Streamlitを使ってブラウザからデータベースの更新を行いたい

Streamlitを使ってブラウザ上でデータを編集、編集したデータをデータベースに保存するという仕組みを作りたかったけど、なんかうまくいかない
いろいろ調べた結果セッションが関係していることがわかり、備忘録として記事にしました。以下、Webアプリ開発経験に乏しいためセッションについての情報、理解が正直自信がないため、所々間違っている箇所があるかもしれません。
まずインタラクティブな(ブラウザ上で編集可能な)データフレームを用意するには以下のメソッドを使います。
st.data_editor(data, num_rows="dynamic" or "fixed")
dynamic 行の追加や削除を許可します。 fixed 上記を許可しません。(デフォルト値はこっち)
まず簡単なデータベースを作成(英単語アプリで使用していたもの)
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Text
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import sessionmaker
import datetime
Base = declarative_base()
class Word(Base):
__tablename__ = 'words'
id = Column(Integer, primary_key=True, autoincrement=True)
word = Column(String, unique=True)
meaning = Column(Text, default="")
sentence = Column(Text, default="")
last_sent = Column(DateTime, default=datetime.datetime.min)
DATABASE_URL = "sqlite:///words.db"
engine = create_engine(DATABASE_URL)
Base.metadata.create_all(engine)
SessionLocal = sessionmaker(bind=engine)
def get_session():
return SessionLocal()
if __name__ == "__main__":
session = get_session()
for i in range(10):
session.add(Word(word=f"test{i}", meaning=f"test{i}", sentence=f"test{i}"))
session.commit()
session.close()
ページを作成
import streamlit as st
import sqlite3
import pandas as pd
from database import get_session, Word
st.title('Streamlit')
st.write('This page shows data from database.')
# Connect to the database
conn = sqlite3.connect("words.db")
df = pd.read_sql("SELECT * FROM words", conn)
# allow the user to add and delete rows
st.data_editor(df, num_rows="dynamic")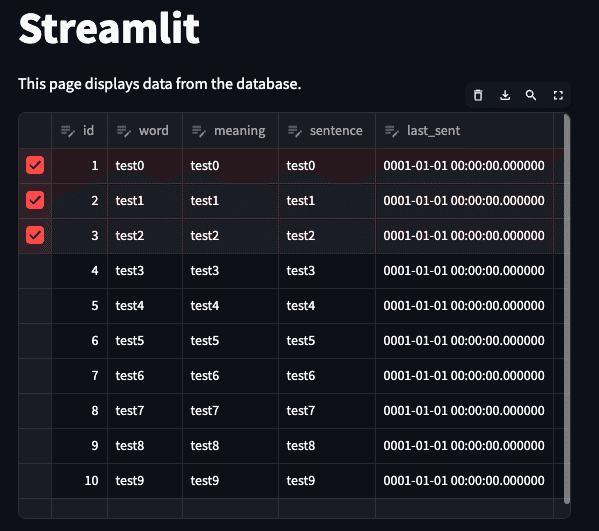
編集を加える

でもこれだとページをリロードすると元のデータに戻ってしまうので、 編集を加えたものをデータベースに保存する必要がある
単純に以下のコードにしてみる
import streamlit as st
import sqlite3
import pandas as pd
st.title('Streamlit')
st.write('This page displays data from the database.')
# Connect to the database
conn = sqlite3.connect("words.db")
df = pd.read_sql("SELECT * FROM words", conn)
edited_df = st.data_editor(df, num_rows="dynamic")
edited_df.to_sql("words", conn, if_exists="replace", index=False)

あれ?いけたんじゃね?
でもちょっと変な挙動が・・・
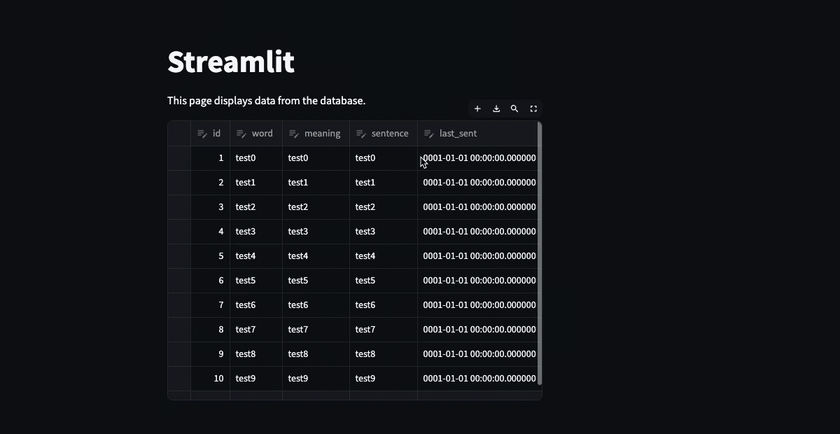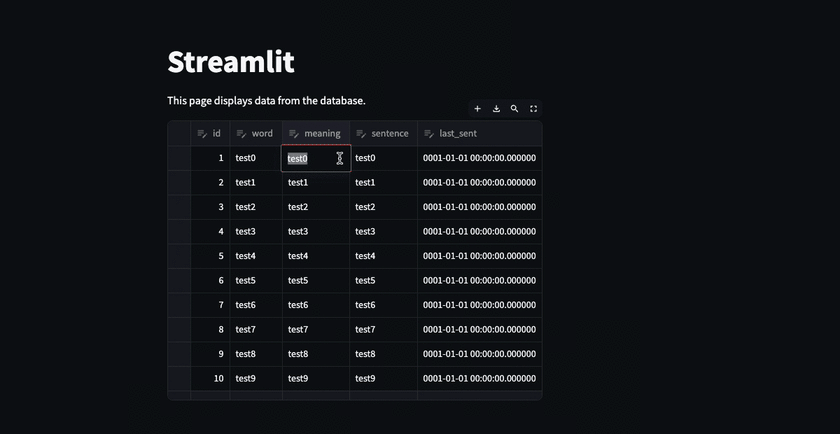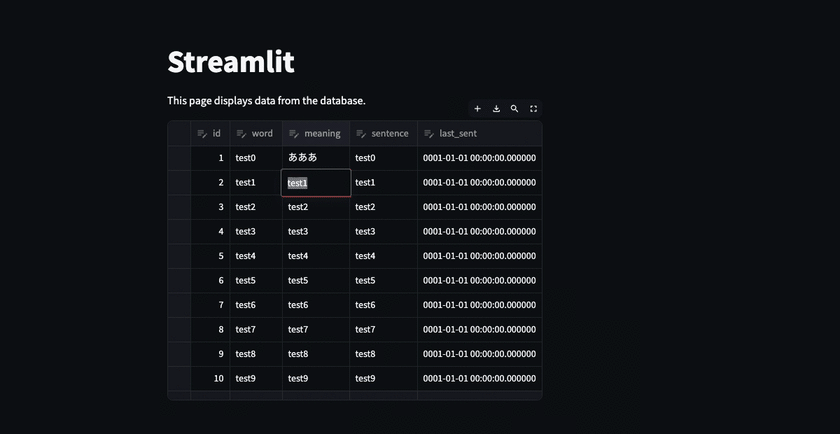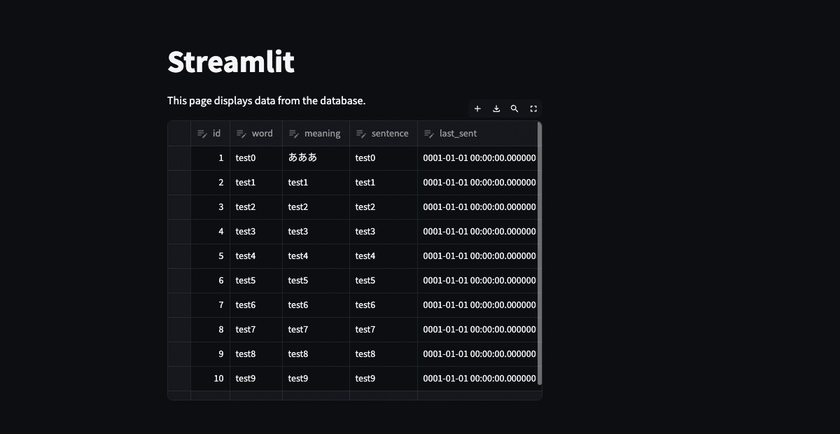
2箇所編集した場合に、 最初に編集した部分は変更が保存されるが2箇所目は一旦消える。
これは以下の内容を理解しておかないと気付けない部分で自分はここで沼にハマった。 公式ドキュメントは読んでいたつもりだけど、編集したdataframeを保存する内容に関しては書かれていないくて、ちょっと困った。 ※どっかのページにあったのかもしれないけど・・・
StreamlitのCommunityでもどうようの事象で悩んでいる仲間を見つけて、ちょっと安心した
重要なポイント
Streamlitはユーザーがアクションを起こすたびにスクリプトを再実行する
st.data_editorは再実行時にユーザーが編集したデータフレームを返す
st.data_editorは初期データと編集データを比較して変更を反映します。ですが、初期データそのものに変更があるとセッションはリセットされます。
上記2点を理解しておく必要があった。
挙動を調べるためにprintを入れてみた
import streamlit as st
import sqlite3
import pandas as pd
st.title('Streamlit')
st.write('This page displays data from the database.')
# Connect to the database
conn = sqlite3.connect("words.db")
print("読み込み")
df = pd.read_sql("SELECT * FROM words", conn)
print("表示")
# allow the user to add and delete rows
print("df\n", df)
edited_df = st.data_editor(df, num_rows="dynamic")
print("edited_df\n",edited_df)
print("保存")
edited_df.to_sql("words", conn, if_exists="replace", index=False)
実行結果
起動直後
読み込み
表示
df
id word meaning sentence last_sent
0 1 test0 test0 test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
edited_df
id word meaning sentence last_sent
0 1 test0 test0 test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
保存
スクリプトは上から下まで実行しているため、ブラウザの起動とともに読み込み、保存まで実行している。もちろん、何も編集していないデータを保存している。 つまり、読み込んだデータをそのまま保存するという、何の意味があるの?ってことをしている。
ここでブラウザのデータフレームに編集を加えてみる
ここで「1. Streamlitはユーザーがアクションを起こすたびにスクリプトを再実行する」を考えると、編集しても同じデータフレームが表示されちゃうんじゃない?って思うが実際は違う。
読み込み
表示
df
id word meaning sentence last_sent
0 1 test0 test0 test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
edited_df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
保存
スクリプトがまた上から下まで実行される。が、 読み込んだデータは最初のデータと全く同じだが、変化があるのはedited_dfの方。 edited_dfはスクリプトが再実行される前のユーザーが編集したデータフレームを表示している。また、このタイミングで編集したデータを保存している
セッション状態の管理: st.data_editorは内部でセッション状態を使用して、ユーザーが編集したデータを保持します。この状態は、スクリプトの再実行間で維持されます。
データの更新と表示: ユーザーが編集を行うと、その変更はセッション状態に保存されます。スクリプトが再実行されると、st.data_editorは初期データ(sample_df)とセッション状態の両方を参照し、ユーザーの編集を反映したデータを表示します。
ここでDBには"aaa"という文字列が入ったデータが保存された。
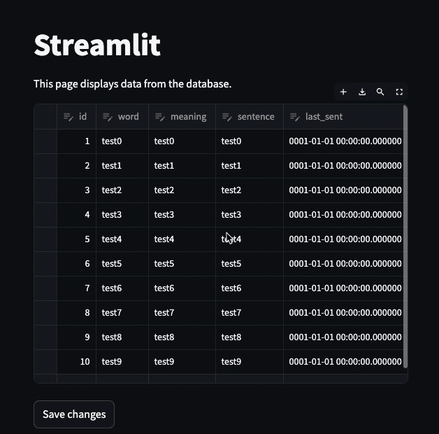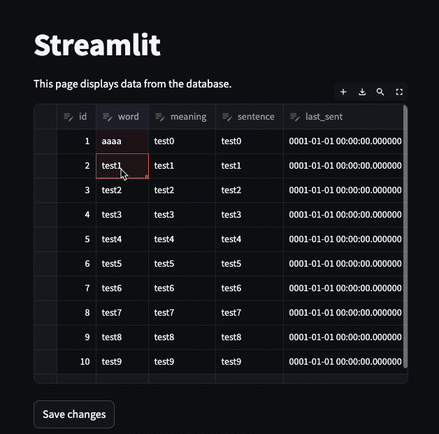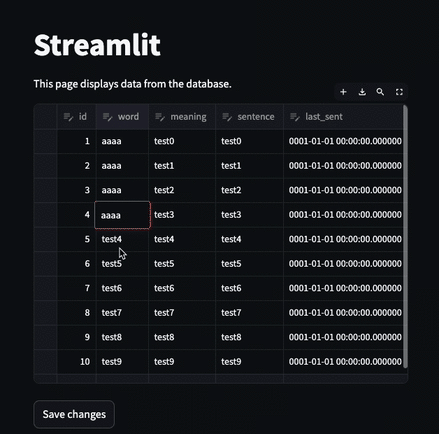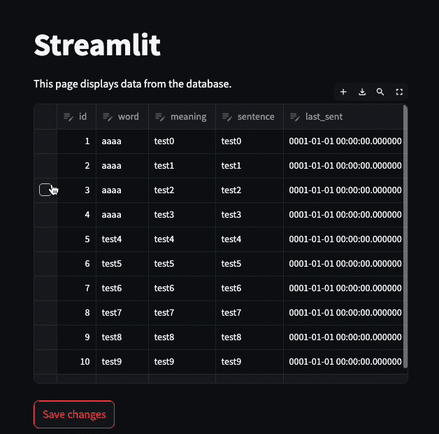
そして、このままもう1箇所のデータを編集するとどうなるか? 2行目のmeaningにaaaと入力してみた。 直感的な期待としてはedited_dfが以下のようになってほしい
edited_df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 aaa test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
けど実際は
読み込み
表示
df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
edited_df
id word meaning sentence last_sent
0 1 test0 aaa test0 0001-01-01 00:00:00.000000
1 2 test1 test1 test1 0001-01-01 00:00:00.000000
2 3 test2 test2 test2 0001-01-01 00:00:00.000000
3 4 test3 test3 test3 0001-01-01 00:00:00.000000
4 5 test4 test4 test4 0001-01-01 00:00:00.000000
5 6 test5 test5 test5 0001-01-01 00:00:00.000000
6 7 test6 test6 test6 0001-01-01 00:00:00.000000
7 8 test7 test7 test7 0001-01-01 00:00:00.000000
8 9 test8 test8 test8 0001-01-01 00:00:00.000000
9 10 test9 test9 test9 0001-01-01 00:00:00.000000
保存
となってしまう。
あれ?編集前のedited_dfが出ちゃうじゃん!なんで!
st.data_editorは再実行時にユーザーが編集したデータフレームを返す
st.data_editorは初期データと編集データを比較して変更を反映します。です が、初期状態のデータが変更されるとセッションで保存していたデータをリセットする。
初期状態sample_dfが変更されてしまったがために、edited_dfもリセットされて、1個前の変更情報(二行目にaaaと入れた編集情報)が消えてしまったということです。
上記を視覚的にみるために以下のようなコードを作成した。
import streamlit as st
import pandas as pd
st.title('Streamlit')
st.write('This page displays data from the database.')
init = pd.DataFrame({
'A': [1, 2, 3],
'B': [10, 20, 30]
})
if st.button('Add row'):
init = pd.DataFrame({
'A': [1, 5, 10],
'B': [10, 20, 30]
})
print("これが初期状態だよ")
print("id:", id(init))
print(init)
edited = st.data_editor(init)
print("これが編集後だよ")
print(edited)
出力
# 起動時
これが初期状態だよ
id: 4553969872
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 1 10
1 2 20
2 3 30
# 1回目の編集
これが初期状態だよ
id: 4383547344
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 111111 10
1 2 20
2 3 30
# 2回目の編集
これが初期状態だよ
id: 4383548448
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 111111 10
1 222222 20
2 3 30
# 3回目の編集
これが初期状態だよ
id: 4552336800
A B
0 1 10
1 2 20
2 3 30
これが編集後だよ
A B
0 111111 10
1 222222 20
2 333333 30
初期状態の値は常に一緒
2,3回目の変更もユーザーが変更した最新状態の続きから実行してくれている。
ここでボタンを押してみます。
これが初期状態だよ
id: 4552329600
A B
0 1 10
1 5 20
2 10 30
これが編集後だよ
A B
0 1 10
1 5 20
2 10 30
edited_dfが書き換わってしまいました。
これまで保持していた変更がリセットされてしまいました。
上記からわかるst.data_editorの仕組み(セッション間のデータ維持に関する仕組み)
セッションでデータを保持するのは初期状態のデータが同じであること ※ 初期状態が変更されるとセッションで保持していたデータは失われる
図にまとめてみた。

改善
方法1 st.session_stateを利用する
import streamlit as st
import sqlite3
import pandas as pd
st.title('Streamlit')
st.write('This page displays data from the database.')
# Connect to the database
conn = sqlite3.connect("words.db")
if 'df' not in st.session_state:
df = pd.read_sql("SELECT * FROM words", conn)
st.session_state["df"] = df
# allow the user to add and delete rows
edited_df = st.data_editor(st.session_state["df"], num_rows="dynamic")
if st.button("Save changes"):
edited_df.to_sql("words", conn, if_exists="replace", index=False)

試してみた
st.cache_resourceというものがあった。
以下は公式HPのGoogle翻訳(ちょっと日本語変)
st.cache_data は、CSV から DataFrame をロードしたり、NumPy 配列を変換したり、API をクエリしたり、シリアル化可能なデータ オブジェクト (str、int、float、DataFrame、配列、リストなど) を返すその他の関数など、データを返す計算をキャッシュするための推奨される方法です。関数呼び出しごとにデータの新しいコピーが作成されるため、大きな変更や競合状態に対して安全です。 の動作はst.cache_dataほとんどの場合に望ましい動作です。よくわからない場合は、 st.cache_data から始めて動作するかどうかを確認してください。 st.cache_resource は、ML モデルやデータベース接続などのグローバル リソース (複数回読み込みたくないシリアル化できないオブジェクト) をキャッシュするための推奨される方法です。これを使用すると、コピーや複製を行わずに、アプリのすべての再実行とセッションでこれらのリソースを共有できます。キャッシュされた戻り値を変更すると、キャッシュ内のオブジェクトが直接変更されることに注意してください (詳細は以下を参照)。
st.cache_resourceを使えばDBの読み込みが1回になるからセッションの初期データが常に同じになるからうまくいくんじゃないか?と思った。
import streamlit as st
import sqlite3
import pandas as pd
@st.cache_resource
def read_from_db():
conn = sqlite3.connect("words.db")
return pd.read_sql("SELECT * FROM words", conn)
st.title('Streamlit')
st.write('This page displays data from the database.')
# Connect to the database
conn = sqlite3.connect("words.db")
df = read_from_db()
print(df)
edited_df = st.data_editor(df, num_rows="dynamic")
# allow the user to add and delete rows
if st.button("Save changes"):
edited_df.to_sql("words", conn, if_exists="replace", index=False)
上記のコードは一見すると先のコードと同じように動作しました。 常にセッションに保存された初期データが同じであるため、うまく動作しているようでした。 ですが、以下の点でうまくいかなくなります。
ページの再読み込み
ページを再読み込みするとそれまでのセッションが消えます。 ですが、キャッシュは残っているため、データベースの再読み込みをしません。 つまり、このページを最初に読み込んだときのまだ何も手を加えられていない最初のデータになります。
するとどうなるか?
st.data_editorが参照していたセッションデータがリセットされます。 すると、st.data_editorは再度セッションに初期データを保存します。 その初期データはなにか?というと、キャッシュにあるなにも手を加えていないデータです。
再読み込みをしたら、これまでの編集が消え、最初の状態に戻ってしまいました。
ですが、データベースは更新されています。
なのでキャッシュクリアをしてページを再読み込みしてみると、 なんと編集後のデータが表示されました。 キャッシュが消えたので、データベースを再読み込みしたからです。
まとめ
セッション、キャッシュ等を理解していないと、今回の問題がなぜ起こるのか、 原因は何なのかになかなか気付くことができませんでした。
私は8年くらいPythonを使ってきましたが、おもに趣味で機械学習をする程度なため、Webアプリへの知識は乏しい。
WebアプリはDjangoで簡単なものは作りましたが、上記の内容を理解していなければ作れないようなものは作成したことがなかった。
今回のトラブルはとても勉強になった。
※この記事で解説したセッションやキャッシュに関しての情報は今回のトラブル解決のために調べた程度で正直自信がないです。 もし、間違っているのであれば、コメントでご教示頂けると幸いです。
この記事が気に入ったらサポートをしてみませんか?