【論文要約】Evolutionary Optimization of Model Merging Recipes【Claude 3 Opus】

イントロダクション
今回の記事ではClaude 3 Opusを用いて、Sakana AIから進化的計算による基盤モデル構築に関する論文を要約してみました。今回もOpusと壁打ちした結果をメモのようにまとめています。
引用論文
[1]T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
論文の主要部分の要約と全体的な文脈・貢献の把握
本論文「Evolutionary Optimization of Model Merging Recipes」は、進化的アルゴリズムを用いてモデルマージングのプロセスを自動化し、多様なオープンソースモデルを組み合わせることで、強力な基盤モデルを生成する手法を提案している。 具体的には、パラメータ空間とデータフロー空間の両方でモデルマージングを行う進化的アプローチを採用し、CMA-ESなどのアルゴリズムを用いてモデルの重みやレイヤーの組み合わせを最適化する。これにより、日本語LLMと数学推論能力を持つモデル(EvoLLM-JP)や、文化的に適した日本語VLM(EvoVLM-JP)の生成に成功した。これらのモデルは、明示的に最適化されていないタスクでも、ベンチマークにおいてSOTAの性能を達成し、70Bパラメータの日本語LLMを上回る性能を7Bパラメータのモデルで実現した。
本研究は、進化的アルゴリズムを用いたモデルマージングの自動化という新しいパラダイムを提案し、追加の訓練データや計算リソースを必要とせずに強力なモデルを生成できることを示した。また、異なるドメインのモデルを組み合わせることで、人間の直感では発見が難しい新しい能力を持つモデルを作れることを実証した。この手法は、ファウンデーションモデルの開発におけるコストと資源の問題に対する解決策を提示すると同時に、ベンチマークにとらわれず、実世界のタスクに適したモデルを効率的に作成できる可能性を示唆している。一方で、マージ元モデルの限界を継承してしまう点など、手法の限界も明らかになった。
2章"Background and Related Work"要約
2.1:Overview of Model Merging
2.1節 "Overview of Model Merging"では、モデルマージングの概要と利点が説明されている。モデルマージングとは、複数の事前学習済みモデルを組み合わせることで、単一のタスクに特化したモデルを超える性能を持つ汎用モデルを生成する手法である。 モデルマージングの簡単な方法の一つは、「モデルスープ」アプローチである。これは、同じ基本モデルから微調整された複数のモデルの重みを平均化することでマージを行う手法で、画像処理や画像分類モデルにおいて著しい性能向上を示した。また、潜在拡散モデルのような画像生成モデルにも効果的であり、Stable Diffusionでは、様々なスタイルに特化したモデルを線形補間やSLERP(spherical linear interpolation)を用いて組み合わせることで、特化モデルの長所を単一のモデルに統合することに成功している。モデルスープアプローチの効果は、重み平均化が平坦な局所最小値につながることで説明されている。理論的および実証的研究から、平坦な局所最適解は分布シフトに対してより良い汎化性能を示すことが明らかになっており、大規模な生成モデルにおいても、重み平均化の理論的性質と実用的な影響が検証されている。モデルマージングは、追加の訓練データやリソースを必要とせずに高性能モデルを生成できる点で、モデル開発の民主化に大きく貢献している。特に、Open LLM Leaderboardでは、愛好家コミュニティによって作成されたマージモデルが上位を占めるようになった。
ただし、現在のモデルマージングは、モデル作成者の直感とインスティンクトに大きく依存しており、ある種のブラックアートやアルケミーとみなされている。コミュニティにおけるオープンモデルとベンチマークの多様性が増す中で、人間の直感だけでは限界があり、より体系的なアプローチが求められている。著者らは、進化的アルゴリズムがモデルマージングの自動化への道を切り開くと考えている。
2.2:Merging Language Models
2.2節 "Merging Language Models"では、言語モデルのマージングに特化した手法について説明されている。単純な重み補間は画像生成モデルのマージングには効果的だが、言語モデルでは性能が不十分であることが指摘されている。また、パラメータの干渉による性能低下も課題となっている。 これらの課題に対応するために、いくつかの手法が提案されている。Task Arithmeticは、事前学習済みモデルと微調整済みモデルの重み差を用いてタスクベクトルを構築し、算術演算によってマージモデルの動作を制御する手法である。この手法により、マージモデルの振る舞いを柔軟に操作できるようになる。
TIES-Mergingは、パラメータの冗長な値と矛盾する符号を解決することで、情報損失を軽減するマージング手法である。この手法は、3つのステップからなる: 最小限のパラメータ変更のリセット、符号の競合解決、アラインメントされたパラメータのみのマージ。これにより、既存のマージング手法における情報損失の問題に対処している。
DAREは、微調整済みモデルとオリジナルモデルの小さな差分をゼロにし、差分を増幅することで、マージングの性能を向上させる手法である。DAREは、Task ArithmeticやTIES-Mergingと組み合わせて使用されることが多い。
これらの手法を実装したツールキットとして、Mergekitが登場した。Mergekitは、単純な線形補間やSLERPに加えて、Task Arithmetic、TIES-Merging、DAREなどの高度なレシピを提供している。これにより、愛好家コミュニティは、様々な基本モデルの微調整版を組み合わせて実験できるようになった。その結果、多様なマージモデルが開発され、Open LLM Leaderboardの上位は、コミュニティによって生成されたマージモデルによって徐々に占められるようになった。
Mergekitはまた、Frankenmergingと呼ばれる新しい手法も導入した。これは、重みのマージではなく、複数のモデルから異なる層を順番に積み重ねて新しいモデルを作成する手法である。この手法の利点は、マージ対象のモデルを固定のアーキテクチャを持つ特定のモデルファミリーに限定する必要がないことである。ただし、Frankenmergingの新しいレシピを発見することは、コミュニティにとって課題であり、試行錯誤が必要とされている。
2.3:Connection to Evolutionary Neural Architecture Search
2.3節 "Connection to Evolutionary Neural Architecture Search"では、進化的アルゴリズムとニューラルアーキテクチャ探索(NAS)の関連性について述べられている。NASは、進化的アルゴリズムを用いて新しいモデルアーキテクチャを発見する手法であるが、各候補モデルアーキテクチャを訓練する必要があるため、計算コストが高いという問題がある。 一方、モデルマージングにおける進化的アプローチは、事前学習済みのTransformerブロックを組み合わせることで、計算コストを抑えつつ、新しいアーキテクチャを探索できる利点がある。この点で、本研究のアプローチはNASとは異なる特徴を持っている。
関連研究として、NEAT(NeuroEvolution of Augmenting Topologies)が紹介されている。NEATは、ニューラルネットワーク構造を進化させる手法であり、勾配降下を使用せずにタスク固有の誘導バイアスを持つニューラルネットワーク構造を進化させることを目的としている。
また、Weight Agnostic Neural Networksは、重みではなく構造を進化させることで、タスク固有の誘導バイアスを持つニューラルネットワークを生成する手法である。この手法は、勾配降下を使用せずに重みパラメータを訓練する必要がないという点で、本研究のアプローチと共通点がある。
SMASH(Superposition of Many Subnetworks Heuristics)は、Hypernetworkを用いてアーキテクチャ候補の重みを推定することで、コストのかかる内部ループ訓練を回避するNAS手法である。この手法は、アーキテクチャ候補の重みを効率的に推定することで、探索の効率化を図っている。
本研究は、進化的アルゴリズムをモデルマージングの自動化と最適化に適用することで、新しいアプローチを提案している。単一のアーキテクチャに限定された重み空間でのマージングの最適化だけでなく、異なるモデルからのレイヤーの積み重ねを最適化するデータフロー空間での探索も行っている。重み空間のマージング最適化では、マージ対象のモデルを同じ親のベースモデルの微調整版に限定する必要があるが、レイヤーの積み重ね最適化にはそのような制約がない。本研究では、パラメータ空間とレイヤー空間の両方で進化を適用することで、既存のビルディングブロックから全く新しいニューラルアーキテクチャを作り出すことを目指している。
3章"Method"要約
3.1:Merging in the Parameter Space
3.1節 "Merging in the Parameter Space" では、パラメータ空間でのモデルマージングについて説明されている。この手法は、複数のファウンデーションモデルの重みを統合し、個々のモデルを上回る性能を持つ単一のモデルを生成することを目的としている。著者らは、タスクベクトル分析を用いて各モデルの強みを理解し、TIES-Mergingを拡張することで、より細粒度の層ごとのマージングを可能にしている。これにより、入力埋め込みや出力埋め込みを含む各層に対して、スパース化と重み混合のためのマージング設定パラメータを確立している。これらの設定は、CMA-ESなどの進化的アルゴリズムを用いて、選択されたタスクに対して最適化される。
3.2:Merging in the Data Flow Space
3.2節 "Merging in the Data Flow Space" では、データフロー空間でのモデルマージングについて説明されている。この手法は、各層の重みを変更せずに、トークンが層を通過する際の推論パスを最適化することで、モデルマージングを行う。著者らは、シリアル接続と非適応型設定に限定することで、探索空間を管理している。具体的には、N個のモデルと予算Tが与えられた場合、すべてのトークンが特定のタスクに対して従うべき層インデックスのシーケンスを探索する。探索空間のサイズを減らすために、著者らは、反復的またはパーミュートされたシーケンスを除外するインジケータ配列を導入している。進化的アルゴリズムは、このインジケータ配列とスケーリングパラメータを最適化する。スケーリングパラメータは、層間の分布シフトを緩和するために使用される。
3.3:Merging in Both Spaces
3.3節 "Merging in Both Spaces" では、パラメータ空間とデータフロー空間の両方でマージングを行うことの利点について説明されている。著者らは、これらの手法が直交していることを指摘し、それらを組み合わせることでマージされたモデルの性能をさらに向上できることを示している。具体的には、パラメータ空間でマージングを適用して複数のマージモデルを生成し、それらをデータフロー空間でマージングするためのソースモデルとして使用することができる。これにより、マルチオブジェクティブ最適化が可能となり、関連するメトリクスにおけるモデルの性能をさらに拡張できる。
図表の詳細な分析と説明
Figure 1

T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
Figure 1は、提案手法の全体像を示しており、パラメータ空間(PS)とデータフロー空間(DFS)の両方でマージを行う点が特徴的である。パラメータ空間(PS)では各レイヤーの重みを混合し、データフロー空間(DFS)ではレイヤーの順列を最適化することで、より効果的なモデルマージングを実現している。
Figure 2

[1] T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
Figure 2は、MGSM-JAタスクにおける各モデルの正解パターンを可視化したものである。提案手法(Ours)が他のモデルと比較して多くの問題を正解しており、特に20番台の問題では顕著な差が見られる。これは、提案手法が源モデルの知識を効果的に統合し、新しい能力を獲得していることを示唆している。
Figure 3,4
Figure 3と4は、進化的アルゴリズムによるマージング設定の最適化プロセスを示している。

[1] T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
Figure 3はパラメータスペースマージングの設定であり、各源モデルの密度と重みが最適化されている。特に日本語LLMの密度が高く、マージングにおける重要性が示唆されている。
[1] T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
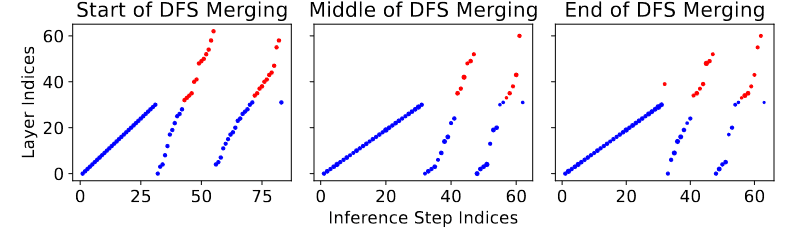
Figure 4はデータフロースペースマージングの設定であり、レイヤーの選択と順序が進化的に最適化されている。
Table 1

[1] T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
Table 1は、各モデルのMGSM-JAとJP-LMEHにおける性能を比較したものである。提案手法(Ours)がベースモデルを大幅に上回る性能を達成しており、特にパラメータ数が7Bと少ないにもかかわらず、70Bの日本語LLMと同等以上の性能を示している点が注目に値する。
Table 2
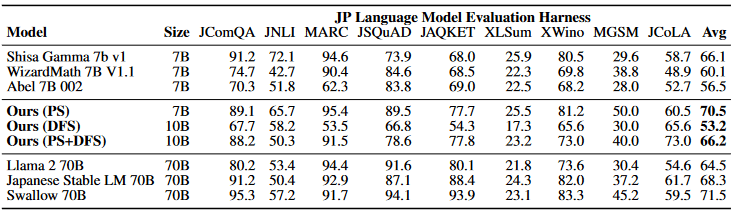
[1] T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
Table 2は、JP-LMEHの各タスクにおける性能の内訳を示しており、提案手法が全般的に高い性能を維持していることがわかる。
Table 3

[1] T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, ‘Evolutionary Optimization of Model Merging Recipes’. arXiv, Mar. 19, 2024. Accessed: Mar. 21, 2024. [Online]. Available: http://arxiv.org/abs/2403.13187
Table 3は、各VLMのJA-VG-VQA-500とJA-VLM-Bench-In-the-Wildにおける性能を比較したものである。提案手法(Ours)が日本語LLMとVLMを効果的にマージすることで、文化的に適したVLMを生成できていることが示されている。特にJA-VLM-Bench-In-the-Wildにおける高い性能は、提案手法が日本文化に特化したコンテンツを適切に扱える能力を獲得していることを示唆している。
論文の評価指標の要約
本論文では、提案手法の性能評価のために、MGSM-JAタスク、JA-VG-VQA-500とJA-VLM-Bench-In-the-Wildタスク、JP-LMEHベンチマークの4種類の評価指標が使用されている。
MGSM-JAタスクでは、正解率が評価指標として用いられている。この指標は、数値の正解と推論の言語(日本語)を同時に考慮しており、出力の最後に出現する数値を答えとして扱うことで、出力形式の不一致による影響を最小限に抑える工夫がなされている。また、fasttextを用いて出力の言語を判定することで、日本語以外の回答を適切に処理している。
JA-VG-VQA-500とJA-VLM-Bench-In-the-Wildタスクでは、ROUGE-Lが評価指標として用いられている。この指標は、言語検出器を用いて日本語以外の回答をペナルティ化することで、日本語での回答の質を評価している。ただし、日本語のテキストでも一般的に使用される単語(例: UFO)については、例外として扱われている。
JP-LMEHベンチマークでは、9つのタスクの平均スコアが評価指標として用いられている。この指標は、日本語の言語能力を総合的に評価することを目的としているが、個々のタスクの重要度は考慮されていない。
これらの評価指標は、いずれも提案手法を明示的に最適化するために使用されたものではなく、日本語での性能評価に重点を置いて選択されたものである。このようなアプローチは、提案手法の汎化性能を検証する上で有効であると考えられる。ただし、評価指標の多様性と個々のタスクの重要度を考慮する余地があることも指摘できる。例えば、JP-LMEHベンチマークでは、タスクの難易度や重要度に応じた重み付けを行うことで、より適切な総合評価が可能になるかもしれない。また、日本語以外の言語での性能評価や、他の評価指標(例: 人間評価)の導入なども、提案手法の有効性を多角的に検証する上で重要である。
以上の分析から、本論文で使用された評価指標は、提案手法の性能を日本語に重点を置いて評価するために選択されたものであり、ある程度の妥当性を持っていると考えられる。ただし、評価指標の多様性や個々のタスクの重要度を考慮する余地があり、結果の信頼性と一般化可能性についても、より詳細な分析が求められる。今後の研究では、より多様な評価指標を用いた検証や、統計的有意差の検定、モデルの汎化性能と過学習のリスクについての分析が望まれる。また、より大規模かつ多様なデータセットを用いた実験を通して、提案手法の有効性を検証することが重要である。
提案手法の限界と課題の分析
本論文の提案手法は、進化的アルゴリズムを用いたモデルマージングの自動化という新しいアプローチを示したが、同時にいくつかの理論的限界と課題も抱えている。これらの問題を深く理解し、解決策を探ることは、手法の性能と発展可能性を高める上で不可欠である。
提案手法の理論的限界として、まずマージ元モデルの品質に依存する問題が挙げられる。生成されるモデルの性能は、マージ元モデルの性能に大きく左右されるため、低品質なモデルを用いた場合、期待した結果が得られない可能性がある。この問題の原因は、生成モデルの性能がマージ元モデルの性能に強く依存することにある。この限界は、生成モデルの性能を低下させる恐れがある。
さらに、生成されたモデルの解釈可能性と制御可能性の問題も、信頼性や安全性の観点から重要である。モデルの内部動作が不透明であれば、予期しない動作やバイアスが生じる可能性があり、実社会での活用が困難になる。この問題の原因は、マージングによって生成されたモデルの内部構造や動作原理が複雑化することにある。解釈可能性や制御可能性の欠如は、モデルの信頼性や安全性を低下させ、実用化の障壁となる可能性がある。
この記事が気に入ったらサポートをしてみませんか?