
Gitの裏側を少し覗いてみた

挨拶・背景
GutenTag!!
現在、開発支援プロダクト推進部にてTech Boost研修に参加しております、yasudaです。SHIFTには22新卒として入社しております。
私は前回、リモートリポジトリの移動に関する記事を執筆したのですが、それに少し関連して、今回はGitの内部の動きについてまとめながら、理解を深めていければと思っております。
前回記事: https://note.com/shift_tech/n/nc00511c05f1d
想定している対象読者
gitについて業務に支障が出ない程度には理解しているが、「結局Gitって何なの?.gitの中で何してるの?」と問われると答えに詰まる人
Gitを教える立場にある人
ざっくりとした好奇心でGitに興味がある人
Gitのトラブルシューティングに長けたい人
Gitとは?
Gitは分散型データベースのようなシステムです。
Gitは大量のインメモリキャッシュを持つ長時間稼働プロセスのデータベースと比較して、短時間のプロセスで、ファイルシステムを使用して実行間のデータを永続化することを可能にしております。
そして一つの特徴として、Gitのデータ型は、典型的なデータベースよりも制限されています。そのため、Gitは特別なデータストレージとアクセスパターンを持ちます。
Gitはどのようなデータを保存し、どのようにそのデータにアクセスしているのか?
Git’s object store
実は、我々のローカルにある.gitフォルダの中には、.git/objectsというgitオブジェクトを入れるフォルダが存在します。
$ ls .git/objects/
01 34 9a df info pack
$ ls .git/objects/01/
12010547a8990673acf08117134bdc181bd735
$ ls .git/objects/pack/
multi-pack-index
pack-7017e6ce443801478cf19006fc5499ba1c4d2960.idx
pack-7017e6ce443801478cf19006fc5499ba1c4d2960.pack
pack-9f9258a8ffe4187f08a93bcba47784e07985d999.idx
pack-9f9258a8ffe4187f08a93bcba47784e07985d999.pack.git/objects ディレクトリは、オブジェクトストアと呼ばれています。
このディレクトリはコンテンツに基づいて情報を取得できるデータストアであり、オブジェクトの内容のハッシュを提供することで、そのオブジェクトの内容を取得できるようになっています。
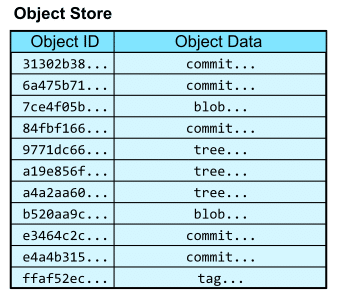
オブジェクトストアは、オブジェクトIDとオブジェクトコンテンツの2つのカラムを持つデータベースのテーブルのような働きをしています。特に、オブジェクトIDはオブジェクトの内容のハッシュであり、主キーのような役割をその中で果たしています。
そもそもコンテンツの中身がよく分かっていないのに、どうやってハッシュでオブジェクトにアクセスできるのか?
実は、GitにはオブジェクトストアのオブジェクトIDへの名前付きポインタを作成することができるリファレンスストアが存在します。
リファレンスストアは主に.git/refs/ディレクトリに存在するのですが、ここでは独自の技術を用いて、リファレンスを効率的に保存したり問い合わせたりするためのテーブルのようなものが存在しています。リファレンスストアはリファレンス名とオブジェクトIDのカラムを持つ二列のテーブルのようになっており、リファレンス名が主キーとなっています。

このリファレンスストアによって、我々が読みやすい名前からオブジェクトストアに移動できるようになっております。例えば、'refs/tags/v2.37.0'のようなフルネームでの指定に加えて、'v2.37.0'のような短い名前も適切に使用することができます。
そして、実はこの'v2.37.0'の参照から、それぞれのGitオブジェクトへのリンクを辿ることが出来ます。

まずこの'refs/tags/v2.37.0'のようなリファレンス名は、注釈付きのtagオブジェクトを指します。この注釈付きtagには、オブジェクトIDによる別のオブジェクトへの参照とプレーンテキストのメッセージが含まれています。
このタグのオブジェクトは、commitオブジェクトを参照します。commitとは、以前のバージョンへの接続であるとともに、ある時点でのワークツリーのスナップショットです。commitには、親commitへのリンクや、ルートツリー、commit時間やcommitメッセージなどのメタデータが含まれています。
このcommitのルートツリーはツリーオブジェクトを参照します。ツリーは、パス名をオブジェクトIDを結びつけるエントリを含むという点で、ディレクトリに似ています。
そのツリーから、README.mdのエントリをたどってblobオブジェクトを見つけることができます。blobオブジェクトにはファイルの内容が格納されます。blobは、blobを指すツリーから名前を取得します。
このように、ある参照から、README.mdファイルの内容にたどり着くためには、オブジェクトデータベースを数回跳び、オブジェクトIDとそのオブジェクトのコンテンツをリンクさせる必要がありました。
git addやgit commitの裏で、何が行われているのか?
我々はよく'git add'して変更をステージングエリアに置き、'git commit -m "メッセージ"'して、コミットを作成しますが、その裏では何が行われているのでしょうか。
'git add'コマンドは、
ワークツリー内の新しい変更をハッシュして、
それらのblobをオブジェクトストアに格納してから、
オブジェクトのリストを.git/indexのステージングエリアに書き込みます。
この時、.git/indexの中身は'git ls-files --stage'で表示できます。
'git commit'コマンドは、
ステージングされた変更を受け取り、
すべての新しいblobを指すツリーを作成し、
そのルートツリーを指す新しいコミットオブジェクトを作成します。
そして最後に、新しいコミットを指すように現在のブランチも更新します。
下図は、ローカルでの編集が README.mdファイルへの変更だけである場合に、git commit -a -m "Update README"を実行すると、複数のGitオブジェクトを作成して最後に参照を更新する処理の順番を示しています。
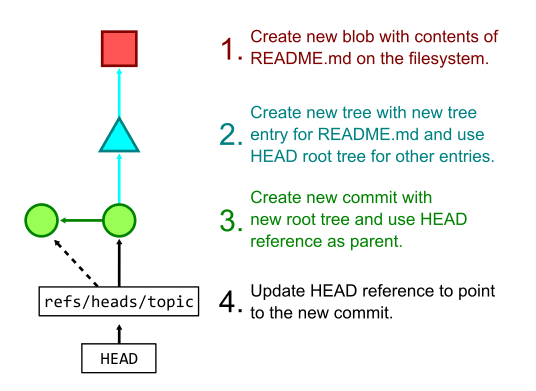
Gitはどのようにして、大量のファイルを効率よくストアに格納しているのか?
ここで再び、.git/objects ディレクトリを見てみると、'01'のように、2桁の名前を持つ複数のディレクトリが見える場合があります。これらのディレクトリには、16進数の長い名前を持つファイルが含まれていますが、このようなファイルはLooseオブジェクトと呼ばれています。
このLooseオブジェクトのファイル名は、オブジェクトIDに対応しています。最初の2 つの16進数文字がディレクトリ名を形成し、残りがファイル名を形成しています。
このような多くのファイルを持つことはファイルシステムに負担をかけるだけでなく、同じテキストファイルの、多くのバージョンを保存する場合にも非効率的なのですが、実は、.git/objects/pack/ディレクトリにあるGitのパックされたオブジェクトストアは、Gitオブジェクトを格納するためのより効率的な方法を形成しています。
.git/objects/pack/ にあるそれぞれの *.packファイルは、文字通り、パックファイルと呼ばれています。パックファイルには、複数のオブジェクトが圧縮された形で格納されており、各オブジェクトは個別に圧縮されるだけでなく、相互に圧縮し合い、共通のデータを利用することもできる仕様となっています。
最も単純なパックファイルには、連結されたオブジェクトのリストが含まれています。これはオブジェクトデータのみを格納し、オブジェクトIDは格納していません。そのため、パックファイルを読み込んで、オブジェクトIDからオブジェクトを見つけること自体は可能ですが、それを行う場合、パックファイルを解凍して各オブジェクトをハッシュ化し、入力ハッシュと比較する必要が出てきます。
そのようなやり方の代替手段を作るために、通常、各パックファイルは.idxで終わるパックインデックスファイルとペアになって存在しています。このパックインデックスファイルは辞書順にオブジェクトIDのリストを保存しているので,オブジェクトIDがパックファイル内にあるかどうかを発見するには、バイナリ検索で十分です。これによりその後,パックファイル内でそのオブジェクトのデータが始まる場所を指すオフセット値が得られます。パックインデックスは、結局のところ、主キー(オブジェクトID)に依存する読み込みクエリを高速化するクエリインデックスのように動作します。

多数のパックファイルがある場合、各pack-indexを順番に要求してオブジェクトを検索できます。パックファイルのさらなる拡張は、複数の pack-index を単一のmulti-pack-indexにまとめることです。これは、同じoffsetデータと、オブジェクトが含まれるパックファイルを格納します。

最後に
ここまで、Gitがどのようにしてデータを保存し、よく使うコマンドの裏でどのような動きをしているのかについて見てきましたが、いかがだったでしょうか。
この記事が皆様のGitに対する理解に一役買うことが出来たら幸いです。
この記事を最後まで読んだ方は是非、ハートボタンからいいねをお願いいたします。
ご清覧ありがとうございました。
参考文献
執筆者プロフィール:Yutaro Yasuda
22新卒としてSHIFTに入社。趣味は散歩、読書、食事。愛用座布団はtempur.
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/