
無償LLM 日本語能力ベンチマークまとめ(23/11/15)

日々新しいオープンソースのLLMまたはllama2のような無償使用可能なLLMが出てくるので定期的にベンチマークをとって性能評価をまとめておきます。新しい日本語対応LLMが出るたびに更新していきます。
23/11/15
Japanese-MT-Bench
RWKV-V5-World-1.5Bを追加。他の3Bモデルと遜色ない性能
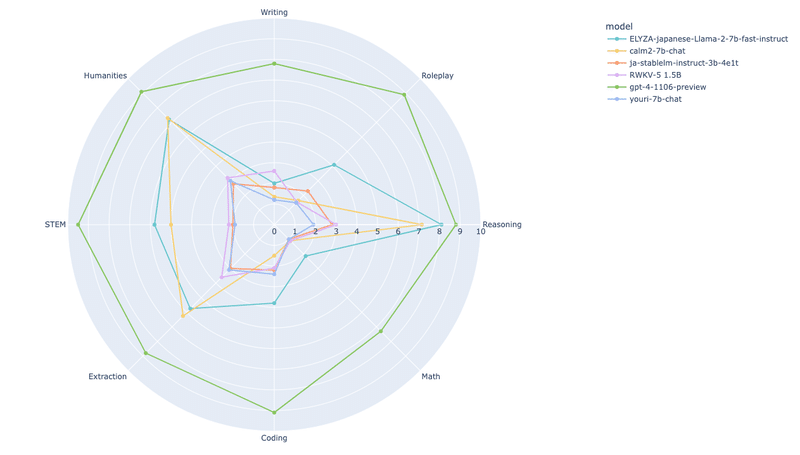
RWKV-V5-World-v2-3Bを追加
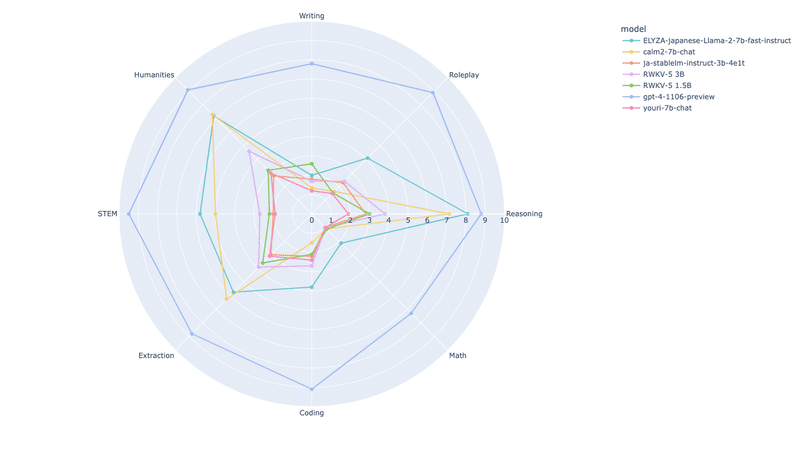
23/11/9
Japanese-MT-Bench
GPT-4-Turbo-1106のベンチマークを追加。コーディング能力が大幅に向上
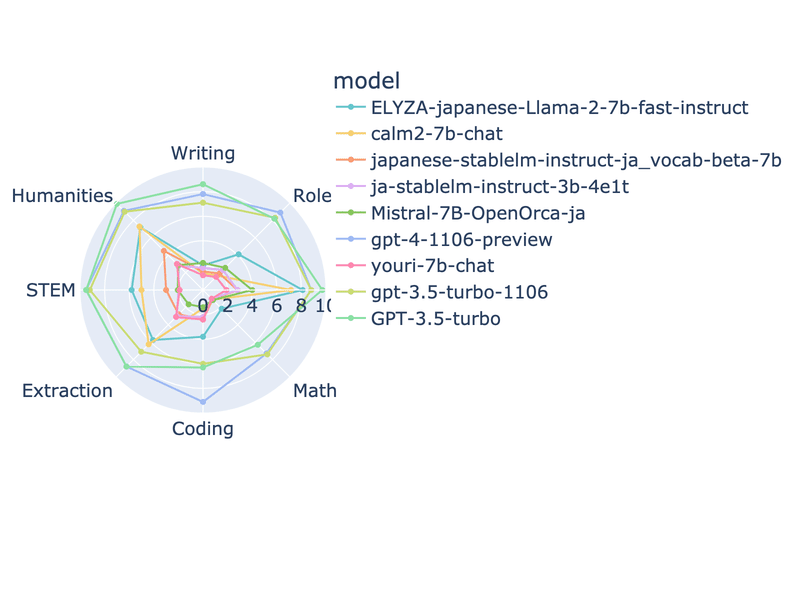
23/11/7
Japanese-MT-Bench
GPT-3.5-Turbo-1106がリリースされたので追加
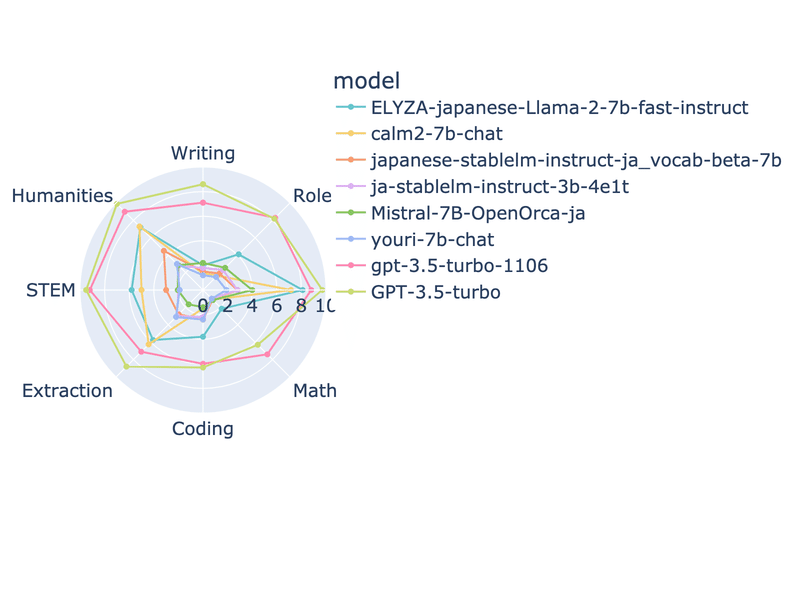
23/11/5
Japanese-MT-Bench
OpenCALM2-7B-Chatがfloat16で計測していたので、bfloat16で再度計算
ELYZAに匹敵する高性能になった上、32Kトークンに対応と大幅に機能が強化された

23/11/4
Japanese-MT-Bench
OpenCALM2-7B-Chatを追加

23/11/3
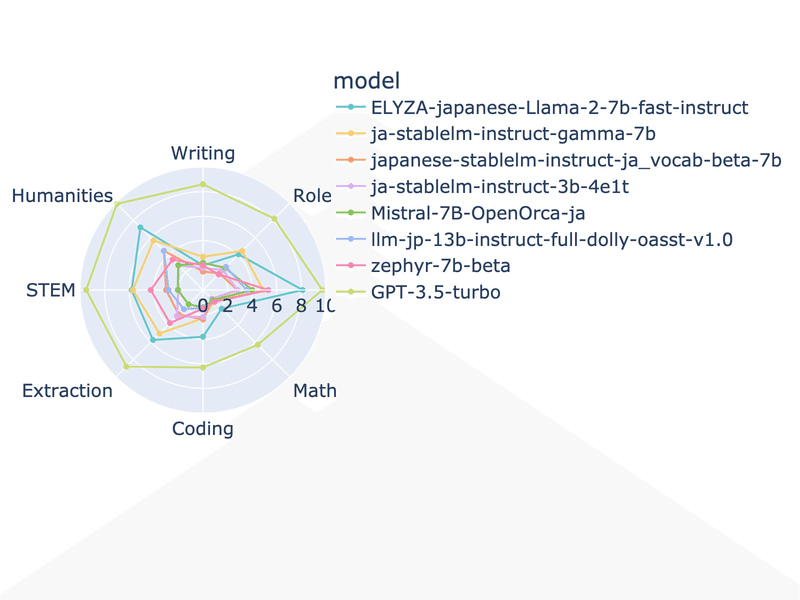
Japanese-MT-Bench
Japanese-StableLM-Instruct-ja_vocab_beta-7Bを追加(オレンジ色)
OpenCALM2は現在テスト中
23/11/2
Japanese-MT-Bench
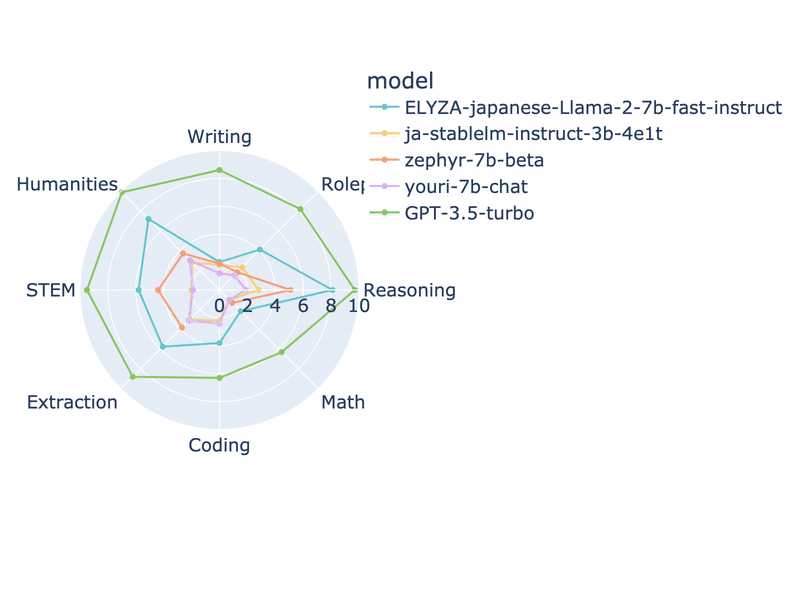
Zepher-7b-betaを追加しました。
23/10/31
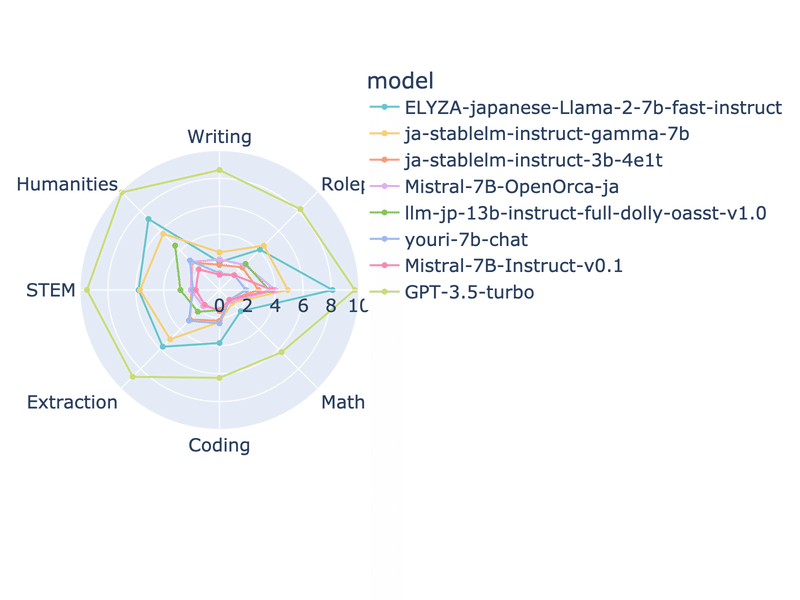
Japanese-MT-Bench
Stability.AiによるJapanese-MT-Benchをベースに各種LLMの日本語能力の比較を行いました。使用したのはこちらにあるquestion_full.jsonlとjudge_ja_prompts.jsonlです。角LLMに共通の質問に答えさせ、その結果をGPT-4が採点しています(GPT-4が採点するのでその分お金がかかっています)。
(c310) memeplex@memeplex-Super-Server:~/media/git/FastChat/fastchat/llm_judge$ python show_result.py --bench-name japanese_mt_bench
Mode: single
Input file: data/japanese_mt_bench/model_judgment/gpt-4_single.jsonl
########## First turn ##########
model turn
gpt-3.5-turbo 1 8.412500
ELYZA-japanese-Llama-2-7b-fast-instruct 1 4.862500
ja-stablelm-instruct-gamma-7b 1 4.012500
japanese-stablelm-instruct-alpha-7b 1 2.742857
ja-stablelm-instruct-3b-4e1t 1 2.237500
Mistral-7B-OpenOrca-ja 1 2.231250
youri-7b-chat 1 2.000000
Mistral-7B-Instruct-v0.1 1 1.775000
llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0 1 1.31250010/31時点での所見
Elyzaが頭ひとつ抜けた性能。Rinnaの新しいマルチターン対応LLMであるyouri-7b-chatはあまり性能が発揮できていない模様。GPT-3.5-turbo以外は特にライティングとロールプレイが弱いようです。