
顔の輪郭から適切な眼鏡を診断させた。

自分ってどの形の眼鏡が似合うんだろう?と一度は思ったことあると思います。輪郭は眼鏡の決定に大きくかかわります。そこで今回は、輪郭からその人に似合った眼鏡をAIが教えるサービスを作成しました。
目次
0.自己紹介
1.本テーマに至った経緯
2.モデル制作
3.精度の向上過程(30%→60%)
4.HTML,CSS制作
5.反省・課題
6.あとがき
0.自己紹介
少しだけ自己紹介させていただきます。私はAidemy入会までの1か月間程progateにてプログラミングの学習をしていました。以上です(笑)そんなレベルの私が入会から1か月間で作った作品を共有致します。今後の学習者様方の参考になれば幸いです。
1.本テーマに至った経緯
自分では分からない自分のことに人は興味があるのではないか? このテーマをもとに成果物の内容をまず考えました。手相占いや顔面偏差値 10年後の自分の顔など聞いたら少し試したくなりませんか?初学者の私はまず「あなたに似合う眼鏡診断」を作成しました。男女識別のアルゴリズムを使えばAidemyの学習内容から制作できると思った為です。また私自身が眼鏡選びにいつも苦戦しているからです(笑)以上が本テーマに至った簡単な経緯です。
2.モデル制作
はじめに本ブログで定義するおすすめ眼鏡について説明させていただきます。似合う眼鏡選びにとって重要な要素は顔の輪郭です。そこでAIがアップロードされた顔の輪郭を分類しておすすめの眼鏡を診断するとなっておりました。
本ブログでは各輪郭に似合う眼鏡は次のように定義しております。(丸顔:スクエア型)(四角顔:オバール型)(三角顔:ボストン型)(面長顔:ラウンド型)
まず4種の輪郭の画像データ1000枚を学習させます。そしてアップロードされた顔画像がどの輪郭かを診断(分類)します。
モデル構築は以下の手順で進めました。
モデル構築
⓪開発環境
➀VGG16を使った転移学習
②kaggleよりフェイスデータ取得
③画像読み込み
➃学習データとテストデータに分割
⑤モデルを構築し、精度を計測
⑥重みの保存 1から順番に説明させていただきます。
⓪開発環境
・Pythonバージョン:3
・データパッケージ:kaggle / dataset
・モデル構築:Google Colab
・HP構築,実行環境:Visual Studio Code
➀VGG16を使った転移学習
学習済みのアーキテクチャを利用して、今回のデータセットで再学習させることで、学習時間を大きく短縮させることができます。また、精度の向上も期待できます。今回はVGG16を使った転移学習でモデル構築をしています。
②kaggleよりフェイスデータ取得

今回利用する顔の輪郭(Face Shape Dataset)のデータセットはKaggleから取得できます。中身は丸顔、四角顔、三角顔、面長顔の4種類×約1000枚の画像データです。こちらの画像データをダウンロードして、ドライブで管理しました。顔の輪郭のデータは以下になります。データを取得するには無料の会員登録が必要になります。
(データ出典:https://www.kaggle.com/datasets/niten19/face-shape-dataset)
③画像読み込み
path_marugao = os.listdir('/content/drive/MyDrive/aidemy_project/data/marugao/Round_training/')
path_sikakugao = os.listdir('/content/drive/MyDrive/aidemy_project/data/sikakugao/Square_training/')
path_sankakugao = os.listdir('/content/drive/MyDrive/aidemy_project/data/sankakugao/Heart_training/')
path_omonagakao = os.listdir('/content/drive/MyDrive/aidemy_project/data/omonagagao/Oblong_training/')
img_marugao = []
img_sikakugao = []
img_sankakugao = []
img_omonagakao = []
img_size= 400
for i in range(len(path_marugao)):
img = cv2.imread('/content/drive/MyDrive/aidemy_project/data/marugao/Round_training/' + path_marugao[i])
img = cv2.resize(img, (400,400))
img_marugao.append(img)
for i in range(len(path_sikakugao)):
img = cv2.imread('/content/drive/MyDrive/aidemy_project/data/sikakugao/Square_training/' + path_sikakugao[i])
img = cv2.resize(img, (400,400))
img_sikakugao.append(img)
for i in range(len(path_sankakugao)):
img = cv2.imread('/content/drive/MyDrive/aidemy_project/data/sankakugao/Heart_training/' + path_sankakugao[i])
img = cv2.resize(img, (400,400))
img_sankakugao.append(img)
for i in range(len(path_omonagakao)):
img = cv2.imread('/content/drive/MyDrive/aidemy_project/data/omonagagao/Oblong_training/' + path_omonagakao[i])
img = cv2.resize(img, (400,400))
img_omonagakao.append(img)4種の輪郭を格納した4つのファイルパスをペーストして、上記のfor文で読み込み作業をしております。
➃学習データとテストデータに分割
X = np.array(img_marugao + img_sikakugao + img_sankakugao + img_omonagakao )
y = np.array([0]*len(img_marugao) + [1]*len(img_sikakugao) + [2]*len(img_sankakugao) + [3]*len(img_omonagakao) )
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]⑤モデルを構築し精度を計測
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
input_tensor = Input(shape=(400,400,3))
vgg16 = VGG16(include_top=False,weights="imagenet",input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256,activation="relu"))
top_model.add(Dense(128,activation="relu"))
top_model.add(Dropout(rate=0.25))
top_model.add(Dense(4, activation="softmax"))
model = Model(inputs = vgg16.input, outputs = top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable=False
model.compile(loss="categorical_crossentropy",optimizer=optimizers.SGD(lr=1e-4,momentum=0.9), metrics=["accuracy"])
model.fit(X_train,y_train,batch_size=50,epochs=20,validation_data=(X_test,y_test))上記で層を作り表示する精度指標を何にするかなどを指定してコンパイルします。
# 画像を一枚受け取り、(スクエア型、オーバル型、ボストン型、、ラウンド型)のどれかを判定して返す関数
def pred_gender(img):
img = cv2.resize(img,(400,400))
pred = np.argmax(model.predict(img.reshape(1,400,400,3)))
if pred == 0:
return "marugao"
elif pred == 1:
return "sikakugao"
elif pred == 2:
return "sankakugao"
else:
return "omonagakao"
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])上記が受け取った画像を判定して答えを返す部分です
⑥重みの保存
# resultsディレクトリを作成
result_dir = '/content/drive/MyDrive/aidemy_project/resultsディレクトリ/'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))3.精度の向上過程(30%→60%)
まずは精度よりも実装することに注力しました。そのため最初の制度は32%程度でした。精度の向上で1番大きな要因が画像サイズでした。またエポック数の調整等を繰り返して約60%まで引き上げました。
エポック数に対するaccuracyの変化
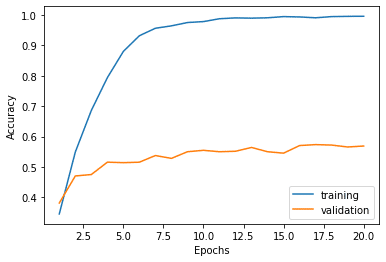
80%超えの精度を目指していましたが、顔の輪郭の分類は難易度が高かったです。Open CVによる顔検知で顔のみをトリミングして読み込む等の技術を学んでいければと思います。
4.HTML,CSS制作
HTMLとCSSは「シンプルに!上品に!」を意識しています。基礎的な装飾しかしていませんが満足いく状態にできました。


レスポンシブやアニメーションはできていませんので今後励みたいと思います。
実行

試しに画像をアップロードしたところ、無事に判定できました。
5.反省・課題
今回初めてテーマから全てやりましたが反省だらけでした。まず4つの輪郭に分類というのが難しかったです。丸顔と面長顔、四角顔と三角顔は場合によっては酷似しており判断が難しいです。そもそも輪郭だけでベストな眼鏡を導くというのが少し強引かなと思います。1番の反省点はやはりテーマです。自分では分からない自分のことに人は興味があるのではないか?を軸としていました。手相占いや顔面偏差値そして眼鏡選びです。しかしこれらの内容は誰が見ても正解と言えない場合が多いです。つまりAIの精度を証明しづらいなと感じました。次の作品は精度に注視して取り組んでまいりたいと思います。
6.あとがき
ここまで読んでいただきありがとうございます。初学者が1か月で作ってみた。でしたが引き続き励んで頑張りたいと思います。
この記事が気に入ったらサポートをしてみませんか?