層化K-分割交差検証【StratifiedKFold】

・目的変数の偏りがある場合。
・目的変数のクラス数が多い場合。
・目的変数のクラス割合を担保しながら、データ分割を行う。
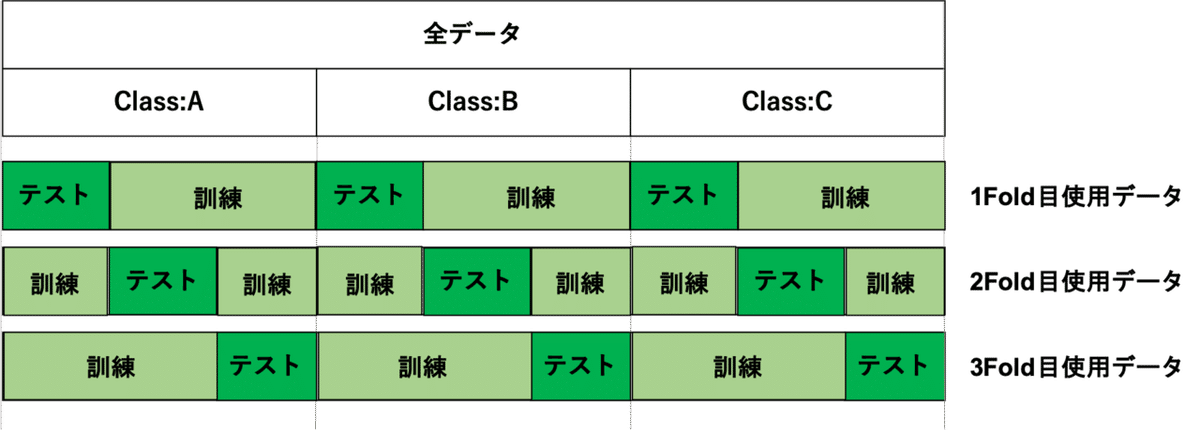
<手順①>(目的変数のクラスの割合を確認)
割合を確認する場合はvalue_counts()を用い、引数normalize=Trueとする。
In [1]: # ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_wine
# データのロード
wine = load_wine()
df_wine = pd.DataFrame(data=wine.data,columns=wine.feature_names)
df_wine['target'] = wine.target
# 目的変数のクラス割合
print(df_wine['target'].value_counts(normalize = True))
Out[1]: 1 0.398876
0 0.331461
2 0.269663
Name: target, dtype: float64<手順②>(層化K-分割交差検証を行う)
・scikit-learnの中からStratifiedKFoldというモジュールをインポートします。
【StratifiedKFold()の引数】
引数n_split: データの分割数、デフォルトは5
引数shuffle: 連続する数字のグループ分けとするか(True もしくはFalse)
引数random_state: 乱数の設定
In [1]: # ライブラリのインポート
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=3,shuffle=True,random_state=0)
for fold,(train_index, test_index) in enumerate(kf.split(wine.data, df_wine['target'])):
print('FOLD{}'.format(fold))
print(df_wine.iloc[train_index]['target'].value_counts(True))
Out[1]: FOLD0
1 0.398305
0 0.330508
2 0.271186
Name: target, dtype: float64
FOLD1
1 0.403361
0 0.327731
2 0.268908
Name: target, dtype: float64
FOLD2
1 0.394958
0 0.336134
2 0.268908
Name: target, dtype: float64この記事が気に入ったらサポートをしてみませんか?