

【マイグレーションTips】Cのプログラム移植/移植後に見つかる潜在バグ例(HP-UX→Linux)

はじめに
皆さん、こんにちは。
株式会社SHIFT 技術統括部 マイグレーションGの村田です。
主にお客様が使用するコンピュータシステムのマイグレーション作業支援を担当しています。
マイグレーションTipsと題して、今後マイグレーション作業を行う技術者に向けて役に立つと考えられる情報を選んで紹介してまいります。
※「マイグレーションって何?」と思われた方は、前回の記事で説明していますので先にお読み頂ければ幸いです。
執筆者プロフィール:村田 博之
IT業界に入って40年突破。データベース関連ミドルウェアの開発・保守(20年間)やメインフレームおよびオープン環境での社内システム開発・保守SE(合計19年間)に従事した後、SHIFTに⼊社。
現在は数々の案件対応で蓄積した知⾒と経験を活かして、マイグレーション関連のプロジェクトに参画している。
【現象】CのプログラムをHP-UXからLinuxへ移植したら、ファイル出力件数が一致しなかった!
今回紹介するマイグレーションTipsも前回に引き続き、C言語のプログラムを移植する時に遭遇した問題への解決方法です。
システム:HP-UX→RedHat Linuxへのマイグレーション
言語:C言語
コンパイラ:HP-UX/Cコンパイラ → RedHat Linux/gcc
事象:HP-UXで稼働中のプログラムソースをRedHat Linuxに移植。同じデータでテストしたら、ファイル出力件数が一致しなかった。
調査した結果、ファイル抽出の条件分岐にてHP-UXとRedhat Linuxで判定結果が変わるデータがあり、現新比較で不一致が発生。
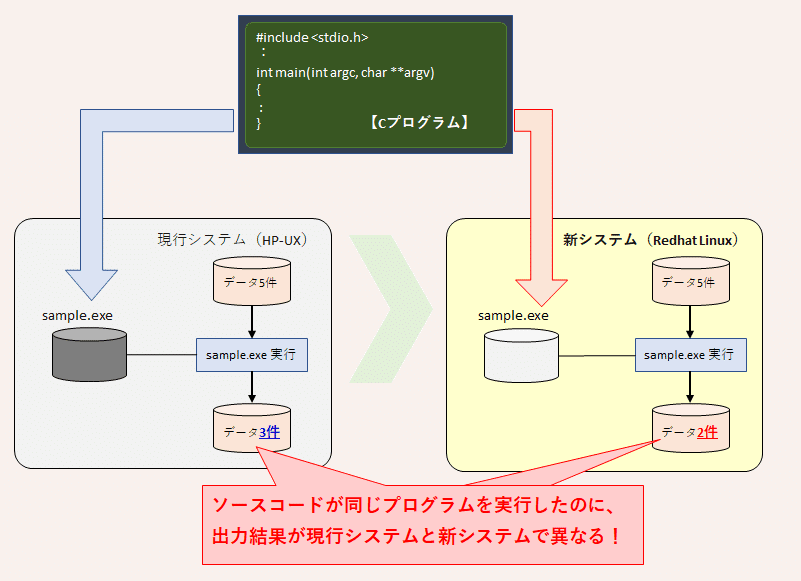
同じデータで同じ条件分岐のコードなのに、動作が異なる事態に遭遇すると移植手順に間違いがあったのかと振り返ってしまいます。しかし今回の事例はそうではありませんでした。
簡単なサンプルコードで説明しましょう。
-- main.c --
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct fileFM { /* ファイルフォーマット */
char keyname[8]; /* キー */
int status; /* ステータス 0:無効 1:有効 */
char comment[20]; /* コメント */
}
/* 第1引数:入力ファイル名 */
/* 第2引数:出力ファイル名 */
/* 第3引数:抽出キー */
int main(int argc, char **argv)
{
int i_cnt = 0; /* 入力件数 */
int o_cnt = 0; /* 出力件数 */
FILE *fp_i; /* 入力ファイルポインタ */
FILE *fp_o; /* 出力ファイルポインタ */
struct fileFM w_buf; /* バッファ */
if ((fp_i = fopen64(argv[1], "r")) == NULL) {
/* 入力ファイルopen */
fprintf(stderr, "input-file open error\n");
exit(9);
}
if ((fp_o = fopen64(argv[2], "w")) == NULL) {
/* 出力ファイルopen */
fprintf(stderr, "output-file open error\n");
fclose(fp_i);
exit(9);
}
while((fread(&w_buf, sizeof(w_buf), 1, fp_i)) == 1) {
/* 入力ファイルを1件ずつ読み込み */
i_cnt++; /* 入力件数をインクリメント */
if (strcmp(w_buf.keyname, argv[3]) == 0) {
/* 抽出キーが一致? */
if(fwrite(&w_buf, sizeof(w_buf), 1, fp_out) != 1) {
/* 出力ファイルに出力 */
fprintf(stderr, "file write error\n");
fclose(fp_i);
fclose(fp_o);
exit(9);
}
o_cnt++; /* 出力件数をインクリメント */
}
} /* while */
fclose(fp_i); /* 入力ファイルclose */
fclose(fp_o); /* 出力ファイルclose */
fprintf(stdout, "抽出キー :%s\n", argv[3]);
fprintf(stdout, "%s : %d 件入力\n", argv[1], i_cnt);
fprintf(stdout, "%s : %d 件出力\n", argv[2], o_cnt);
/* 処理結果表示 */
exit(0);
}あるファイルから、キーが一致するレコードを抽出して別のファイルに書き出す簡単なプログラムです。
Linuxにプラットフォームを変えても問題なくコンパイルできました。
そしてテストしてみたのですが…

同じデータを入力したのにHP-UXでは3件、Linuxでは2件と出力結果が変わってしまいました。
プログラムを見直したものの、一見どこも悪いようには見えません。
一体何が起きたのでしょうか。
【原因】NULL終端の考慮漏れ潜在バグが顕在化!エンディアンの違いが要因
本件はNULL終端の考慮漏れによる潜在バグの発現でした。
<バグの内容>
構造体のメンバに定義した文字列領域のサイズが、NULL終端文字を考慮していません。
C言語を使う方にはおなじみの内容ですが、文字列のコピーや比較などをstring系関数で行う場合、文字列の最後にNULL終端(\0)が入っていることが前提です。
サンプルコードでは、抽出キーを比較する所でstrcmp関数を使っていました。
if (strcmp(w_buf.keyname, argv[3]) == 0) {
/* 抽出キーが一致? */構造体 w_bufのメンバ keynameのサイズは8バイトです。
struct fileFM { /* ファイルフォーマット */
char keyname[8]; /* キー */
int status; /* ステータス 0:無効 1:有効 */
char comment[20]; /* コメント */
}入力データを見ると keynameには"ABC17001"など、8バイトすべてに文字が格納されています。すなわちNULL終端は含まれていません。
でもHP-UXでは正しく動いているように見えました。なぜでしょう?
ここで登場するのが「エンディアン」(バイトオーダとも呼ぶ)です。
IT用語辞典では、以下のとおり定義されています。
「エンディアンとは、複数のバイト(多バイト、マルチバイト)で構成されるデータを記録・伝送する際に、どのような順番で各バイトを記録・伝送するかを表す順序のこと。」
出典:IT用語辞典 e-words
https://e-words.jp/w/エンディアン.html
エンディアンは、short, int, longなどの型を持つ数値をメモリに格納する際に影響があります。そしてプラットフォームによりエンディアンが異なります。
ビッグエンディアンのプラットフォーム
HP-UX, AIX, Soralis(sparc)リトルエンディアンのプラットフォーム
Linux, Windows, Soralis(x64)
HP-UXからLinuxへの移植では、エンディアンがビッグからリトルに変わります。 今回Linuxで出力されなかった「commentが"testdata3"」のデータに着目して、構造体 w_buf のメモリ内容を確認してみましょう。

HP-UX
keynameの後続にあるメモリ内容は0x00Linux
keynameの後続にあるメモリ内容は0x01
構造体 w_buf の各メンバは、メモリ上では連続領域で配置されます。
keynameの後ろにあるstatusはint型の変数で、ビッグエンディアンでは0x00000001、リトルエンディアンでは0x01000000で格納します。
そのためkeynameに対してNULL終端まで文字列として取り扱おうとすると、Linuxでは"ABC17001'0x01'"になりました。
この状態で抽出キー "ABC17001"でstrcmp関数を実行すると…
HP-UX
keyname "ABC17001" = 抽出キー "ABC17001"Linux
keyname "ABC17001'0x01'" ≠ 抽出キー "ABC17001"
strcmp関数の結果として、HP-UXでは一致してもLinuxでは不一致という状態が発生。プログラムのファイル出力結果に影響を与えてしまいました。
【対策】文字列領域に対するNULL終端文字の取り扱いを点検する
この問題の対策は、文字列領域のサイズと使われ方を確認することに尽きます。
[対策1] 文字列領域のサイズを増やす
一番シンプルな対策です。NULL終端文字を格納する分も含めて領域を確保するよう修正します。
※1バイト増やせば要件は満たせるのですが、後続のメンバの型を見てバウンダリを意識した値とするのがベターです。
/* 対策例 */
struct fileFM { /* ファイルフォーマット */
char keyname[12]; /* キー */
/* ★8→12へ変更★ */
int status; /* ステータス 0:無効 1:有効 */
char comment[20]; /* コメント */
}[対策2] 文字列領域を参照/格納する際にNULL終端文字を含めないよう命令文を変更する
ファイルフォーマットに対応させた構造体のメンバに今回の問題があった場合、ファイルフォーマットの変更を伴う[対策1]の対策は、データの書き換えなど影響が大きく採用しにくくなります。
この場合は、文字列領域を参照/格納する命令文についてNULL終端文字を期待しない命令文に変更する対策が必要です。
strcmpやstrcpyなどのstring系関数には、文字列の最大長を指定できる関数(strncmp, strncpyなど)があるため、使用する関数を変えることで対策できます。
/* 対策例 */
if (strncmp(w_buf.keyname, argv[3], sizeof(w_buf.keyname)) == 0) {
/* 抽出キーが一致? */
/* ★ strcmpからstrncmpに変更 ★ */
/* ★ 第3引数に最大長を指定 ★ */[対策3] 別領域にコピーしてNULL終端文字を付加した後、参照するよう命令文を変更する
string系関数には[対策2]が有効ですが、printf系関数で指定する文字列の書式"%s"には、文字列の最大長を指定することができません。 この場合は、NULL終端文字を含められる別領域を用意して、その領域にコピーした後でprintf系関数で参照する形になります。
/* NGのケース */
fprintf(stdout, "抽出キー :%s\n", w_buf.keyname);
/* NULL終端が保証されていないため、文字列の最後にゴミが表示される */
/* 対策例 */
char p_keyname[9]; /* printf系関数向け作業領域 */
memset(p_keyname, 0x00, sizeof(p_keyname));
/* 9バイト領域を0x00クリア */
strncpy(p_keyname, w_buf.keyname, sizeof(w_buf.keyname));
/* ⇒8バイト分をコピー */
/* NULL終端が保証された */
fprintf(stdout, "抽出キー :%s\n", p_keyname);ちなみにprintf系関数の書式として"%8s"という指定がありますが、この指定は「8桁で表示打ち切り」ではなく、「8桁未満の文字列なら8桁分の表示枠を確保する」という意味になります。
9桁以上の文字列を表示すると、8桁を超えてもNULL終端文字まですべて表示するため、今回の対策には使えません。
間違った意味で使っているケースを良くみかけますので、今回の対策では使わないように注意して下さい。
文字列のNULL終端の取り扱いは、C言語を使う方にとっては必須の知識ですが、注意していてもバグを作りこんでしまっていることがあります。
メモリ配置に関するバグはソースコードからは見つけずらいため、調査に時間がかかります。
今回ご紹介したように、HP-UXでは「たまたま」動いていた処理がマイグレーションによりバグが顕在化するケースもあります。
NULL終端の考慮漏れ不具合は、バッファオーバーフローによるシステム攻撃の入口にもつながるので、新たなバグを作りこまないよう注意したいところです。
【派生】COBOLの考え方を継承したシステムのマイグレーションは特に注意!
マイグレーション対象システムは、顧客の業務支援として長期間稼働するシステムが多い傾向にあります。
最近では「COBOLで構築したシステムをC言語へ更改」して10年~20年以上運用したシステムをOSやハードウェアのサポート切れを契機にマイグレーションするという事例も増えてきました。
COBOLからC言語に移植する時、文字列を格納する領域はNULL終端を考慮して格納する文字列長+1バイトを格納できるようにコードを書くのが流儀です。
ただし、電文やファイルフォーマットを定義したCOBOLのCOPY句を構造体に書き換える時は、他システムとのインタフェースを変えないようにNULL終端なしを前提として文字列領域を設定している可能性があります。
<COBOL COPY句>
000100** ファイルフォーマット**
000100 05 FILEFM.
000200 10 KEYNAME PIC X(8).
000300 10 STATUS PIC S9(9) COMP.
000400 10 COMMENT PIC X(20).
↓
<C言語 構造体>
struct fileFM { /* ファイルフォーマット */
char keyname[8]; /* キー ★NULL終端は含まない */
int status; /* ステータス 0:無効 1:有効 */
char comment[20]; /* コメント */
}この時、NULL終端なし前提の文字列領域についてstring系の関数やprintf系関数の"%s"を使っているとその箇所はバグとなります。
このようなCOBOLの考え方を継承したC言語のシステムに対してマイグレーションを行う場合は、今回紹介したバグが隠れている確率が高いと考えられます。 移行作業において、ソースプログラムの点検を作業スケジュールの中に事前に組み込むことをお勧めします。
最後に
マイグレーションTipsとして「Cのプログラム移植/移植後に見つかる潜在バグ例(HP-UX→Linux)」をご紹介しましたが、いかがだったでしょうか。
Tipsは他にもありますので、随時ご紹介してまいります。
HP-UXは最新バージョン11iV3の販売が2023年12月末終了、通常サポートも2025年12月末終了と公表されたため、Linuxなど他プラットフォームへのマイグレーション案件が増えてきています。 マイグレーションに携わる技術者の皆さんに、この記事が目に留まり少しでも役立てて頂ければ幸いです。
マイグレーション支援サービスのご紹介
株式会社SHIFTでは、コンピュータシステムのマイグレーションを円滑に進めるための支援サービスを提供しています。
マイグレーションに関する支援サービスの詳細は以下のとおりです。
システムのマイグレーションをご検討、または課題解決に困っている方がいらっしゃったら、以下のページよりお気軽に問い合わせいただければ幸いです。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/