パラメータチューニング

〇パラメータとは?
-モデルを作る際の設定値や制限値。
-機械学習では自動的には学習してくれない。
-モデルの性能を大きく左右する。
〇料理にたとえると、、、
・データ → 食材
・パラメータ → 加熱時間、分量、など
・アルゴリズム → レシピ
〇交差検証
→パラメーターのチューニング方法の1つ。
→分割によって学習・評価データのパターンを複数つくり、モデルの汎化性能を評価する方法。
→K分割交差検証は、データをK個(3~5)に分割。
①すべてのデータがすべて1度だけ評価に用いられるため、すべてのサンプルに対していい汎化性能を示さないと、高いスコアを出せない。
②すべてのデータを効率的に利用できるため、より正確なモデルができる。
欠点
→計算時間コスト。
〇グリッドサーチ
-パラメータの候補から、すべての組み合わせを試す。
-性能の評価には交差検定を利用する。
-探索した結果から最適なパラメータの組み合わせを選ぶ
〇グリッドサーチの前準備
①関数のインポート
from sklearn.model_selection import GridSearchCV②グリッドサーチの設定準備
・モデルの箱を代入した変数(必須)
model = DT(random_state=0)・探索するパラメータとその範囲を代入した変数(必須)
parameters = {パラメータの名前①:[値1,値2,値3,,,], パラメータの名前②:[値1,値2,値3,,,]} ・クロスバリデーションの分割数
・評価に使用する関数
③グリッドサーチの設定
GridSearchCV(モデルの箱, パラメータの範囲を表す変数, cv=クロスバリデーションの分割数, scoring="評価指標", return_train_score=True)例)
# 決定木モデルのインポート
from sklearn.tree import DecisionTreeClassifier as DT
# グリッドサーチのインポート
from sklearn.model_selection import GridSearchCV
# 決定木モデルの準備
model = DT(random_state=0)
# パラメータの準備
parameters = {"max_depth":[2,3,4,5,6,7,8,9,10]}
# グリッドサーチの設定
gcv = GridSearchCV(model, parameters, cv=5, scoring='roc_auc', return_train_score=True)〇グリッドサーチの実行
grid.fit(説明変数, 目的変数)〇グリッドサーチの結果の確認
<確認事項>
・モデルの学習にかかった時間
・予測にかかった時間
・学習に用いたデータを使って評価した精度
・学習には用いなかったデータを使って評価した精度
※特に重要な後半2つの項目を取り出す場合。
grid.cv_results_['mean_train_score']
gric.cv_results_['mean_test_score']# 評価スコアの取り出し
train_score = gcv.cv_results_['mean_train_score']
test_score = gcv.cv_results_['mean_test_score']
print(train_score)
print(test_score)[0.75189177 0.82608925 0.8511899 0.86495018 0.8783299 0.89220921
0.90611839 0.91879575 0.93225731]
[0.75059503 0.82466539 0.84533595 0.85490475 0.86086691 0.85425
0.84496702 0.82709776 0.80383339] ・パラメータを2から10まで変えたときのAUCスコアがリストとして返された。
・mean_train_scoer,mean_test_scoreのmeanは分割数を5にしたので5回分の平均を表しています。
〇train_scoreとtest_scoreの比較
パラメータmax_depthを範囲2~10で変えたとき、どう変化したかを可視化したうえで比較してみる。
・X軸・・・max_depth
・y軸・・・AUCスコア
# 評価スコアの取り出し
train_score = gcv.cv_results_["mean_train_score"]
test_score = gcv.cv_results_["mean_test_score"]
# matplotlib.pyplotを省略名pltとしてインポート
import matplotlib.pyplot as plt
# 学習に用いたデータを使って評価したスコアの描画
plt.plot([2,3,4,5,6,7,8,9,10], train_score, label="train_score")
# 学習には用いなかったデータを使って評価したスコアの描画
plt.plot([2,3,4,5,6,7,8,9,10], test_score, label="test_score")
# グラフにタイトルを追加
plt.title('train_score vs test_score')
# グラフのx軸に名前を追加
plt.xlabel('max_depth')
# グラフのy軸に名前を追加
plt.ylabel('AUC')
# 凡例の表示
plt.legend()
# グラフの表示
plt.show()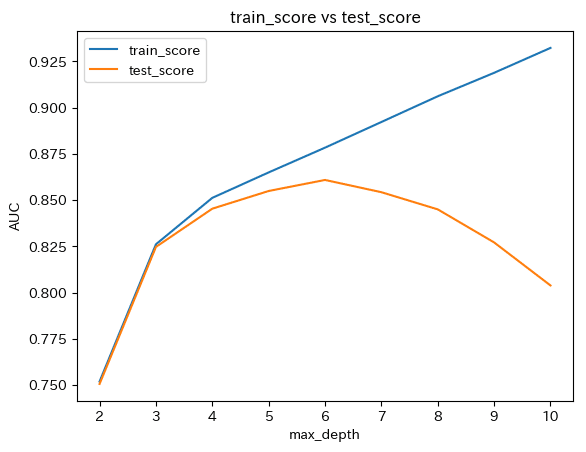
・train_scoreは、max_depthの値が大きくなるにつれて、スコアが上昇している。一方、test_scoreはmax_septh=6をピークにスコアが低下している。
・max_depthが6を超えたとき、train_scoreは向上しているのにtest_scoreが低下しているのは、モデルが学習データに適合しすぎた結果、未知データに対しては適合できていない。(汎化性能がない)状態を表す。この状態は過学習。
・train_scoreとtest_scoreのパラメータによる変化を可視化することによって、過学習になるタイミングを可視化することが出来る。
〇最適パラメータモデルによる
予測・評価
最適なパラメータが何だったのかは、best_prams_を使って確認することが出来る。
grid.best_params_最適なパラメータで学習された母出るは、best_estimator_を使って、利用することが出来る。
grid.best_estimator_例)
# 最適なパラメータの表示
print( gcv.best_params_ )
# 最適なパラメータで学習したモデルの取得
best_model = gcv.best_estimator_
# 評価用データの予測(予測結果が1である確率のみ抜き出す)
pred_y3 = best_model.predict_proba(test_X)[:,1]
# AUCの計算
auc3 = roc_auc_score(test_y, pred_y3)
# AUCの表示
print ( auc3 ){'max_depth': 6}
0.8631100075115532 〇ROC曲線の描画
1回目・・・max_depth=2
2回目・・・max_depth=10
3回目・・・max_depth=6
の3つの決定木モデルを作りました。
それぞれのRoc曲線を描き、比較してみましょう。
# matplotlib.pyplotのインポート
from matplotlib import pyplot as plt
# roc_curveのインポート
from sklearn.metrics import roc_curve
# 偽陽性率、真陽性率、閾値の計算
# なお、予測結果は以下の変数に代入されているものとします。
# pred_y1:max_depth=2の場合の予測結果
# pred_y2:max_depth=10の場合の予測結果
# pred_y3:max_depth=6の場合の予測結果
# また、それぞれの戻り値を代入する変数は以下とします。
# fpr1,tpr1,thresholds1:max_depth=2の場合の偽陽性率、真陽性率、閾値
# fpr2,tpr2,thresholds2:max_depth=10の場合の偽陽性率、真陽性率、閾値
# fpr3,tpr3,thresholds3:max_depth=6の場合の偽陽性率、真陽性率、閾値
fpr1, tpr1, thresholds1 = roc_curve(test_y, pred_y1)
fpr2, tpr2, thresholds2 = roc_curve(test_y, pred_y2)
fpr3, tpr3, thresholds3 = roc_curve(test_y, pred_y3)
# ラベル名の作成
# なお、それぞれの戻り値を代入する変数は以下とします。
# roc_label1:max_depth=2の場合のラベル名
# roc_label2:max_depth=10の場合のラベル名
# roc_label3:max_depth=6の場合のラベル名
roc_label1='ROC(AUC={:.2}, max_depth=2)'.format(roc_auc_score(test_y, pred_y1))
roc_label2='ROC(AUC={:.2}, max_depth=10)'.format(roc_auc_score(test_y, pred_y2))
roc_label3='ROC(AUC={:.2}, max_depth=6)'.format(roc_auc_score(test_y, pred_y3))
# ROC曲線の作成
plt.plot(fpr1, tpr1, label=roc_label1)
plt.plot(fpr2, tpr2, label=roc_label2)
plt.plot(fpr3, tpr3, label=roc_label3)
# 対角線の作成
plt.plot([0, 1], [0, 1], color='black', linestyle='dashed')
# グラフにタイトルを追加
plt.title('ROC')
# グラフのx軸に名前を追加
plt.xlabel('FPR')
# グラフのy軸に名前を追加
plt.ylabel('TPR')
# x軸の表示範囲の指定
plt.xlim(0, 1)
# y軸の表示範囲の指定
plt.ylim(0, 1)
# 凡例の表示
plt.legend()
# グラフを表示
plt.show()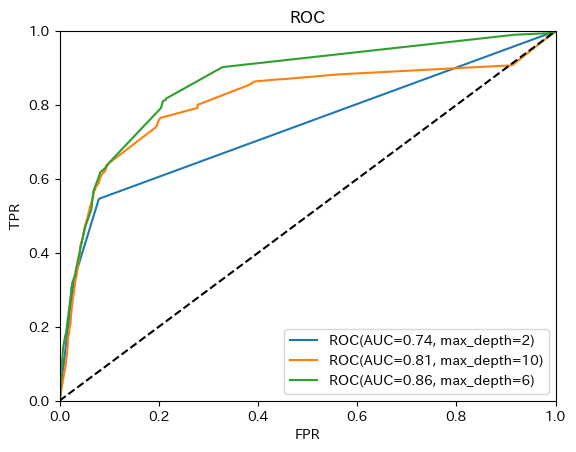
・グリッドサーチで探索した最適パラメータであるmax_depth=6で学習したモデルはAUCが大きくなっている。
・過学習はしていないと考えられる。(train_socro vs test_scoreより)
〇決定木の描画
# 最適なパラメータで学習したモデルの取得
best_model = gcv.best_estimator_
# 決定木描画ライブラリのインポート
from sklearn.tree import export_graphviz
# 決定木グラフの出力
export_graphviz(best_model, out_file="tree.dot", feature_names=train_X.columns, class_names=["0","1"], filled=True, rounded=True)
# 決定木グラフの表示
from matplotlib import pyplot as plt
from PIL import Image
import pydotplus
import io
g = pydotplus.graph_from_dot_file(path="tree.dot")
gg = g.create_png()
img = io.BytesIO(gg)
img2 = Image.open(img)
plt.figure(figsize=(img2.width/100, img2.height/100), dpi=75)
plt.imshow(img2)
plt.axis("off")
plt.show()
・階層の深さが6の大きな木となったことで、階層深さ2に比べ、複雑な表現が可能になった。
・一方、階層を深くしたことで、人が理解するのが少し難しくなった。
・ターゲティングモデルのブラッシュアップ成功!
この記事が気に入ったらサポートをしてみませんか?