
色々なライブラリでLLMを量子化してみる

研究開発本部 海老原樹
はじめに
PCに言語モデルが搭載される時代になりました。シャープも LLM(大規模言語モデル)を実装したスマホを7月中旬以降に発売予定で、LLM によって留守番電話に録音された内容を要約して、利用者が要件を一目で確認できる機能を実現しています。
サイズの大きい LLM をスマホのような限られたリソースで動かすにはいくつかの方法がありますが、代表的なものは量子化です。量子化はモデルのパラメータをより少ないビットで表現することにより、いくらかの精度低下を伴いますが、モデルの軽量化や推論の高速化を実現することができます。
すでに世の中には LLM を量子化するための便利なライブラリがいくつも存在します。今回は代表的な量子化のためのライブラリについて、その特徴や使い勝手を知るために、実際にライブラリを使って日本語 LLM を量子化して、量子化後のモデルで文章生成をしました。
※本記事はやや開発者目線の記事になっていることをご了承ください。
代表的なLLM量子化ライブラリ
LLM の量子化に使われる下記の代表的な 5 つのライブラリを対象としました。
bitsandbytes
llama.cpp
AutoGPTQ
AutoAWQ
CTranslate2
下の表では、LLM の量子化において主流な 8-bit 量子化と 4-bit 量子化への対応についてと、使い勝手において重要なキャリブレーションデータ※の必要性についてまとめています。
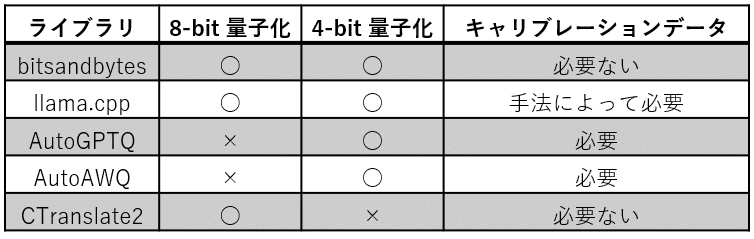
※ 一部の量子化手法では量子化後のモデルの精度劣化を低減するために調整用のキャリブレーションデータを使用します。適切なキャリブレーションデータを選ぶことにより、モデルの精度の低下を効果的に抑えることができます。
以下では各ライブラリについて、簡単に紹介します。
bitsandbytes
Pytorch 用の 8-bit、4-bit 量子化ライブラリです。LLMを扱う代表的なライブラリの transformers に統合されていて、また、量子化の際にキャリブレーションデータが必要ないという点で、LLM を量子化する際の最も簡単な選択肢の一つです。
llama.cpp
Meta 社の LLM の1つである LLaMA モデルのための、 C/C++ で記述された高速推論ツールです(LLaMA 以外のモデルにも対応)。独自の手法による量子化機能も備えています。最近話題の LLM 実行ツールである Ollama もバックエンドで llama.cpp を使っています。
AutoGPTQ
GPTQ アルゴリズムをベースとした LLM 量子化のライブラリです。量子化の際にはキャリブレーションデータが必要となります。transformers ライブラリに統合されており、量子化されたモデルも他の LLM と似たようなコードで扱うことができます。
AutoAWQ
AWQ アルゴリズムを用いた LLM 量子化ライブラリです。量子化の際にキャリブレーションデータが必要であることや transformers ライブラリに統合されている点は AutoGPTQ と共通です。AWQ の提案論文では、GPTQ よりも量子化後の精度低下が抑えられていることが報告されています。
CTranslate2
Transformer モデルをCPUやGPUで効率的に動かすことを目的とした、C++と Python で記述されたライブラリです。CPU、GPU の両方において、高速・低リソースの推論が可能です。Decoder-only の LLM 以外にも、複数の Encoder-Decoder モデル・Encoder-only モデルに対応しています。ただし、LLM に関しては他の量子化ライブラリに比べ、対応しているモデルがやや少ないです。
各ライブラリでLLMを4-bit量子化
前章で紹介した量子化ライブラリを使って、日本語の LLM である elyza/ELYZA-japanese-Llama-2-7b-fast-instruct を 4-bit 量子化し、生成速度や出力される文章を確認しました。なお、4-bit 量子化に対応していない CTranslate2 は対象外としました。
LLM の量子化・推論の実行環境を以下に示します。
OS: Ubuntu 22.04
CPU: 12th Gen Intel(R) Core(TM) i5-12600
RAM: 32 GB
GPU: NVIDIA GeForce RTX 4090 (VRAM 24 GB)
CUDA: 12.1
NVIDA Driver: 555.42.02
Python: 3.10.13
各ライブラリの主要な量子化の設定は以下の通りです。
lama.cpp の量子化モードは Q4_K_M (キャリブレーションデータを必要としない量子化)を選択。
AutoGPTQ と AutoAWQ のキャリブレーションデータには、日本語のデータとして izumi-lab/wikipedia-ja-20230720 の内、ランダムに取得した 128 個のサンプルを使用。
その外の詳細な量子化設定については、本記事の最後の「補足」をご覧ください。
量子化にかかる時間
各ライブラリで LLM の量子化を行い、その際にかかった時間を計測しました。
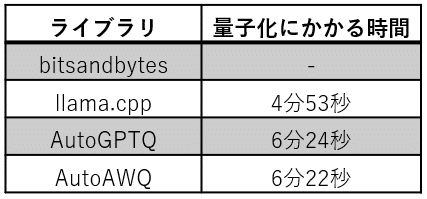
※bitsandbytes については、モデルをロードする関数内で量子化も行われていて、量子化にかかる時間のみを分離できなかったため数値無し。
※llama.cpp については、「モデルを量子化する時間」には、GGUF 形式への変換にかかる時間とその後の量子化にかかる時間の両方が含まれます。
※AutoGPTQ と AutoAWQ については、「モデルを量子化する時間」にはキャリブレーションデータを準備する時間・モデルを保存する時間は含まれていません。
bitsandbytes は数値なしとなっていますが、量子化をするかしないかでモデルのロード時間はほとんど変わらなかったため、量子化によるオーバーヘッドはほとんどないと思われます。他の量子化ライブラリに比べて頭を悩ませる要素も少なく、最も手軽に量子化を実践できると感じました。
llama.cpp では、まず Pytorch のモデルを GGUF 形式に変換し、その後量子化を行います。他のライブラリに比べひと手間必要ですが、量子化モデルを準備するために必要な時間は、AutoGPTQ や AutoAWQ に比べて短かったです。llama.cpp の量子化の速度は CPUの性能で変わると思われます。
AutoGPTQ と AutoAWQ については、量子化にかかる時間はほとんど同じでした。どちらも量子化の際に GPU を活用するため、GPU の性能によって時間は変わります。また、両方ともキャリブレーションデータを用意する必要があるので、量子化後のモデルの品質のことを考えると、どのキャリブレーションデータを使うかは試行錯誤して決める必要があると感じました。
今回はライブラリを活用して 量子化した LLM を自前で用意しましたが、llama.cpp や AutoGPTQ などのコミュニティは活発で、hugging face で量子化されたモデルが公開されていることも珍しくありません。実際、今回扱った日本語 LLM についても、llama.cpp で量子化されたものやAutoGPTQで量子化されたものが見つかりました。LLM を量子化して使いたいと考えている場合、量子化する前に、すでに量子化されたモデルが公開されていないか、チェックするとよいかもしれません。
量子化したモデルで推論
引き続き、量子化後のモデルを使って文章を生成し、生成速度・モデルのVRAM消費・生成された回答を確認しました。以降の全ての設定において、モデルの重みは全て GPU でロードしています。
※ ここでの「モデルのVRAM消費」とは、モデルがロードされた時点での VRAM 消費量であり、文章生成時の VRAM 消費量ではありません。
※ llama.cppについては、python バインディングである llama-cpp-python を使用しました。
各ライブラリの文章生成時の設定については、本記事の最後の「補足」をご覧ください。
量子化後のモデルのVRAM消費と生成速度
下の表では、次節で紹介する回答例を生成した際のモデルの VRAM 消費と生成速度を示しています。
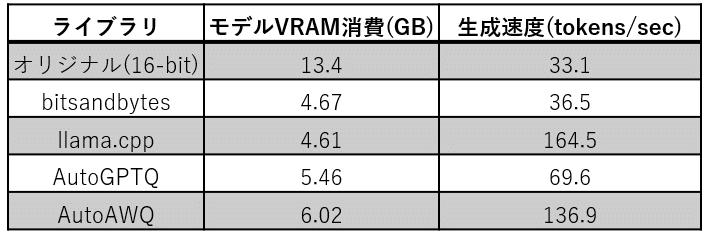
モデルの VRAM 消費量は、量子化前の 16-bit のモデルに比べ、どのライブラリでも 1/3~1/2 程度になっています。量子化後のモデルは重みは 4-bit なのに、そのサイズは量子化前のモデルの 1/4 にはなっていません。その理由としては、(i) 全ての重みが 4-bit に量子化されているわけではないこと、(ii) 量子化後の値が量子化前の値の近似値になるように追加の情報も保存されていることなどがあります。
ライブラリごとに、VRAM消費量も違いが見られます。これは、量子化手法の違いやライブラリ固有のオーバーヘッドによるものと思われます。llama.cpp が最も軽量で、AutoAWQ が最もメモリ消費量が多い結果になりました。
続いて生成速度に関してですが、これはライブラリごとに大きな差があります。特に llama.cpp と AutoAWQ がオリジナルのモデルに比べ、それぞれ5倍、4倍程度の速さでした。llama.cpp は C++ で実装されており、高速化されている強みが表れています。AutoAWQ については、デフォルトで有効になっている "Fused modules" による高速化の影響かと思われます。これは複数のレイヤーを1つの操作にまとめることで、モデルの使い方に一部制約が加わりますが、高速化を実現する手法のようです。
今回の量子化の主題からはやや外れますが、LLM の高速推論ライブラリとして、NVIDIA 社が提供する TensorRT-LLM があります。こちらも(実験的実装とされていますが、)GPTQ・AWQ を用いた量子化機能が備わっており、llama.cpp より高速に推論ができるとの報告もあります。
回答例
実際に量子化されたモデルによって出力された回答を見ていこうと思います。LLM へ入力するプロンプトには、elyza/ELYZA-japanese-Llama-2-7b-fast-instruct のサンプルコードのプロンプトを使用しました。
<s>[INST] <<SYS>>
あなたは誠実で優秀な日本人のアシスタントです。
<</SYS>>
クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。 [/INST]
※生成された文章は256トークンで区切っているため、途中で途切れたように見えるものがあります。
オリジナル(16-bit)
クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を作成します。
クマが海辺に行ってアザラシと友達になる話
ある日、クマは山の中でアザラシのぬいぐるみを見つける。
クマはぬいぐるみを家に連れ帰り、大切にしながら眠りに落ちた。
翌朝、クマは海辺にやってきた。
そこにはアザラシがいた。
アザラシはクマに気づき、驚いて水の中へ逃げた。
クマはアザラシを探し回り、やっとのことでアザラシを捕まえる。
アザラシは恐怖で震えていたが、クマは優しく撫でてやった。
アザラシはクマに懐き、二匹はすぐに友達になった。
クマとアザラシは海辺を散歩し、魚を獲ったり、貝を集めたりした。
二匹はとても楽しい時間を過ごした。
ある日、
256トークン中で物語は完結していませんが、全体として無理のないストーリーになっていると感じます。ぬいぐるみの話はクマが海辺に(アザラシに会いに)行く動機づけになっているところが上手い点だなと個人的に思いました。
bitsandbytes
承知しました。以下がプロットの短編小説です。
クマは海辺に行きました。
クマはアザラシと友達になりたいです。
アザラシはクマと友達になります。
クマは家に帰りました。
お役に立ててよかったです、よろしくお願いします!
短編小説にしてもあまりにも簡潔すぎますね。物語としての面白味も一切なくなってしまいました。。。
bitsandbytes で 4-bit 量子化すると、日本語としておかしな文章ではないですが、かなり表現力が落ちることがわかりました。
llama.cpp
クマはいつも山の中で過ごしていました。
彼は物語を作るのが大好きで、その才能は周りからも認められていました。
ある日、クマは新しい物語のアイディアが浮かびました。
海辺に住むアザラシと友だちになるという物語です。
クマはすぐに行動に移します。
彼は一目見て気に入った家を見つけて、そこへ引っ越しました。
しかし、海辺へと通うのは大変なので、クマは船を作りました。
船は木で作られ、とても頑丈でした。
クマは毎日、船に乗って海辺に向かいました。
彼の船は次第に修理が必要になり、最終的にはとっくりにボロボロになっていきました。
それでもクマはひまわりを乗せて、アザラシのもとに旅立ったのでした。
まず、一文一文の表現力は豊かですが、ところどころ、文脈がおかしいと感じる箇所があります。家へ引っ越した文は前後とあまりつながりがないし、最後の文の「ひまわり」に関しても唐突感があります。
また、「クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。」という指示に添えているのかいないのか、はっきりしない構成になっています。表現力は落ちていませんが、指示に従う能力や文脈を考慮する能力が低下していると感じました。
AutoGPTQ
クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を作成します。
クマの名前はキリっとしていたので、彼はキリと名付けられていました。
ある日、キリは海辺に行き、アザラシと友達になります。
アザラシの名前はフワッとしていたので、彼はフワと名付けられていました。
キリとフワは海辺で遊んでいると、お腹が空いてしまい、お腹を空かせるようになりました。
キリとフワは海辺で遊んでいると、お腹が空いてしまい、お腹を空かせるようになりました。
キリとフワは海辺で遊んでいると、お腹が空いてしまい、お腹を空かせるようになりました。
キリとフワは海辺で遊んでいると、お腹が空いてしまい、お腹を空かせるようになりました。
キリとフワは海辺で遊んでいると、お腹が空いてしまい、お腹
文章中に繰り返しが発生しており、明らかに品質の低下が感じられます。また、「キリとフワは海辺で遊んでいると、お腹が空いてしまい、お腹を空かせるようになりました。」というのも、日本語としてはおかしな文章です。アザラシと友達になる流れも唐突で、物語としての完成度も低いです。今回の量子化では、AutoGPTQ では基礎的な日本語能力の低下がみられました。
AutoAWQ
クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を以下に作成します。
クマは家から逃げ出し、海辺まで歩いてきました。海辺に着くと、クマはアザラシに出会います。
「こんにちは」とクマが言うと、アザラシは「こんにちは」と返しました。
クマはアザラシと友達になり、毎日海辺で遊んでいました。
ある日、クマは家に帰りたいと思うようになりました。
「今日は家に帰ろうかな」とクマが言うと、アザラシは「今日は家に帰ろう」と返しました。
クマはアザラシに連れられて、家まで歩きました。
家に入ると、クマの家族がクマを迎えました。
クマはアザラシに会って、本当に幸せな気持ちになりました。
「アザラシ、ありがとう」とクマが言うと、アザラシは「クマ、ありがとう」と返しました。
それ
なぜクマは家から逃げ出したのか、出だしが気になるところですが、物語全体としては自然な流れになっています。クマがアザラシと友達になり、家に帰るところまで描かれているので、プロンプトの指示に従う能力も保持しています。
文章自体はやや子供っぽいと感じるので、表現力は低下しているように見えますが、もしかしたら子供向けの物語という体で綴っているかもしれません。いずれにせよ、生成された文章の品質としては、プロンプトの指示に従う能力・文脈・表現力という観点で、総合的に AutoAWQ が最も良いと感じました。
最後に各ライブラリで量子化した後のモデルの生成速度、キャリブレーションデータの使用/不使用、定性的な品質をまとめた表を示します。品質は一つの回答例だけから分析したもので、筆者の主観的なものであることをご了承ください。

まとめ
今回は、代表的な LLM 量子化ライブラリの特徴や使い勝手を知るために、実際にライブラリを使って日本語 LLM を量子化し、量子化後のモデルで文章生成をして回答を比較しました。
使い勝手という点では、bitsandbytes が最も手軽に利用できると感じました。一方で AutoGPTQ、AutoAWQ(手法によっては llama.cpp も)はキャリブレーションデータが必要であり、そのノウハウが求められるため、ややハードルが高い印象でした。また、全てが量子化による恩恵ではありませんが、llama.cppと AutoAWQ に関しては、4~5 倍の推論高速化を実現することができました。
それぞれのライブラリで量子化されたモデルが出力した回答を見比べてみると、ライブラリごとに異なる特徴がみられ、量子化手法による違いが出ていることがわかりました。今回のケースでは、bitsandbytes と AutoGPTQ の量子化による劣化が大きい一方で、AutoAWQ に関してはある程度品質が保たれていることがわかりました。そこまで深く考えずに選んだ日本語のキャリブレーションデータでもある程度品質劣化を抑えられたので、試行錯誤によってはさらに品質のよい量子化モデルができることが期待されます。
今回は一つのプロンプトに対しての回答だけを分析しましたが、量子化による品質低下をきちんと調べるためにはより統計的な分析をする必要があるでしょう。特にキャリブレーションデータと量子化後のモデルの品質の関係については、今後ぜひ調査したいところです。
参考
日本語LLM 9種を量子化して回答内容を比較調査してみた #LLM - Qiita
補足
各量子化ライブラリの量子化の際の設定
bitsandbytes
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)llama.cpp
公式のコードでは GGUF 形式への変換後、量子化の際にエラーが出てしまうので、以下を参考に `convert-llama-hf-to-gguf_for_ex_vocab.py` を使ってモデルを GGUF 形式に変換し、その後、公式の量子化スクリプトを用いて量子化を行いました。
AutoGPTQ
quantize_config = BaseQuantizeConfig(
bits=4, # quantize model to 4-bit
group_size=128, # it is recommended to set the value to 128
desc_act=False, # set to False can significantly speed up inference but the perplexity may slightly bad
)AutoAWQ
quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, }各量子化ライブラリの文章生成時の設定
オリジナル(16-bit)、bitsandbytes、AutoGPTQ、AutoAWQ については、共通して以下の設定で文章を生成。
output_ids = model.generate(
input_ids=token_ids,
max_new_tokens=256,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)llama.cpp については、以下の設定で文章を生成
results = llm.create_completion(prompt, max_tokens=256)この記事が気に入ったらサポートをしてみませんか?