

OpenShift 4 のモニタリングスタックをさわってみた

『IT自動化の力でビジネス加速を全ての企業に』
”IT自動化の専門会社”、リアルグローブ・オートメーティッド(RGA) 技術ブログ編集部の馬塚です。
RGAでは Red Hat社が提供する、エンタープライズ向けコンテナプラットフォーム製品「OpenShift 」を利用したインフラ基盤環境の構築支援やコンテナアプリケーションの開発支援を提供しています。
OpenShift は、直接 Kubernetes を利用する場合に比べ、 GUI が整備されているため扱いやすく、コンテナ運用に関する様々な便利機能が追加されているため、コンテナ基盤の運用担当者にとって大変有用なツールです。
近年、クラウドネイティブ環境におけるオブザーバビリティ(可観測性)の重要性がよく指摘されますが、オブザーバビリティの向上のために、モニタリングの仕組みは不可欠です。
OpenShift 4でも、モニタリングスタックとして Prometheus と Grafana ダッシュボードのセットがデフォルトで提供されます。
また、監視状況に応じてアラート通知を行うための AlertManager コンポーネントも同梱されています。
今回は、編集部の私が Red Hat社の提供するオンラインLAB(OpenTLC)上でOpenShift 4.5を起動し、これらのコンポーネントを確認してみた結果をご紹介します。
――――――――――――――――――――――――――――――――――
デフォルトモニタリングスタックの全体像
OpenShiftにおけるデフォルトのモニタリングスタックは以下のようなコンポーネントで構成されます。
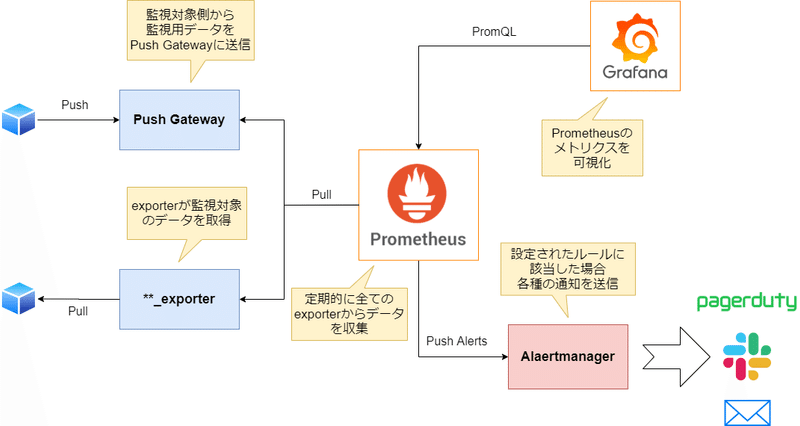
前述の通り、OpenShiftをインストールした時点で上図に記載された各コンポーネントが openshift-monitoring ネームスペースにデプロイされています。
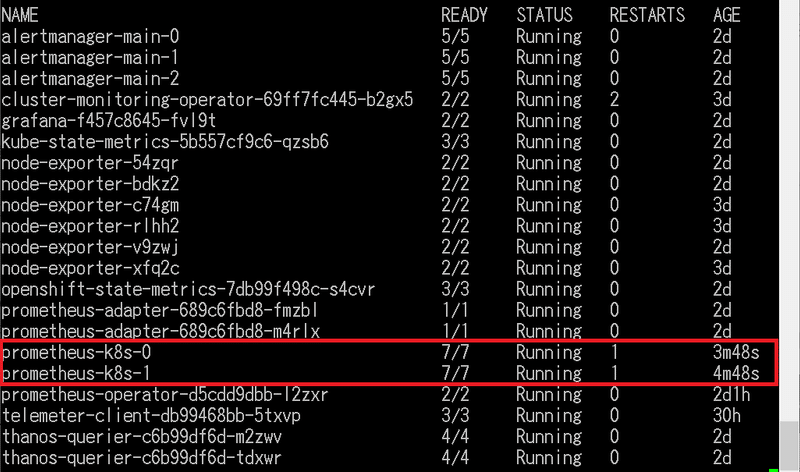
以下のようなPodが稼働していることが確認できます。
$ oc get pods -n openshift-monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 5/5 Running 0 24h
alertmanager-main-1 5/5 Running 0 24h
alertmanager-main-2 5/5 Running 0 24h
cluster-monitoring-operator-69ff7fc445-b2gx5 2/2 Running 2 2d
grafana-f457c8645-fvl9t 2/2 Running 0 24h
kube-state-metrics-5b557cf9c6-qzsb6 3/3 Running 0 24h
node-exporter-54zqr 2/2 Running 0 24h
node-exporter-bdkz2 2/2 Running 0 24h
node-exporter-c74gm 2/2 Running 0 2d
node-exporter-rlhh2 2/2 Running 0 2d
node-exporter-v9zwj 2/2 Running 0 24h
node-exporter-xfq2c 2/2 Running 0 2d
openshift-state-metrics-7db99f498c-s4cvr 3/3 Running 0 24h
prometheus-adapter-689c6fbd8-fmzbl 1/1 Running 0 24h
prometheus-adapter-689c6fbd8-m4rlx 1/1 Running 0 24h
prometheus-k8s-0 7/7 Running 1 24h
prometheus-k8s-1 7/7 Running 1 24h
prometheus-operator-d5cdd9dbb-l2zxr 2/2 Running 0 25h
telemeter-client-db99468bb-5txvp 3/3 Running 0 6h47m
thanos-querier-c6b99df6d-m2zwv 4/4 Running 0 24h
thanos-querier-c6b99df6d-tdxwr 4/4 Running 0 24hなお、node-exporter は、全てのノードに単一Podとしてデプロイされる Daemonset リソースで、対象ノードのCPU、メモリ、ネットワークなどに関するメトリクスを収集します。ここで収集された各ノードの情報を、PrometheusがPullする形となります。
各コンポーネントへのアクセス
インストールされている Prometheus、Grafana、AlertManager にアクセスするには、OpenShiftのWebコンソールで [Monitoring] メニューを開きます。

各サブメニューはそれぞれ以下のコンポーネントに連携しています。
・Alerting ⇒ AlertManager
・Metrics ⇒ Prometheus
・Dashboards ⇒ Grafana
また、以下のコマンドで各コンポーネントへアクセスするためのホスト名を取得することができます。※一部出力結果を省略しています。
$ oc get route -n openshift-monitoring
NAME HOST/PORT PORT
alertmanager-main alertmanager-main-openshift-monitoring.apps.cluster-0e67.sandbox526.opentlc.com web
grafana grafana-openshift-monitoring.apps.cluster-0e67.sandbox526.opentlc.com https
prometheus-k8s prometheus-k8s-openshift-monitoring.apps.cluster-0e67.sandbox526.opentlc.com web
thanos-querier thanos-querier-openshift-monitoring.apps.cluster-0e67.sandbox526.opentlc.com web 取得したホスト名を使用してそれぞれのWebコンソールにHTTPSでアクセスすることができます。
Grafanaでの可視化
OpenShift コンソールの [Monitoring] > [Dashboards] メニューでは、以下のようなモニタリング対象を指定してメトリクスを参照することができます。
・etcd
・Kubernetes / Compute Resources / Cluster
・Kubernetes / Compute Resources / Namespace (Pods)
・Kubernetes / Compute Resources / Namespace (Workloads)
・Kubernetes / Compute Resources / Node (Pods)
・Kubernetes / Compute Resources / Pod
・Kubernetes / Compute Resources / Workload
・Kubernetes / Networking / Cluster
・Prometheus
・USE Method / Cluster
・USE Method / Node
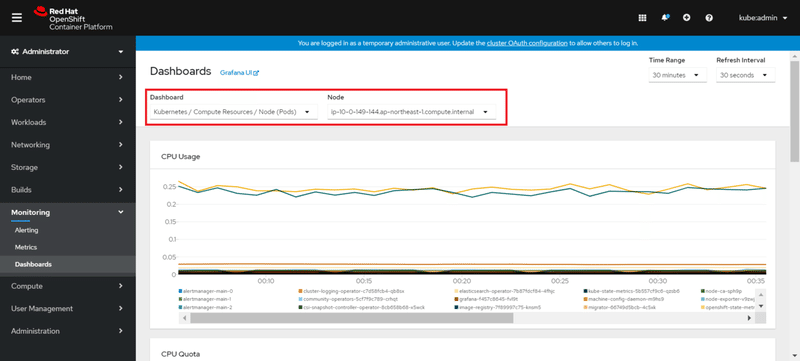
《例①「Kubernetes / Compute Resources / Node (Pods) 」で対象Nodeを指定した場合》
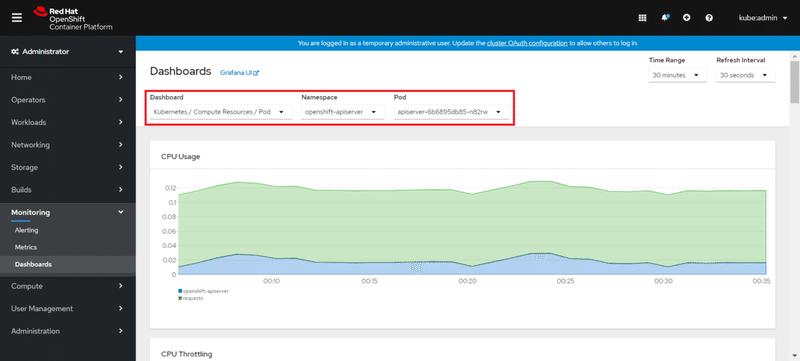
《例②「Kubernetes / Compute Resources / Pod」で対象Podを指定した場合》
OpenShiftコンソールと全く同様のメトリクスを、Grafana自体のダッシュボード画面でも参照可能です。(前述の get route コマンドで取得したGrafanaのURLにアクセスします)
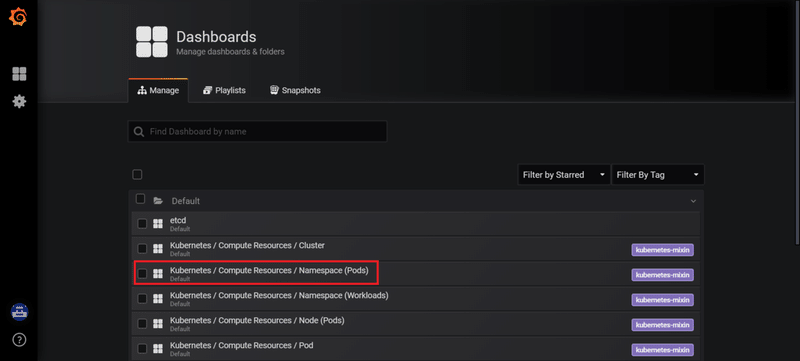
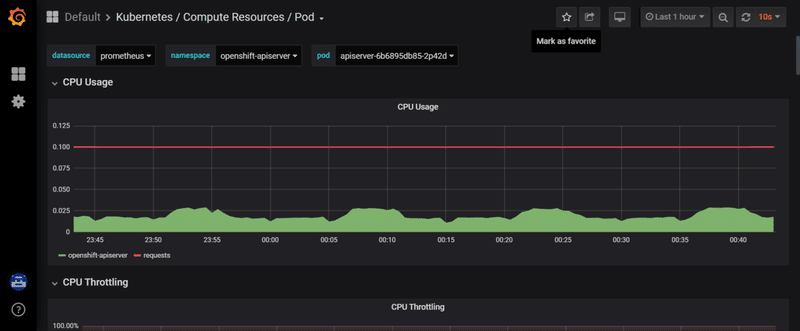
ただし、OpenShift に同梱されるGrafanaは読み取り専用であり、データソースの追加やダッシュボードのカスタマイズができなくなっている点に注意が必要です。
ダッシュボードをカスタマイズしたい場合は、Operator Hubで提供されているコミュニティ版の Grafana Operatorを導入する必要がありますが、この場合はOpenShiftのサポート対象外となります。
メトリクスデータの保持期間の設定
Prometheus のメトリクスデータの保持期間はデフォルトで15日間に設定されています。(参考:OpenShift Container Platform4.5 > モニタリング > 1.2.7. 永続ストレージの設定)
保持期間を変更するには「cluster-monitoring-config」ConfigMap リソースを作成して設定を変更します。
1. ConfigMap リソースを新規作成します。
$ oc create configmap cluster-monitoring-config -n openshift-monitoring
configmap/cluster-monitoring-config created 2. 作成したConfigMap リソースを以下のように編集します。
$ oc edit configmap cluster-monitoring-config -n openshift-monitoringkind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
retention: 24h→retention には 「ms(ミリ秒)」「 s(秒)」「m(分)」「h(時間)」「d(日)」「w(週)」「y(年)」を指定できます。この例では24時間に設定しています。
3. ファイルを保存するとPodが自動的に再起動し、変更が反映されます。
AlertManager によるアラートの管理
OpenShiftでは、デフォルトで事前に定義されたアラートルールが設定されています。
※現時点では、デフォルトのモニタリングスタックの機能内でユーザーが独自にアラートルールを追加することはできません。独自のアラートルールを作成した場合、デフォルトモニタリングスタックのサポート対象外となり、Webコンソール上にも表示されません。
《公式ドキュメントより》
現時点で、アラート UI は OpenShift Container Platform でデフォルトで提供されるアラートのみを表示します。ユーザー定義のアラートは一覧表示されません。これについては、今後のリリースで変更されます。
OpenShift コンソールの [Alerting] - [Alerting Rules] メニューで、アラートルールの一覧を確認することができます。
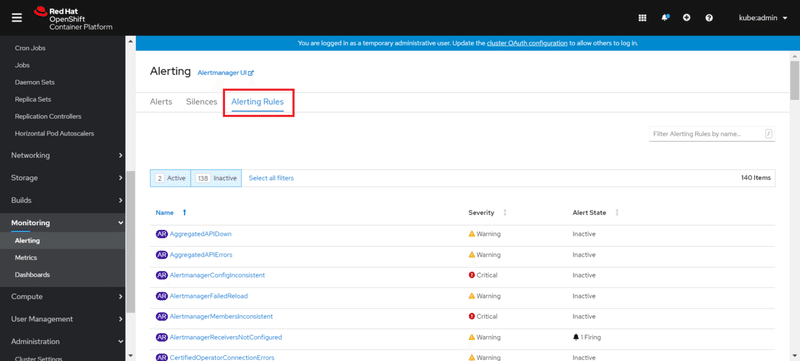
また、以下の手順で、クラスタに適用されているアラートルールをJSON形式で取得することができます。
1. APIを受け付けるために必要なポート転送を設定します。
$ oc port-forward svc/prometheus-operated 9090 -n openshift-monitoring
Forwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 90902. 有効なアラートルールが含まれる JSON オブジェクトを取得します。(1.とは別セッションにて実行します)
$ curl -s http://localhost:9090/api/v1/rules | jq '[.data.groups[].rules[] | select(.type=="alerting")]'
[
{
"state": "inactive",
"name": "CloudCredentialOperatorTargetNamespaceMissing",
"query": "cco_credentials_requests_conditions{condition=\"MissingTargetNamespace\"} > 0",
"duration": 300,
"labels": {
"severity": "warning"
},
"annotations": {
"message": "CredentialsRequest(s) pointing to non-existant namespace"
},
"alerts": [],
"health": "ok",
"type": "alerting"
},
{
"state": "inactive",
"name": "CloudCredentialOperatorProvisioningFailed",
"query": "cco_credentials_requests_conditions{condition=\"CredentialsProvisionFailure\"} > 0",
"duration": 300,
"labels": {
"severity": "warning"
},
"annotations": {
…なお、Alertmanagerにデフォルトで設定されている DeadMansSwitch というアラートルールは、常時トリガーされ続ける特別なアラートルールで、監視システム自体が死んでいないかを監視するためのものです。(監視システムが死んで DeadMansSwitch のアラートが飛んでこなくなった時に異常を検知する、といった使い方が可能です)
アラート通知の設定
AlertManagerにおいて、アラートの通知先は ”Receiver” として定義し、個々のアラートルール(通知すべき監視対象)に対して 必要な ”Receiver” を割り当てる形となっています。(参考:OpenShift Container Platform4.5 > モニタリング > 1.2.8. Alertmanager の設定)
アラート通知の設定を追加/変更するには、alertmanager-main シークレットリソースを編集します。
1. Alertmanager の現在の設定を『alertmanager.yaml』ファイルに出力します。
$ oc -n openshift-monitoring get secret alertmanager-main --template='{{ index .data "alertmanager.yaml" }}' |base64 -d > alertmanager.yaml2. 出力した『alertmanager.yaml』ファイル内の設定を変更します。今回は例として、Gmailアドレスにメール通知を行ってみます。
・global.route.receiver に ”SampleMailReceiver"(名前は任意) を指定します。
・receivers.name[] に ”SampleMailReceiver” を追加し、email_configs 以下にメール送信用の設定を記述します。
・今回はGmailのメールアドレスとSMTPサーバ、認証情報を指定します。
global:
resolve_timeout: 5m
route:
group_by:
- namespace
group_interval: 5m
group_wait: 30s
repeat_interval: 4h
receiver: sample_receiver
routes:
- match:
alertname: Watchdog
receiver: Watchdog
- match:
severity: critical
receiver: Critical
receivers:
- name: Default
- name: Watchdog
- name: Critical
- name: sample_receiver
email_configs:
- to: 'xxxxx@gmail.com'
from: 'xxxxx@gmail.com'
smarthost: 'smtp.gmail.com:587'
auth_username: 'xxxxx@gmail.com'
auth_password: 'xxxxxxxxxx'3.『alertmanager.yaml』ファイルを元に新規 secret リソースを適用します。
$ oc -n openshift-monitoring create secret generic alertmanager-main --from-file=alertmanager.yaml --dry-run=client -o=yaml | oc -n openshift-monitoring replace secret --filename=-
secret/alertmanager-main replaced※公式ドキュメントの上記コマンド例では --dry-run オプションを指定するように記載されていますが、その指定方法は deprecated となっており、現在は --dry-run=client という指定に置き換えられています。
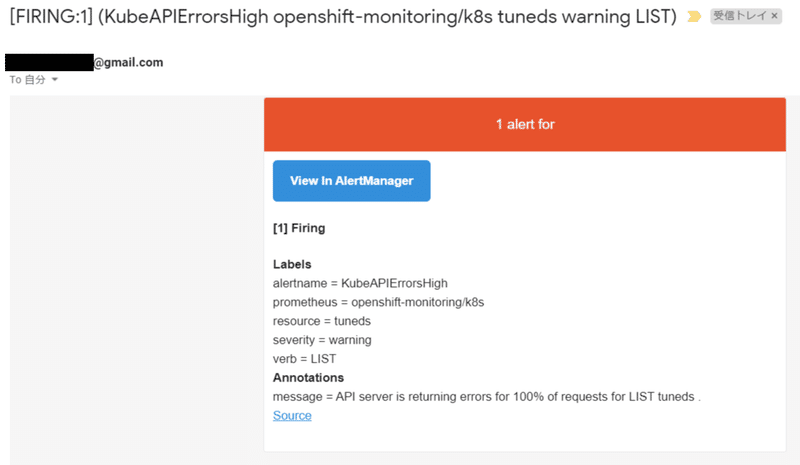
4. アラートルールに該当する事象が発生すると、指定したアドレスに以下のようなメールが送信されてきます。
上記の設定は、OpenShift のWebコンソールでも行うことができます。
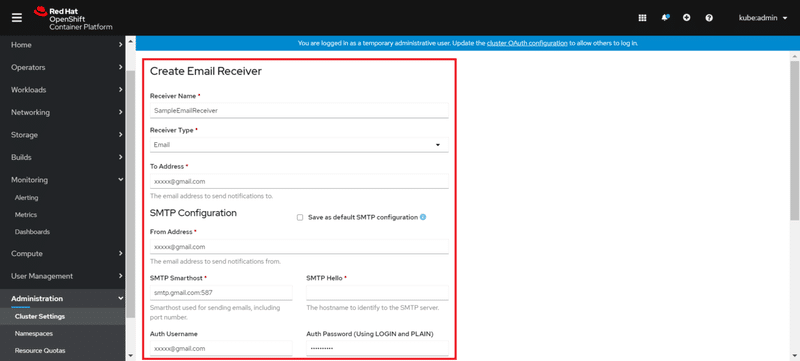
1. Webコンソールの [Administration] → [Cluster Settings] → [Global Configuration] で、リソースの一覧から Alertmanager を選択します。
2. [Details] タブの [Receivers] 欄で「Create Receier」ボタンをクリックし、アラート通知先の設定を行います。
まとめ
このように、OpenShiftでは簡単にモニタリングの仕組みを利用することができます。また、GUIで各種の設定やモニタリング結果を参照することができるため、コマンド操作に不慣れな運用担当者であっても使うことができます。
――――――――――――――――――――――――――――――――――
執筆者プロフィール:馬塚勇介
文系大学卒業後、独立系ソフトウェアベンダーでアプリケーションエンジニアとして主に飲食業向けシステムの構築に従事。その後SHIFTに入社。
現在はSHIFTの関係会社であるリアルグローブ・オートメーティッド(RGA)にPMとして出向中。
RGAでは主にIT自動化適性試験プラットフォームの構築や、CI/CD基盤導入案件を担当。
【ご案内】
ITシステム開発やITインフラ運用の効率化、高速化、品質向上、その他、情シス部門の働き方改革など、IT自動化導入がもたらすメリットは様々ございます。
IT業務の自動化にご興味・ご関心ございましたら、まずは一度、IT自動化の専門家リアルグローブ・オートメーティッド(RGA)にご相談ください!
お問合せは以下の窓口までお願いいたします。
【お問い合わせ窓口】
株式会社リアルグローブ・オートメーティッド
代表窓口:info@rg-automated.jp
URL:https://rg-automated.jp
