Updating the Database from a Browser Using Streamlit

I wanted to create a mechanism to edit data in the browser using Streamlit and save the edited data to the database, but it didn't work well.
After some investigation, I found out that sessions were involved, so I wrote this article as a memo. Please note that I have little experience with web application development, so my understanding of sessions may be inaccurate and there might be some errors.
First, to prepare an interactive (editable in the browser) dataframe, use the following method:
st.data_editor(data, num_rows="dynamic" or "fixed")
dynamic allows adding or deleting rows.
fixed does not allow the above actions (default value).
First, Create a Simple Database (used for an English vocabulary app))
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Text
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import sessionmaker
import datetime
Base = declarative_base()
class Word(Base):
__tablename__ = 'words'
id = Column(Integer, primary_key=True, autoincrement=True)
word = Column(String, unique=True)
meaning = Column(Text, default="")
sentence = Column(Text, default="")
last_sent = Column(DateTime, default=datetime.datetime.min)
DATABASE_URL = "sqlite:///words.db"
engine = create_engine(DATABASE_URL)
Base.metadata.create_all(engine)
SessionLocal = sessionmaker(bind=engine)
def get_session():
return SessionLocal()
if __name__ == "__main__":
session = get_session()
for i in range(10):
session.add(Word(word=f"test{i}", meaning=f"test{i}", sentence=f"test{i}"))
session.commit()
session.close()
Create a Page
import streamlit as st
import sqlite3
import pandas as pd
from database import get_session, Word
st.title('Streamlit')
st.write('This page shows data from database.')
# Connect to the database
conn = sqlite3.connect("words.db")
df = pd.read_sql("SELECT * FROM words", conn)
# allow the user to add and delete rows
st.data_editor(df, num_rows="dynamic")Edit
However, if you reload the page, the data will revert to the original state. Therefore, you need to save the edited data to the database.
Simply Try the Following Code
import streamlit as st
import sqlite3
import pandas as pd
st.title('Streamlit')
st.write('This page displays data from the database.')
# Connect to the database
conn = sqlite3.connect("words.db")
df = pd.read_sql("SELECT * FROM words", conn)
edited_df = st.data_editor(df, num_rows="dynamic")
edited_df.to_sql("words", conn, if_exists="replace", index=False)
Oh? Did it work?
But there are some strange behaviors...
f you edit two places, the changes to the first part are saved, but the changes to the second part temporarily disappear.
This is something you might not notice unless you understand the following points. I thought I had read the official documentation, but it didn’t mention saving the edited dataframe, which was a bit confusing. It might have been mentioned somewhere though...
I felt somewhat relieved to find others in the Streamlit Community struggling with similar issues.
Key Points
Streamlit re-runs the script every time a user takes an action.
st.data_editor returns the edited dataframe upon re-execution.
st.data_editor compares the initial data with the edited data and reflects the changes. However, if the initial data itself is changed, the session is reset.
Understanding these points is crucial.
To investigate the behavior, I added some print statements:
Execution Results
Immediately After Startup
読み込み
表示
df
id word meaning sentence last_sent
0 1 test0 test0 test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
edited_df
id word meaning sentence last_sent
0 1 test0 test0 test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
保存
The script runs from top to bottom, so it loads and saves the data when the browser is launched. Of course, it saves the data without any edits. This means it’s saving the loaded data as is, which doesn’t make much sense.
Here, Edit the Dataframe in the Browser
Considering "1. Streamlit re-runs the script every time a user takes an action," you might think the same dataframe would be displayed even if you edit it. But in reality, it’s different.
読み込み
表示
df
id word meaning sentence last_sent
0 1 test0 test0 test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
edited_df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
保存
The script runs from top to bottom again, but the loaded data is the same as the initial data, while the edited_df has the edited data from before the script was re-executed. At this point, it saves the edited data.
Managing Session State: st.data_editor uses internal session state to maintain the edited data. This state persists across script re-runs.
Managing Session State: st.data_editor uses internal session state to maintain the edited data. This state persists across script re-runs.
Updating and Displaying Data: When a user edits data, the changes are saved in the session state. When the script re-runs, st.data_editor references both the initial data and the session state, displaying the edited data.
Now the database has the data with the string "aaa" saved.
What happens if you edit another part? For example, enter "aaa" in the meaning of the second row. Intuitively, you would expect edited_df to look like this:
edited_df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 aaa test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
But in reality, it looks like this:
読み込み
表示
df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
edited_df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
保存
Oh? The pre-edit edited_df is displayed! Why?
st.data_editor returns the edited dataframe upon re-execution.
st.data_editor compares the initial data with the edited data and reflects the changes. However, if the initial data is changed, the session state data is reset.
Because the initial sample_df was changed, the edited_df was also reset, and the previous changes (e.g., entering "aaa" in the second row) were lost.
To visualize this, I created the following code.
import streamlit as st
import pandas as pd
st.title('Streamlit')
st.write('This page displays data from the database.')
init = pd.DataFrame({
'A': [1, 2, 3],
'B': [10, 20, 30]
})
if st.button('Add row'):
init = pd.DataFrame({
'A': [1, 5, 10],
'B': [10, 20, 30]
})
print("これが初期状態だよ")
print("id:", id(init))
print(init)
edited = st.data_editor(init)
print("これが編集後だよ")
print(edited)
出力
# 起動時
これが初期状態だよ
id: 4553969872
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 1 10
1 2 20
2 3 30
# 1回目の編集
これが初期状態だよ
id: 4383547344
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 111111 10
1 2 20
2 3 30
# 2回目の編集
これが初期状態だよ
id: 4383548448
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 111111 10
1 222222 20
2 3 30
# 3回目の編集
これが初期状態だよ
id: 4552336800
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 111111 10
1 222222 20
2 333333 30
The initial values remain the same.
Changes made in the 2nd and 3rd iterations are based on the latest state after user modifications.
Now, press the button:
これが初期状態だよ
id: 4552329600
A B
0 1 10
1 5 20
2 10 30
これが編集後だよ
A B
0 1 10
1 5 20
2 10 30
The edited_df has been overwritten.
The changes held until now have been reset.
From the above, it becomes clear how st.data_editor works (in terms of maintaining data across sessions):
Session data is maintained only if the initial data remains the same.
If the initial data is changed, the session data is lost.
Improvement
Method 1: Using st.session_state
Using st.session_state to store the initial dataframe ensures that the same initial data is used across re-runs.
import streamlit as st
import sqlite3
import pandas as pd
st.title('Streamlit')
st.write('This page displays data from the database.')
# Connect to the database
conn = sqlite3.connect("words.db")
if 'df' not in st.session_state:
df = pd.read_sql("SELECT * FROM words", conn)
st.session_state["df"] = df
# allow the user to add and delete rows
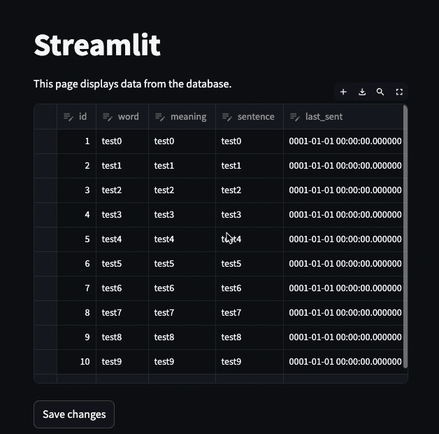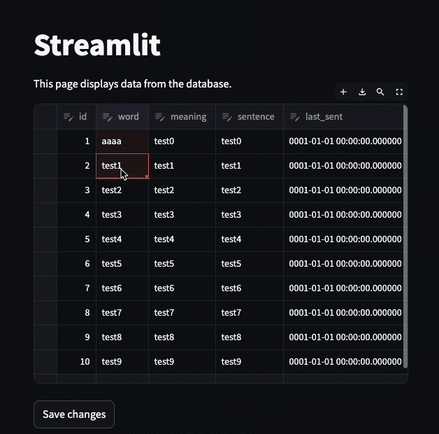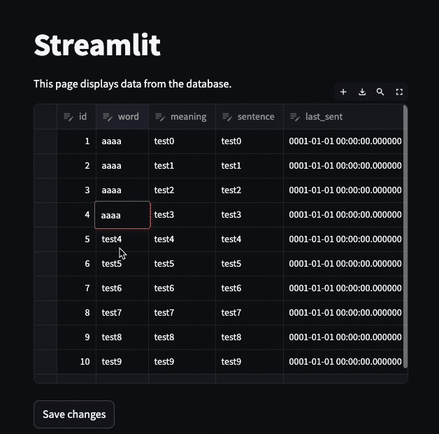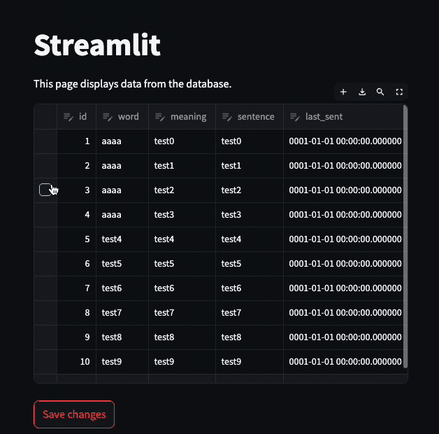
edited_df = st.data_editor(st.session_state["df"], num_rows="dynamic")
if st.button("Save changes"):
edited_df.to_sql("words", conn, if_exists="replace", index=False)
Trying Out st.cache_resource
st.cache_resource ensures that the database is read only once, maintaining consistent initial data for the session.
st.cache_data is the recommended method for caching computations that return data, such as loading a DataFrame from a CSV, transforming a NumPy array, querying an API, or other functions that return serializable data objects (str, int, float, DataFrame, array, list, etc.). A new copy of the data is created with each function call, making it safe against mutations and race conditions. In most cases, the behavior of st.cache_data is desirable. If you are unsure, start with st.cache_data to see if it works for you.
st.cache_resource is the recommended method for caching global resources, such as ML models or database connections, which you do not want to reload multiple times and cannot be serialized. Using this, you can share these resources across all reruns and sessions of the app without copying or duplicating them. Note that modifying the cached return value directly changes the object in the cache (see the details here).
I thought using st.cache_resource might work because it ensures the database is read only once, maintaining consistent initial data for the session.
import streamlit as st
import sqlite3
import pandas as pd
@st.cache_resource
def read_from_db():
conn = sqlite3.connect("words.db")
return pd.read_sql("SELECT * FROM words", conn)
st.title('Streamlit')
st.write('This page displays data from the database.')
# Connect to the database
conn = sqlite3.connect("words.db")
df = read_from_db()
print(df)
edited_df = st.data_editor(df, num_rows="dynamic")
# allow the user to add and delete rows
if st.button("Save changes"):
edited_df.to_sql("words", conn, if_exists="replace", index=False)
The above code seems to work similarly to the previous one. The initial data saved in the session remains the same, allowing it to work correctly. However, it has some drawbacks:
Page Reload
Reloading the page clears the session. However, the cache remains, so the database is not reloaded. This means the data is the same as when the page was first loaded with no modifications.
As a result:
The session data referenced by st.data_editor is reset. Consequently, st.data_editor saves the initial data to the session again. This initial data is the unmodified data from the cache.
When the page is reloaded, the previous edits are lost, reverting to the initial state.
However, the database is updated.
Clearing the cache and reloading the page displays the edited data because the database is reloaded after the cache is cleared.
Conclusion
Without understanding sessions and caching, it was difficult to identify the cause of the problem and why it occurred.
I have been using Python for about 8 years, primarily for hobby machine learning projects, and have little knowledge of web applications.
I have created simple web apps with Django, but I had never created something that required understanding the concepts mentioned above.
This troubleshooting experience has been very educational.
Note: The information about sessions and caching discussed in this article was gathered for troubleshooting purposes, and I am not entirely confident in its accuracy. If there are any mistakes, I would appreciate any corrections in the comments.
この記事が気に入ったらサポートをしてみませんか?