
真・ラクガキや写真からいい感じのアニメタッチの絵を生成する852話さんのモデルを試すComfyUIワークフロー

852話さんが毎日のように新しい研究成果をTwitter(X)にアップしてるので僕も試してたくなり挑戦してみた。
特に最近はラクガキから絵を作るControlNetをやっているらしい。
しかし、これ、ダウンロードすれば誰でも使えるというわけではなかったので色々試行錯誤した過程を記すことにした。うまくハマればすごいツールになるはずだが、ピーキーなところもあるので注意されたし。
今回は852話さんのscribble_xlのnormal、hard、veryhardと、AnimagineXLを使った。852話さんのモデルはmodels/controlnetフォルダに、AnimagineXLはcheckpointフォルダにそれぞれ格納すること。
まず、下準備として、ComfyUIとComfyUI Managerが必要。もちろん、ComfyUIを動かすためには4060など、強力なGPUを搭載したマシンが必要だ。
次に、ComfyUI Managerを入れる。
ComfyUI-Managerはプラグインなどを一括管理してくれる便利なツールだ。
次に、ComfyUIで色々なプリプロセッサを使うため、ComfyUI-Auxというプラグインを入れる。
このプラグインを入れるには、ComfyUI ManagerをインストールしたComfyUIで、Managerをクリック
すると、マネージャーメニューが立ち上がる。
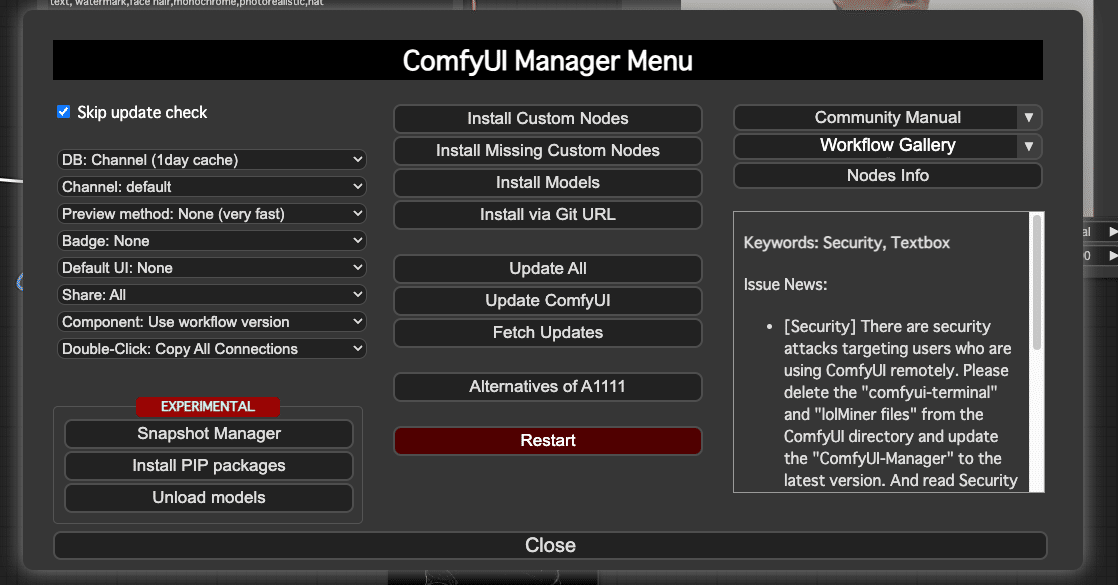
ここで、「Install Custom Nodes」を選ぶと、初回は少し時間がかかるが、プラグインのリストを読み込むことができる。
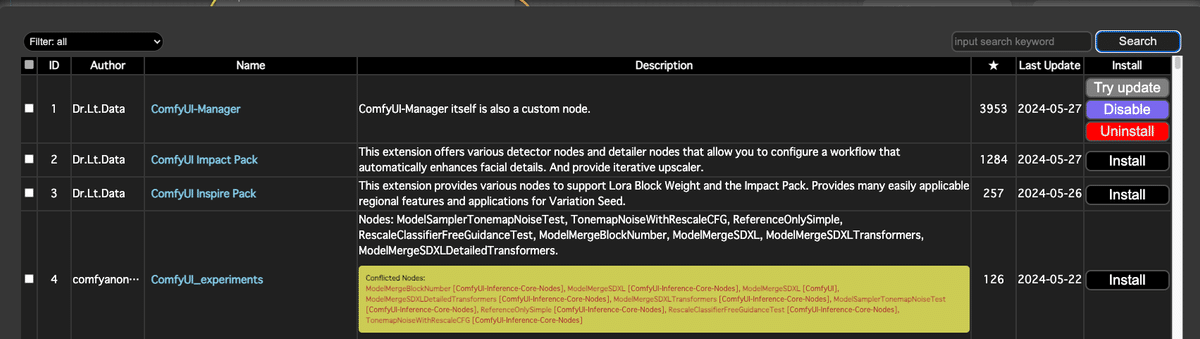
ここで、右上の「input search keyword」のところに「aux」と入力

すると、「ComfyUI's ControlNet Auxiliary Preprocessors」が見つかる。
あとは「Install」ボタンを押せばいい。
しばらく時間が経ったら、インストールが終わるので、念の為ComfyUIを再起動する。
再起動はComfyUI Managerからもできる。

うまくインストールできると、ノードのメニューに「ControlNet Preprocessors」が追加される。
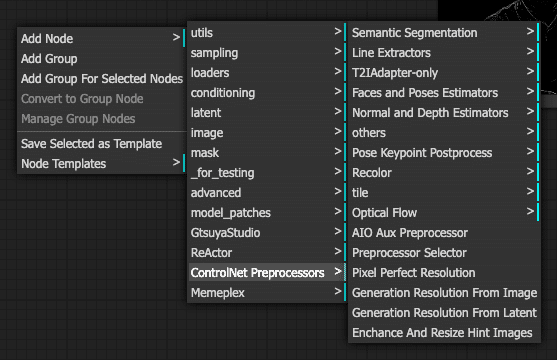
実は852話さんのControlNetは、SDXLモデルであることと、この「ControlNet Preprocessors」の「Realistic Lineart」を使うことが前提(推奨)になっている。

ここまで階層が深いとプログラム書いた方が手間が少ないんじゃないかと思ったりもするが、慣れるとComfyUIはそれはそれで便利なので使う。
まず、ComfyUI初心者のことも考慮して、基本的なワークフローから説明する。
ComfyUIで一番シンプルなワークフローは、「Load Checkpoint」でチェックポイント(モデル)を読み込んで、「CLIP Text Encode(prompt)」でポジティブなプロンプト(こういう絵が欲しいという呪文)とネガティブなプロンプトを英語で入力して・・・
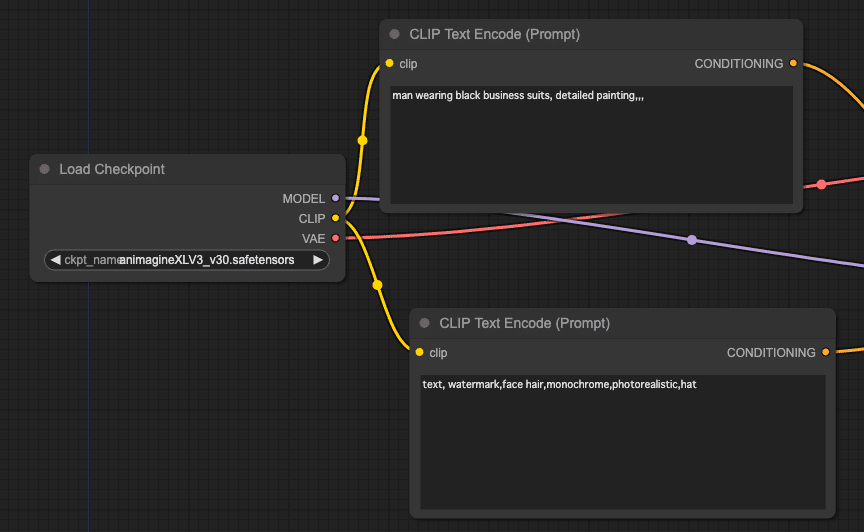
「KSampler」にそれぞれ、チェックポイント(model)、ポジティブ(positive)、ネガティブ(negative)に繋ぐ。
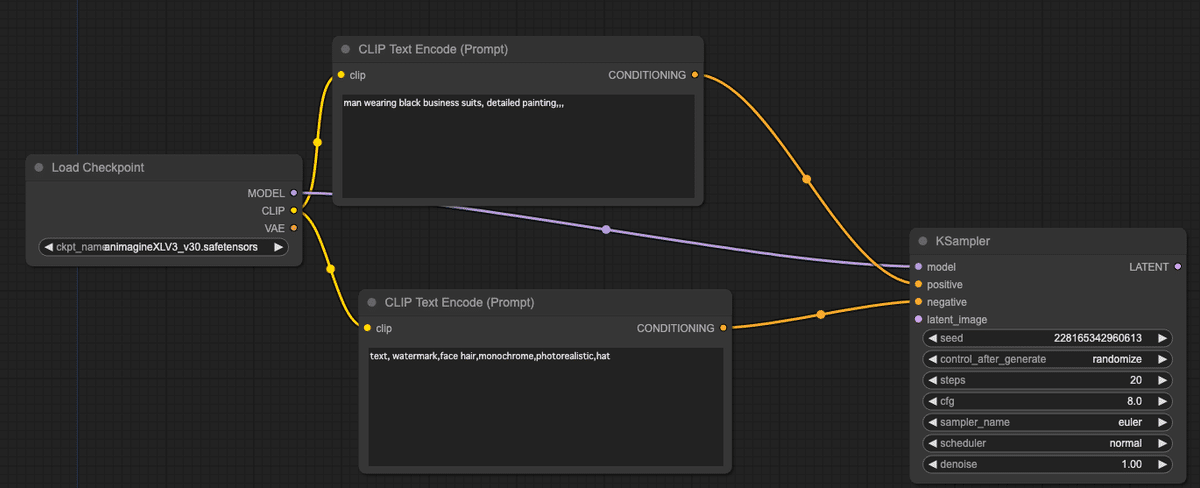
ちなみに「KSampler」とノードは、モデルを使って実際にプロンプトに基づいて絵の内容を探る作業(サンプリング)を担当する。いわば一番重要な役割を果たす。
プロンプトの出力が「CONDITIONING(制約)」となっているのは、制約条件を与えてモデルの中からうまく意図した通りの絵を描かせるためだ。正(positive)の制約と負(negative)の先約がある。
また、初期値として「Empty Latent Image」を指定する。この時、SDXLを使うのでwidth(幅)とheight(高さ)をともに1024に設定するのを忘れずに。
852話さん曰く、SD1.5の問題点はSDXLでほぼ全て解消されていて、SD1.5のLoRAではどうしてもできなかったようなこともできるようになったらしい。なので、SDXLに移行しないとなかなかいい絵が出せないのだそうだ。
最後に「KSampler」の出力である「LATENT(潜在ベクトル)」をもとに、「VAE Decode」で実際の絵にする。
この「VAE Decode」には、最初にロードした「Load Checkpoint」の「vae」と、「KSampler」の出力である「LATENT」が必要だ。「KSampler」の「LATENT」を「VAE Decode」の「Sample」に、「Load Checkpoint」の「VAE」を、「VAE Decode」の「vae」に繋ぐ。
関係ないがこういうところの表記が大文字と小文字で揺れてるのは個人的には気になるのだがいろんな人が寄ってたかって作るとこういう表記揺れが起きがちである。
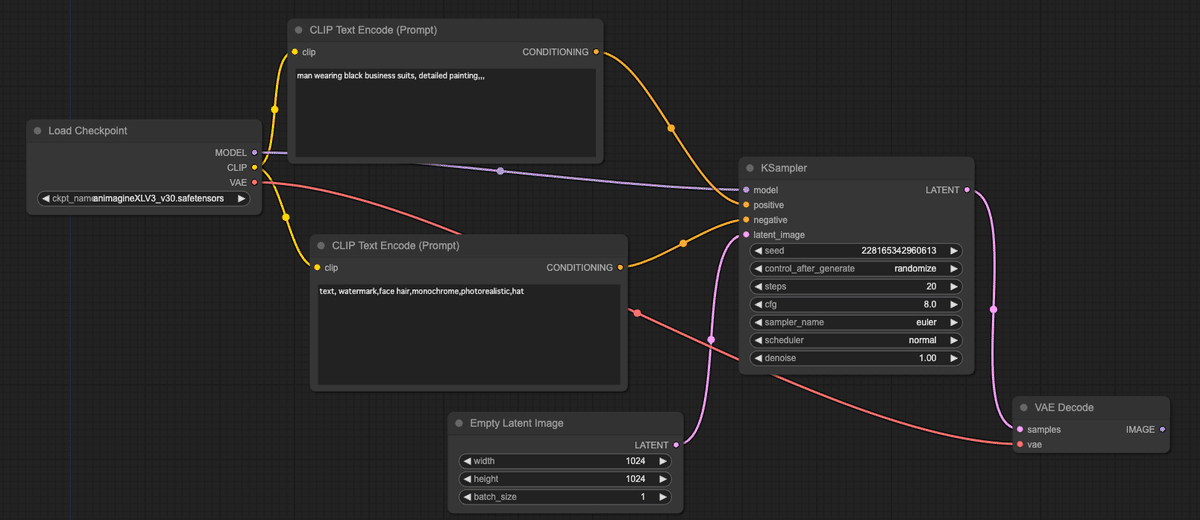
これで、書き上がった絵を保存したいので、「VAE Decode」の「IMAGE」を「Save Image」に繋いで完成。
「Queue Prompt」ボタンを押せば、プロンプトに基づいて絵が生成されて表示されてセーブされる。

ComfyUIがなんでこんなにややこしいのかというと、StableDiffusionによる画像生成をかなり細かくカスタマイズできるようにしているためだ。
だから使う側には、Automatic1111のStableDiffusion-WebUIよりも少し踏み込んだ知識を要求される。
さて、本題。
852話さんのControlNetを使うにはこれだけでは不十分だ。
まず「Load ControlNet Model」で、852話さんのcontrolnet852A_normalを選ぶ。ここに出てこない場合、正しいディレクトリにsafetensorsファイルを置けてないのでチェックされたし。

次に、コントロールネットの元ネタになる雑コラ的な映像の代わりに、写真を読み込むため「Load Image」を使って写真を読み込む。
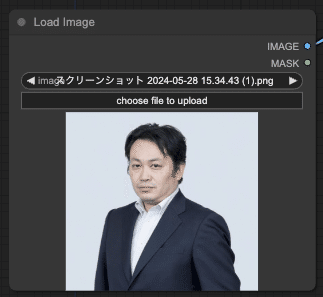
852話さんによると、Realistic Lineartを使うのが推奨だそうなので、「Realistic Lineart」でこの画像を変換する。変換結果を念の為「Preview Image」で確認することにする。
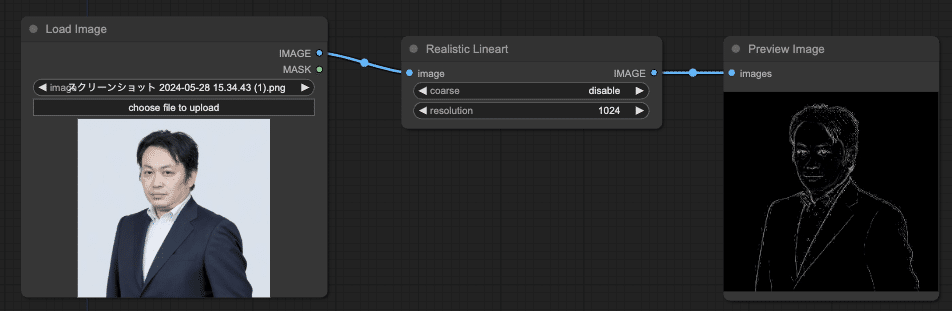
次に、ControlNetを有効化するため、「Apply ControlNet(Advance)」を追加する。
この「Apply ControlNet(Advance)」には、先ほど「KSampler」にもあった「positive」と「negative」という二つの制約条件(CONDITIONING)があり、出力も「positive」と「negative」であるため、これをKSamplerに挟み込むように配置する

挟み込んで二つの「CLIP Text Encode(Prompt)」の「CONDITIONING」から「Apply ControlNet(Advanced)」の「positive」と「negative」に入力し、「Apply ControlNet(Advanced)」の出力(右側)である「positive」と「negative」を「KSampler」の「positive」と「negative」に接続する。
次に、さっき読み込んだ「Load ControlNet Model」から、「CONTROL_NET」を「Apply ControlNet(Advanced)」の「control_net」に接続し、「Realistic Lineart」の「IMAGE」出力を「Apply ControlNet(Advanced)」の「image」に接続する。
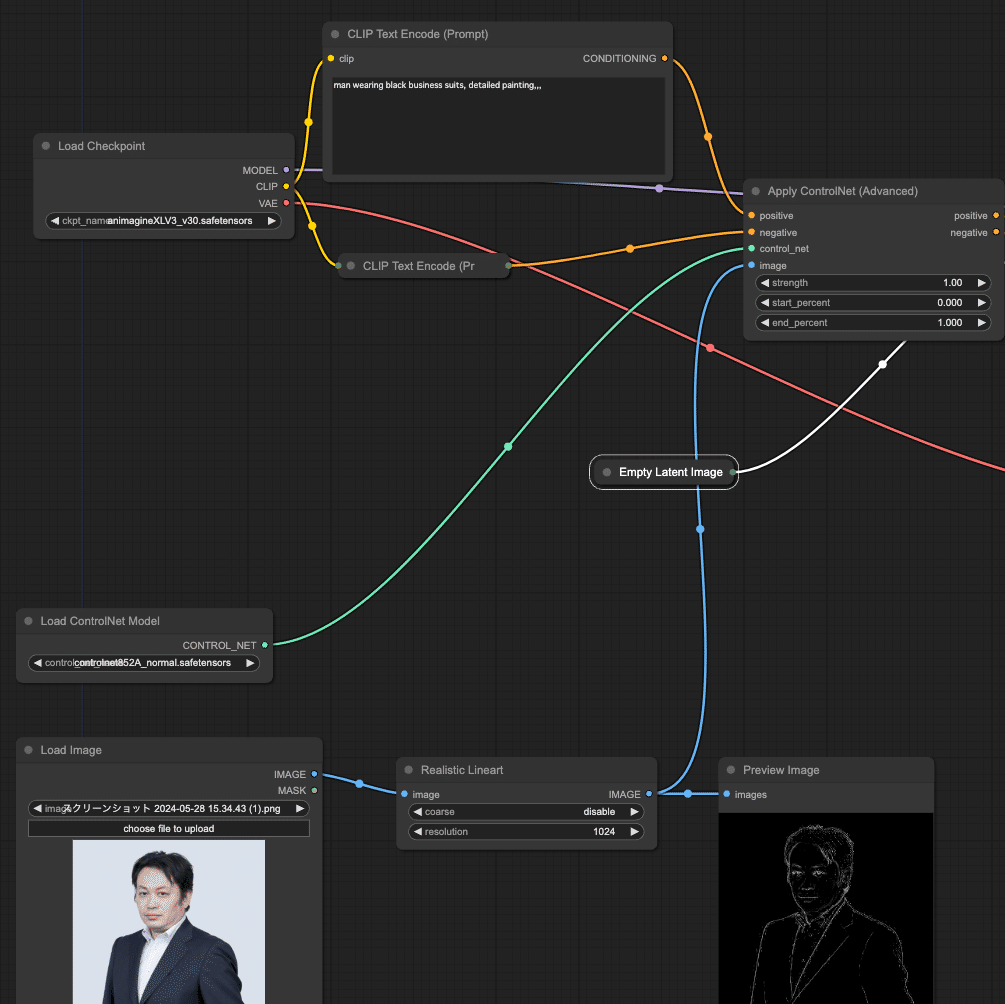
これでワークフローは完成した。
実際、ここまで繋いでから「Queue Prompt」ボタンを押すと、うまく写真が反映された絵が出るはず・・・。
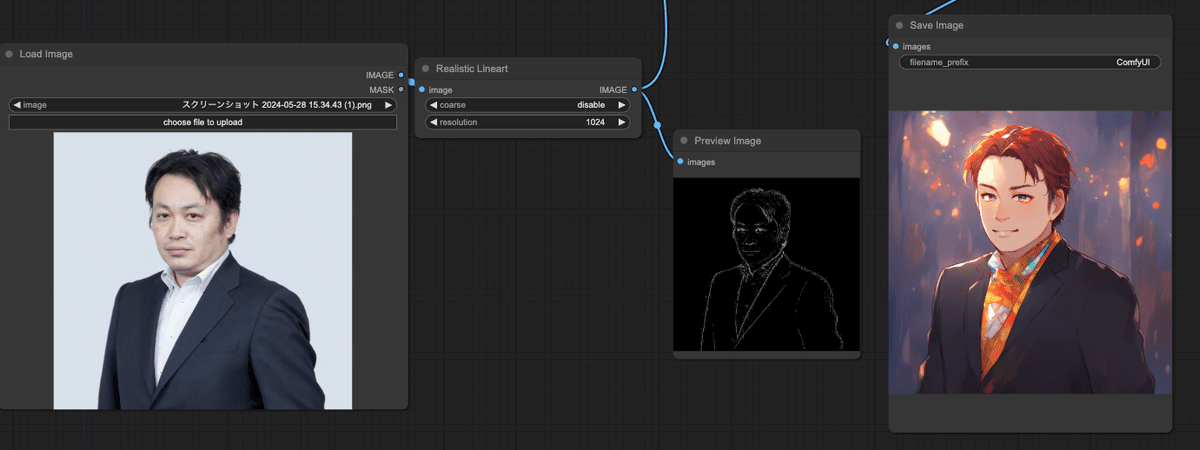
とりあえず全体のワークフローはこう
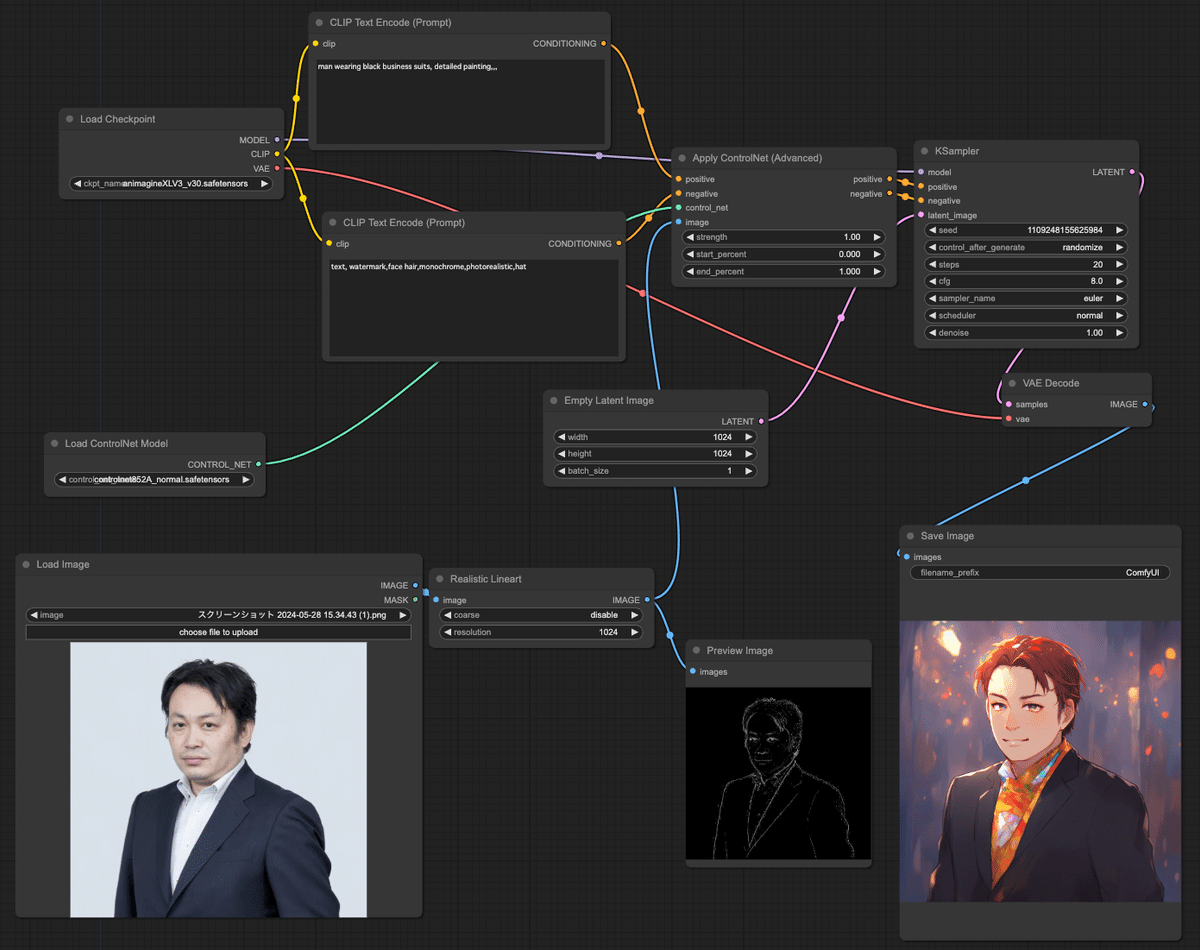
確かに出るのだが、これは僕が試行錯誤してようやく「出し方」がわかったから出るのであって、何でもかんでもいい感じに「出る」わけではない。
例えばこんな画像では失敗する。

「Realistic LineArt」では、正面からの写真で顎の線が消えてしまいがちだ。
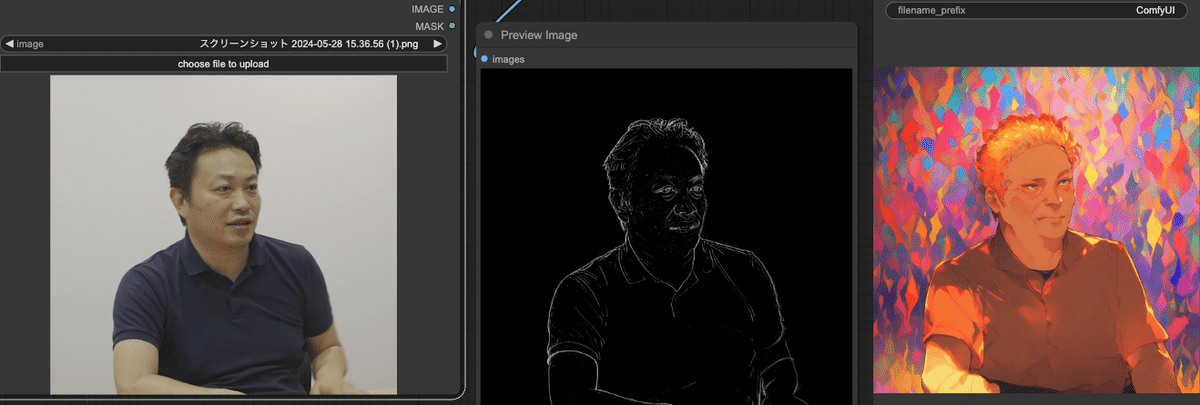
もちろん、このモデルはあくまでもラフスケッチ(Scribble)から綺麗な絵を生成するためのものなので、写真からRealistic Lineartを作るというのはそもそも使い方が間違っているという説もある。
試しに、852話さんがサンプルに書いたラフスケッチを入れると、確かにいい感じの結果になる。

一発でこれが出てくるんだからたまらない。プロンプトは「1girl」だけ。ネガティブは適当に「text, watermark,monochrome,photorealistic」だけ。
しかし、これは852話さんの画力があってこそなのだ。試しに僕も久しぶりにタブレットを引っ張り出してきて書いてみた。

液タブならもう少しマシかもしれないが、どうせあまり変わらない。
人間はどんどんこうやって絵が下手になっていくのである。
さて、この人間の出来損ないみたいな絵を入れたらどうなるか。

下手は下手なりにうまくいく場合もあるのだが、輪郭の歪み方は如何ともし難い。大体、僕自身が同じ人物の別の姿を描ける気がしない。
もう一個書いてみた。

これの場合は・・・
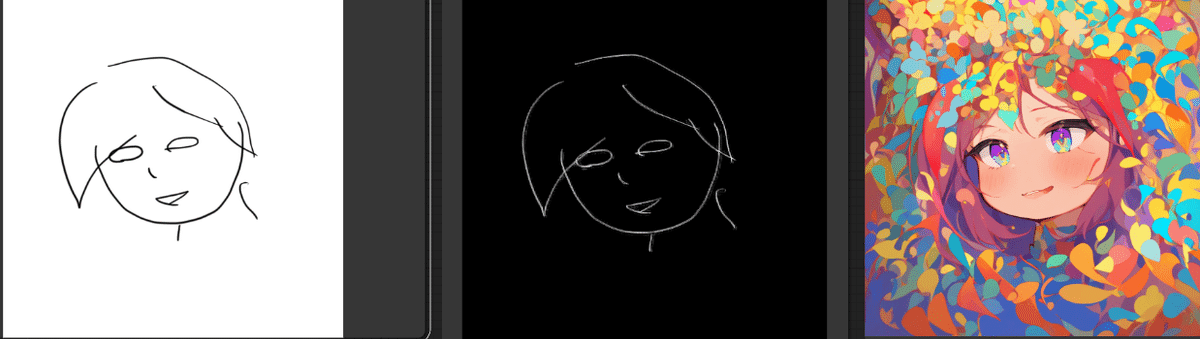
とまあ、こんな感じで確かにガチャ的にいい感じにしてくれるのだが、これは「normal」モードだからで、ControlNetをhardに変えると・・・

さらにvery hardに変えると

どうやら、「normal」は元の線をある程度無視してもいい感じに、hard、veryhardとなっていくにつれて元の線に忠実になっていくという感じらしい。
ちなみに昔自分で書いた蒸気機関車の絵を読ませるとこうなった。

蒸気機関車の模型の写真だとこうなった
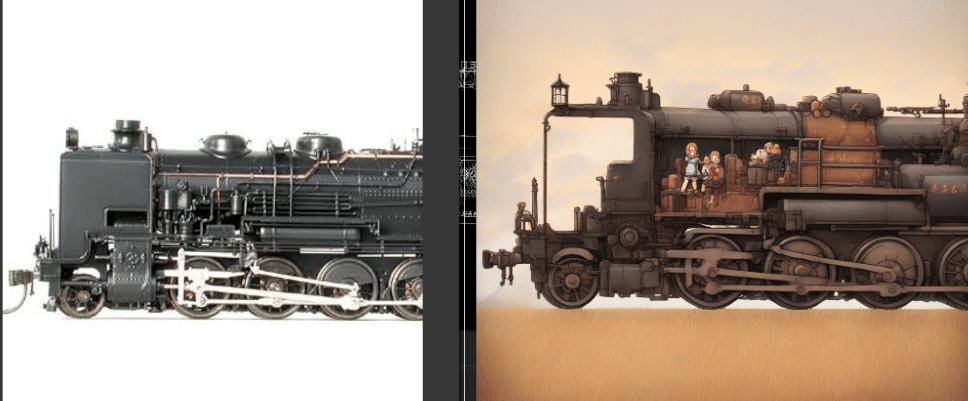
使い方次第ではとんでもないことができそう。