅広いコンテンツ作成タスクとビデオ編集アプリケーションを容易に支援することを示します。
はい。個人的に一番気になったのが、↑の紹介部分です。
ですが、↑のように翻訳したとて、「時間超解像度処理」だったり専門的な用語があるせいか、あまりピンと来ません。
ただ、わかっていることは、AI動画生成において、一貫性を保つことはとても重要で、既存サービスではなかなか難しいという現状があります。
そのため、Lumiereは既存の動画生成AIと具体的に何が違って、何がすごいのか(期待できるのか)を、↑の紹介文を以下、さらに具体的に。
Lumiereは、テキストや画像の説明をもとに、リアルで自然な動きのある動画を生成するAIモデルである、と。
動画生成において、一貫性のある動きを表現することは大きな課題でしたが、Lumiereはそれを解決する革新的な技術だ、と。
従来の動画生成AIは、まず静止画のキーフレームをバラバラに作って、その後で滑らかにつなげる、という方法をとっていました。
しかし、この方法では、全体的な動きの一貫性を保つのが難しかったのです。
Lumiereは、この問題を解決するために、新しい手法を採用しています。
一度に全体の動画の長さを生成できる特殊な構造を使って、最初から最後まで、滑らかな動きを持つ動画を作ることが出来る、と。
さらに、空間情報だけでなく、時間情報も取り込んで処理することで、よりリアルで自然な動きを実現しています。
Lumiereは、(上述の通り)テキストだけでなく、画像からの動画生成も可能です。
また、既存の動画の一部を修正したり、特定のスタイルを模倣した動画の作成など、幅広い用途に利用できる、と。
これらの特徴から、Lumiereは以下のようなメリットが期待できるのではないかと考えられます。
・よりリアルで多様で一貫性のある動画を生成できる
・動画編集やコンテンツ作成の幅が広がる
・動画制作の効率化が図れる
少なくとも、上記は期待できるのではないかと感じました。(原文の紹介通りに解釈するとですが)
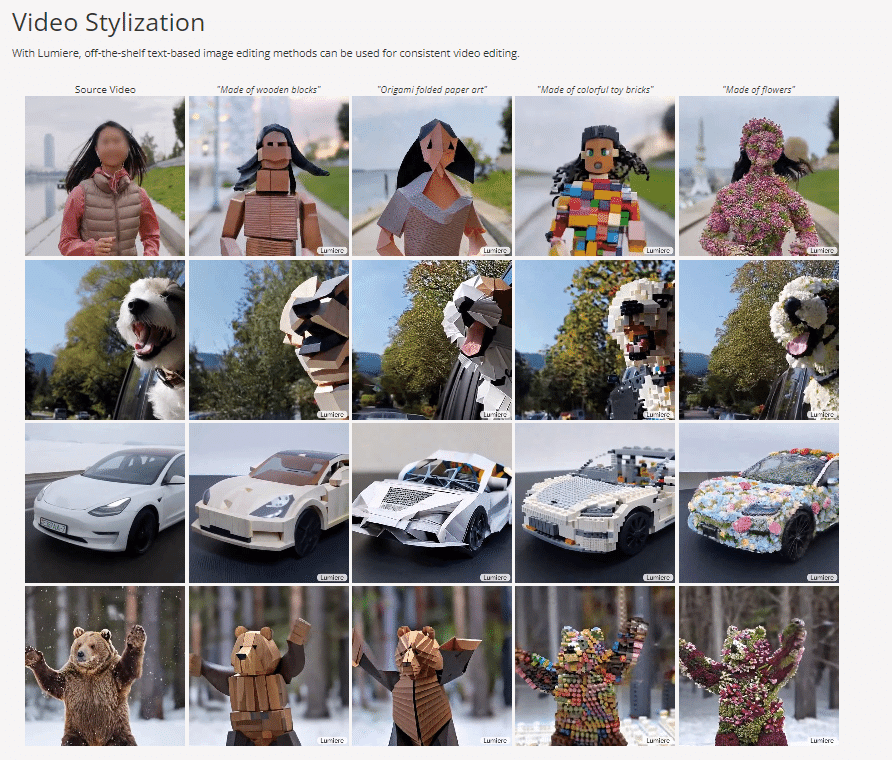
動画スタイリング
Lumiere を使用すると、市販のテキストベースの画像編集方法を一貫したビデオ編集に使用できます。
補足:文章(プロンプト)で指示することで、動画内の特定の部分だけを動かすような編集も行えるという機能かと。

シネマグラフ
Lumiere モデルは、ユーザーが指定した特定の領域内の画像の内容をアニメーション化することができます。
補足:Lumiere では、特定の部分だけを動画にするような、シネマグラフ風(一部は静止画、一部は動画になっている画像のこと)の編集も可能という機能です。
以上が、Google Researchが開発した、テキストと画像から動画を生成する動画生成AI「Lumiere 」紹介ページの各項目翻訳と補足でした。
やはり一番気になる部分は”紹介”のところでしょうか。
AI動画において、一貫性を保つというのは課題中の課題と言えるでしょうし、最も気になる部分でした。
Lumiere は、まだ開発初期段階のようですが、今後の発展が期待される技術だな、と。
いつ頃、日本でもとりあえず使用(試用)できるのかも気になるところですが
Google Lumiere just changed the AI video game with its massive video diffusion model.
— Min Choi (@minchoi) January 24, 2024
Unlike existing models, Lumiere generates entire videos in a single, consistent pass, thanks to its cutting-edge Space-Time U-Net architecture.
Here's what you need to know: pic.twitter.com/h7Obb38hri
↑こちらの方はLumiere についてXで紹介しているのですが、個人的に一番しっくりきたポストでした。
この方のポストのリプに、注目したい発言がありました。↓
@hila_chefer @omerbartal @InbarMosseri
— Min Choi (@minchoi) January 24, 2024
Any info you can share on when Lumiere model will be available to demo/try? 🤔
↑のポストの内容的に、「Lumiere のデモ/試用が可能になる時期について、何か情報があれば教えてください。 」というのが解釈できます。
この辺は、続報ないし日本で普通に使える日を期待したいとは現状思っています。
…思っているものの、個人的にはですが、Google Research(Google AI)が、まあGoogleがと言っていいかと思いますが、日本のマーケットというか、日本はどのような位置付けで考えているのか、去年から気になっているままです。
2023年のわりと早い段階で発表されていたGoogleの音楽生成AI「MusicLM」にしても、GoogleのプラットフォームであるAI Test Kitchenにて試用(デモ)公開されるも、利用可能ユーザーは限定的でしたし、登録したメールも未だに何の応答もないままです。
このLumiere、とりあえず日本でも一旦試用でいいので触れる日が明かされてほしいなというのが、正直なところです。
この記事が気に入ったらサポートをしてみませんか?