
自然言語処理における効率的な手法のサーベイ論文紹介[Cohere論文紹介No.3]

論文名
Efficient Methods for Natural Language Processing: A Survey
arXivリンク
https://arxiv.org/pdf/2209.00099.pdf
ひとこと要約
自然言語処理における効率的な手法について包括的にサーベイしている。データ、モデル設計、事前学習、ファインチューニング、推論と圧縮、ハードウェア活用、評価、モデル選択について説明。
メモ
全体像
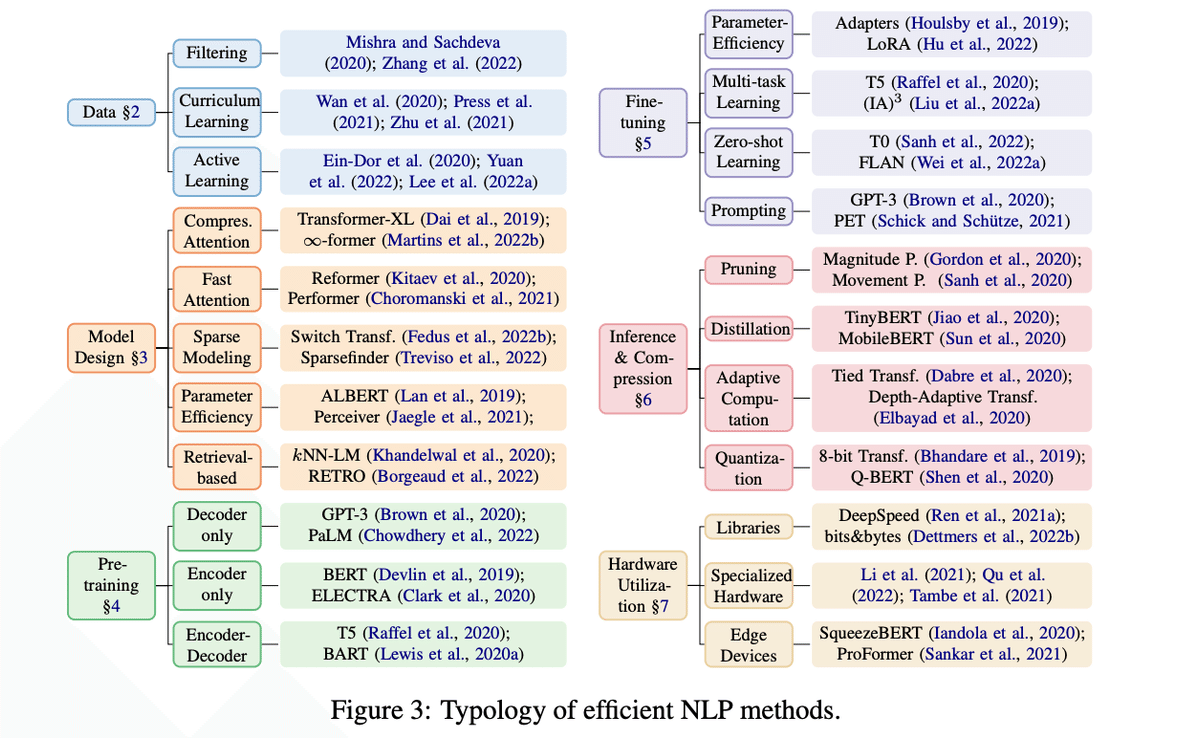
データ
フィルタリング
不要なデータを削除する手法。例えば、Lee et al. (2022b)は事前学習データの重複を削除することで、モデルの性能を維持しつつ学習効率を改善できることを示した。ただし十分なデータがない場合は効果が限定的。
アクティブラーニング
モデルの学習に最も役立つデータを選択的にアノテーションすることで、データ効率を改善する手法。データの有用性は、モデルの不確実性や、データの多様性などに基づいて評価される。モデルに依存した選択バイアスが生じる可能性や、難しいデータが選ばれることによるアノテーションコストの増加などの課題がある。
カリキュラムラーニング
データを易しいものから難しいものへと順番に学習することで、必要な学習ステップ数を削減する手法。データの難易度は文の長さなどのヒューリスティックに基づいて決定。ただし、データの難易度を適切に設定することが難しく、易しいデータに計算リソースを無駄に使ってしまう課題がある。
モデル設計
WIP: TransformerのAttensitonの改良(数が多いので、詳細なサーベイは気が向いたらします。)
再帰的な構造により、既に処理された部分を有効活用(Dai et al., 2019)
局所的なAttensionと大域的なAttentionを分離(Ainslie et al., 2020)
スパースモデリング
MoE
Switch Transformer
GLaM
Sparsefinder
パラメータ効率
ALBERT: 層間でパラメータ共有
Perceiver:入力ベクトルを潜在ベクトルに写像
検索ベース
RETRO: データベースから関連トークンを検索して、25倍パラメータ効率化
事前学習
モデリング
次のトークンを予測する因果言語モデリング(CLM)
ランダムにマスクされたトークンを充填するマスク言語モデリング(MLM)
ファインチューニング
パラメータ効率の良いファインチューニング
Adapter
LoRA
Prefix-tuning
Prompt-tuing
マルチタスク学習
T5や(IA)^3
ゼロショット学習
T0やFLAN
プロンプティング
推論とモデル圧縮の効率化
枝刈り (Pruning)
重要でない重みを削除することで、計算量とメモリ使用量を削減する手法。枝刈りは、事前学習やファインチューニングの段階で適用。
知識蒸留 (Knowledge Distillation)
大きな教師モデルの知識を用いて、小さな生徒モデルを学習する手法。これにより、モデルサイズを削減しつつ、性能を維持することが可能。
量子化 (Quantization)
モデルの重みを低ビット数で表現することで、メモリ使用量と計算量を削減する手法。量子化は、学習中に適用することで、量子化後の性能低下を抑制。また、モデルの各部分に適した量子化ビット数を適用する混合精度量子化も有効。
適応的な計算 (Adaptive Computation)
入力に応じて計算量を動的に変更する手法。例えば、早期終了 (Early Exit) や mixture-of-experts (MoE) などがこれに該当。
ハードウェアの効率化
オプティマイザのメモリ削減
重み更新のために保存する勾配は、メモリ消費の大きな要因となる。DeepSpeed (Ren et al., 2021a) などのライブラリでは、保存した勾配をGPUからCPUのRAMにオフロードすることで、メモリ消費を削減。また、bitsandbytes (Dettmers et al., 2022b) では、動的なブロック単位の量子化を用いて、メモリ使用量を削減。
特殊なハードウェアの活用
量子化や枝刈りなどの効率化手法に特化したハードウェアが開発。これらのハードウェアでは、CPUやGPUでは実現できない超低ビット数や混合精度の計算が可能。また、冗長な注意機構のヘッドやトークンを予測・削除するためのハードウェアも提案されている。
ハードウェアとソフトウェアの協調設計
例えば、Lepikhin et al. (2021) は、コンパイラの改善によって並列化を大幅に向上。また、mixture-of-expertsモデルや注意機構に特化したハードウェアとソフトウェアの協調設計も提案されている。
エッジデバイス向けの最適化
エッジデバイスでは、計算リソースとメモリが限られているため、別の効率化手法が必要。例えば、SqueezeBERT (Iandola et al., 2020) では、Attensionにグループ畳み込みを組み込むことで、モバイルデバイス上での効率を改善。
効率性の評価
パレート最適性
タスクの性能と資源消費のトレードオフを考慮。パレート最適な解とは、他のシステムが同等以上の性能を達成するためにより多くの資源を消費する必要がある解を指す。
評価指標
FLOP/s(1秒あたりの浮動小数点演算数)や消費電力など。ただし、これらの指標には不確実性があり、ハードウェアの特性に依存する可能性。
炭素排出量
消費電力に基づいて、プログラムの実行に伴う炭素排出量を推定。ただし、炭素排出量は、エネルギー源の炭素強度に依存するため、低消費電力が必ずしも低炭素排出量を意味するわけではない。
モデル選択
ハイパーパラメータ探索
グリッドサーチや手動でのチューニングは非効率的であるため、ベイズ最適化 (Snoek et al., 2012; Feurer et al., 2015) やグラフベースの半教師あり学習 (Zhang and Duh, 2020) などの手法が提案されている。Successive Halving (Jamieson and Talwalkar, 2016) やその並列版であるASHA (Li et al., 2020b) は、複数のハイパーパラメータ設定を並列に評価し、性能の悪い設定を順次棄却することで、効率的な探索を実現可能。
ハイパーパラメータ転移
ハイパーパラメータ探索に必要な試行回数を最小限に抑えるために、他のデータセットやタスクから知識を転移する手法。ベイズ最適化と組み合わせたTransfer Neural Processes (Wei et al., 2021) やμTransfer (Yang et al., 2021) などが提案されている。
この記事が気に入ったらサポートをしてみませんか?