trocco を使った Box から BigQuery への冪等データ投入への道

この記事は trocco®のカレンダー | Advent Calendar 2023 - Qiita の16日目の記事として書きました。
僕が今働いている会社では、お客様である病院から月々の診療行為などに関するデータをお預かりし、その分析を元に経営コンサルティングをするという事業を行っています。
このデータは Shift_JIS の CSV ファイルでいくつかの種類があるのですが、ひと月分のサイズは小さい病院の場合は数KBなのですが大きい病院の場合だと350MBを超えることもあります。
かつてはこれらのファイルをローカルの PC で処理していたそうなのですが、当然のことながらえらく大変です。そこでこの1年ほどは BigQuery にデータを置いて分析をするようになっているのですが、それだけのサイズとなると単に転送するのでさえも大変だし失敗したときのリカバリーも骨が折れます。
ということで、この記事ではどういう経緯を辿って今どのように運用しているかを記します。
なお、この記事ではデータが配置されている最上流は Box とします。
trocco 導入前
手順
Box から GCS : rclone
Shift_JIS から UTF-8 への文字コード変換 : Cloud Functions
GCS から BigQuery への投入 : Cloud Shell から bq コマンド実行
分析 : Google スプレッドシート / BigQuery のコンソールに保存したクエリ
rclone
新規データだけであれば Google Cloud Storage へのアップロードもそんなに苦では無いかもしれませんが、過去分のデータもあるのでそれを逐一ダウンロードしてアップロードするというのはさすがに大変です。ということで rclone というコマンドラインベースの転送ツールを使って転送をしていました。使い方等については前に Box の大量データを GCS に送りたい という記事を書いたので良かったらそちらをご覧ください。
コマンドラインで実行できるのである程度自動化はできるのですが、データが実行している端末を経由するような状態となるため、テザリング環境などでやると問題となるかもしれません。
Cloud Functions
BigQuery がインポートできる CSV の文字コードは UTF-8 であるため、 Shift_JIS から変換しなくてはなりません。
そこで GCS へのファイル配置をトリガーとし、ファイルを読み込んで文字コードを変換して別のところに保存するという関数を作りました。
前述の rclone により Shift_JIS のファイルを転送すると UTF-8 のファイルが生成されるという仕組みです。
基本的にうまくいっていたのですが、やはりときどき大きいサイズのファイルがあるため、ランタイムのメモリサイズをそこそこ大きいものにしておかねばなりません。 /tmp のようなローカルディスク的な領域も使えるのですが、それはメモリリソースから消費されるのです。もはや覚えていないのですが、最終的に 1GiB か 2GiB を選んだような気がします。
bq
GCS にロード可能な CSV があるのであとは単に bq load ... のように実行します。複数種類のファイルをそれぞれのテーブルに投入するため、スキーマ定義の JSON が必要となります。それらの JSON ファイルについては Cloud Shell の環境にアップロードしておけば、後日 Cloud Shell を起動したときにも使えて便利です。
Google スプレッドシート
BigQuery で SQL を実行すると「結果を保存」から Google スプレッドシートへの保存を選べたり、そもそもスプレッドシートの接続シートで BigQuery への SQL を書いておき、その結果をスプレッドシートに出力できます。この出力とピボットテーブルなんかを駆使するとある程度の自動化ができます。
保存したクエリ
よく使う分析関連の SQL をテンプレート的に保存しておき、 EXECUTE IMMEDIATE と CONCAT を使ってあれこれしてていました。
所感
rclone の手順と bq の手順とで病院ごと・月ごと・ファイルの種類ごとに入力が異なるため、タイプミスをしないように気をつける部分がしんどかった。もちろんそれらをくるんだようなシェルスクリプトを作ったり、実施した内容を記録として置いておくのですが、病院からデータを受け取る頻度は多くても月に一度、場合によっては3ヶ月に一度や半年に一度だったりするので、やり方や注意すべき点を忘れてしまうというのが一番の問題でした。
また、スプレッドシートでは一部を変数化することもできるのですが、テーブル名などは変数にできなかったように思います。
trocco 無料プラン導入後
手順
Box から BigQuery : trocco
分析 : trocco / Looker Studio
trocco
無料プランでは転送元と転送先として使用できるコネクタが2種までということなのですが、
転送元 : Box
転送先 : BigQuery
で十分なので問題ありません。入力の文字コードが Shift_JIS でも変換してくれるので Cloud Functions も GCS も不要となりました。
データ転送を束ねたワークフローを作っておくと、 trocco の画面から実行ボタンを押すだけで全てのデータ転送が行われます。
また、データマート機能では SQL を保存しておき、カスタム変数をどこにでも埋め込むことができるので、前述のクエリの保存も不要になるしクエリ自体が trocco に保存されるので安心です。
Looker Studio
こちらについてはデータ投入の話から逸れてしまうので割愛してまた別途書こうと思います。
所感
trocco 自体は前職でも活用させてもらっていたのでその存在は知っていたけど、始めからお金がかかるということでなかなか導入できずにいました。
ですが、あるときにいくらかの制約はあるけど無料プランが始まったということを耳にして使い始めました。
上記のように手順が一気に減っています。
trocco ライトプラン導入と冪等データ投入への欲求
運用が安定していくとともに、分析対象としたい病院が徐々に増えていきました。また、一度取り込んだデータに誤りがあり再度入れ直したいということが発生しました。
無料プランではひと月に使えるの転送時間は10時間なのに対し、基本的に2時間から3時間で推移し多くて5時間くらいで済んでいたのですが、再投入などが発生するとこの上限に引っかかりかねない状況となったので有料のライトプランに移行しました。
投入対象ファイルと投入済みファイルの仕分け
手作業
当初は trocco がアクセスする Box のフォルダから、投入が完了したファイルは手作業で他のフォルダに移していたのですが、そんなことをしていると当然のことですがどこまで投入が終わったかの確認が必要となってきます。
Box Relay の利用開始
Box には Box Relay という自動化のためのノーコードの仕組みがあります。
trocco が BigQuery にデータを投入する際には、当然のことながら Box からファイルをダウンロードするので、 Box Relay で以下のようなワークフローを作成しました。
トリガー : ファイルイベントのダウンロード
イベントが発生するフォルダ : 取り込み対象フォルダ
結果 : ファイルアクションの移動
移動するファイル : フローをトリガーしたファイル
移動先 : 取り込み済みフォルダ
しばらくはこれでうまくいってたのですが、以下のようなときに問題となります。
Box Relay がなぜか発動しないとき : 障害か何か?
BigQuery への投入が失敗したとき
フォーマットがおかしいなどデータがおかしいとき
BigQuery の不調か何か?
BigQuery への取り込みができなかったときであっても、ファイルはダウンロードされているので Box Relay は発動してしまいます。そうなったときは再実行するために投入済みフォルダから適切なファイルを見つけ出して再配置する必要があるのですがこれがなかなかの手間です。
2段階の Box Relay と trocco によるダミー転送
1段目の Box Relay ワークフローではファイルを転送中フォルダに移すようにします。
トリガー : ファイルイベントのダウンロード
イベントが発生するフォルダ : 取り込み対象フォルダ
結果 : ファイルアクションの移動
移動するファイル : フローをトリガーしたファイル
移動先 : 転送中フォルダ
次に2段目の Box Relay ワークフローではイベントが発生するフォルダを転送中フォルにし、移動先を取り込み済みフォルダとします。
トリガー : ファイルイベントのダウンロード
イベントが発生するフォルダ : 転送中フォルダ
結果 : ファイルアクションの移動
移動するファイル : フローをトリガーしたファイル
移動先 : 取り込み済みフォルダ
また、2段目の Box Relay ワークフローが発動するように、つまり転送中フォルダのファイルに対してダウンロードイベントが発生するように、 Box から Box に転送するようなファイル転送を作成しました。実際には読み込んだファイルの内容は使わないので、こんな感じでひたすら読み飛ばすというばち当たり的な処理となっています。

上述のファイル転送が全て成功したらこの転送を実行するようにしていました。
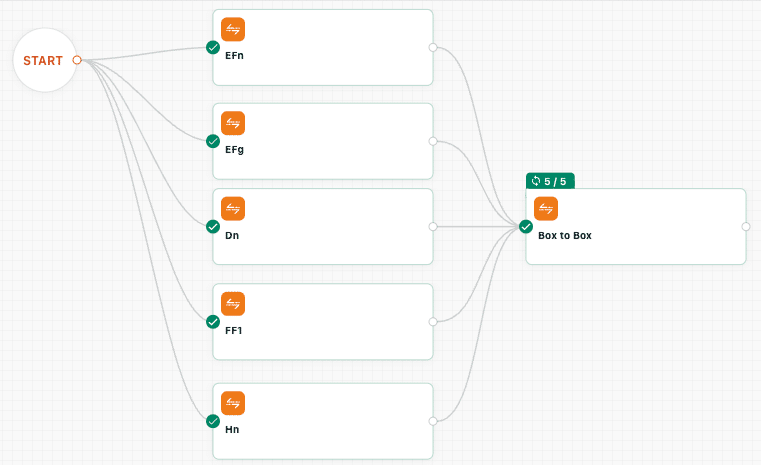
Box API を使ったファイルの移動
本当にしたいことは単にファイルの移動にも関わらず、容量の大きいファイルを2回も trocco 側にダウンロードさせるのは帯域的にも時間的にも無駄だなと感じていたところ、 trocco のワークフローで HTTP リクエストができるようになったというアップデートを目にしました。
troccoのワークフローでHTTPリクエストタスクが作成できるようになりましたyo! pic.twitter.com/zSnxa5Obcc
— Satoshi Hirose / 廣瀬 智史 🐘 (@satoshihirose) December 18, 2023
であるならと、 Box API を叩くための関数を Cloud Functions に用意してその URL を叩くようにしました。

関数の内容は以下のような感じです。
from os import environ
from boxsdk import Client, JWTAuth
from boxsdk.object.file import File
import functions_framework
from flask import abort
@functions_framework.http
def hello_http(request):
if request.headers['X-Foo-Bar'] != environ['Foo_Bar']:
return abort(403)
config = JWTAuth.from_settings_file('/workspace/config.json')
client = Client(config)
src_folder = client.folder(folder_id=environ['BOX_SRC_FOLDER_ID']).get()
dst_folder = client.folder(folder_id=environ['BOX_DST_FOLDER_ID']).get()
prefix = request.args.get('prefix', '')
cnt = 0
for item in src_folder.get_items():
if isinstance(item, File) and item.name.startswith(prefix):
item.move(parent_folder=dst_folder)
print(f'moved {item.name}')
cnt += 1
return f'moved {cnt} files'まとめと今後の課題
これで投入すべきファイルを適切な場所に置いてもらい、 trocco の転送ワークフローを実行すればある程度良い感じにデータが投入され、もし失敗したときもやり直しが簡単になりました。ワークフローから HTTP リクエストが実行できるようになったことで、余計なトラフィックも発生しないようにもなりました。
データが重複してそうかとか欠けてそうかとかに気付きやすいような仕組みを用意したり、期間などを指定してデータを削除するような仕組みも用意したのでひとまずは失敗してもやり直しやすくはなりました。同じファイルを複数回投入したら重複で投入されてしまうので、冪等データ投入の道はまだ先があるとも思いますが、今後も現実的な解決策を探りつつ邁進していこうと思います。
この記事が気に入ったらサポートをしてみませんか?