
日本語の高性能な文埋め込みモデルを試す

tl;dr
PKSHA Technologies の矢野さんから GLuCoSE v2 とRoSEtta が公開
名古屋大学の塚越さんから Ruri が公開(合わせて Reranker も)
モデルを動かすサンプルコードの実行手順とそれぞれのモデルを試せるデモアプリケーションを本記事最下部に記載、公開
使用するモデル
我流で紹介するより引用の方がわかりやすいので引用させてください。いずれのモデルも商用利用可能なライセンスで公開されています。それぞれの(主たる?)開発者の方の投稿も。
(1) 「検索に特化した日本語文埋め込みモデル GLuCoSE v2」
言葉の意味を考慮してベクトル形式に変換する文埋め込み技術を実現する手法として、近年はLLMに追加学習を行う手法が提案されています。LLMを元にした大規模な文埋め込みモデルは、高性能であるものの推論コストが高いという課題から利用可能なシーンは限られます。
本研究では蒸留という技術を用いて大規模な文埋め込みモデルの知識を軽量な文埋め込みモデルであるGLuCoSEに落とし込み、さらに検索に特化した追加学習を行うことで、特に検索タスクで高性能かつ低コストで利用可能な日本語文埋め込みモデルを構築しました。その結果、検索タスクおよび文埋め込み技術の包括的な評価において、先行研究を上回りました。本研究の成果であるモデルをGLuCoSE v2という名称で、商用利用可能なライセンスで公開いたしました。
(2)「長い入力系列に対応した日本語文埋め込みモデル RoSEtta 」
LLMと検索拡張生成(Retrieval-Augmented Generation、以下RAG)の活用において、長文を含む多様なドキュメント処理のニーズが高まっています。しかし、現在の日本語文埋め込みモデルの多くは最大入力長系列について512トークンまでの制限があり、1024トークン以上を扱える実用的な軽量モデルが存在しませんでした。
本研究では、長い系列を扱う場合に適切とされている相対位置埋め込み「RoPE」を取り入れたBERT、「RoFormer」に事前学習・事後学習を行い、最大1024トークンの系列を扱うことのできる日本語文埋め込みモデルを構築しました。GLuCoSE v2と同様の蒸留と検索に特化した追加学習によって、包括的な評価において先行研究に対して同等以上の性能になりました。本研究の成果であるモデルをRoSEtta(RoFormer-based Sentence Encoder through Distillation)という名称で、商用利用可能なライセンスで公開いたしました。
検索に特化した文埋め込みモデルと、ちょっと長い系列に対応した文埋め込みモデルを作って公開しました!
— やの (@yano0_c) September 4, 2024
明日の朝イチセッションで発表します!!!!モデル公開リンクはプレスからどうぞ!!! https://t.co/Ius9Oqvwj7
日本語に特化した汎用埋め込みモデル 𝗥𝘂𝗿𝗶 を公開しました!
— hpp (@hpp_ricecake) September 4, 2024
Ruriは
1. LLMを用いた合成データセット作成
2. 大規模な対照事前学習
3. 高品質なラベル付きデータによる学習
の3 stepにより、JMTEBベンチマークにおいて同等規模のモデルを大きく上回る性能を達成しましたhttps://t.co/oF9HFRC9sr
環境構築
手元の macOS 上で実行しましたが、環境が違えど手順は同じかと思います。
まずは作業ディレクトリを作成します。
mkdir playground-embedding
cd playground-embeddingそれぞれの embedding 用のファイルを用意します。
touch GLuCoSE-base-ja-v2.py
touch RoSEtta-base-ja.py
touch ruri-large.pyuv 経由で必要なパッケージをインストールします。
uv init
uv add sentence-transformers
uv add fugashi
uv add unidic_lite
uv add sentencepiece
uv syncもし uv をお使いでない場合は下記の公式インストールページを参照してインストールしてください。macOS をお使いであれば `brew install uv` だけで uv を入れられます。
サンプルコードを参考に各ファイルを作成します。
# GLuCoSE-base-ja-v2.py
import torch
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("pkshatech/GLuCoSE-base-ja-v2")
# Don't forget to add the prefix "query: " for query-side or "passage: " for passage-side texts.
sentences = [
"query: PKSHAはどんな会社ですか?",
"passage: 研究開発したアルゴリズムを、多くの企業のソフトウエア・オペレーションに導入しています。",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [2, 768]
# Convert NumPy array to PyTorch tensor
embeddings_tensor = torch.from_numpy(embeddings)
# Get the similarity scores for the embeddings
similarities = F.cosine_similarity(
embeddings_tensor.unsqueeze(0), embeddings_tensor.unsqueeze(1), dim=2
)
print(similarities)# RoSEtta-base-ja.py
import torch
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("pkshatech/RoSEtta-base", trust_remote_code=True)
# Don't forget to add the prefix "query: " for query-side or "passage: " for passage-side texts.
sentences = [
'query: PKSHAはどんな会社ですか?',
'passage: 研究開発したアルゴリズムを、多くの企業のソフトウエア・オペレーションに導入しています。'
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [2, 768]
# Convert NumPy array to PyTorch tensor
embeddings_tensor = torch.from_numpy(embeddings)
# Get the similarity scores for the embeddings
similarities = F.cosine_similarity(embeddings_tensor.unsqueeze(0), embeddings_tensor.unsqueeze(1), dim=2)
print(similarities)# ruri-large.py
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("cl-nagoya/ruri-large")
# Don't forget to add the prefix "クエリ: " for query-side or "文章: " for passage-side texts.
sentences = [
"クエリ: 瑠璃色はどんな色?",
"文章: 瑠璃色(るりいろ)は、紫みを帯びた濃い青。名は、半貴石の瑠璃(ラピスラズリ、英: lapis lazuli)による。JIS慣用色名では「こい紫みの青」(略号 dp-pB)と定義している[1][2]。",
"クエリ: ワシやタカのように、鋭いくちばしと爪を持った大型の鳥類を総称して「何類」というでしょう?",
"文章: ワシ、タカ、ハゲワシ、ハヤブサ、コンドル、フクロウが代表的である。これらの猛禽類はリンネ前後の時代(17~18世紀)には鷲類・鷹類・隼類及び梟類に分類された。ちなみにリンネは狩りをする鳥を単一の目(もく)にまとめ、vultur(コンドル、ハゲワシ)、falco(ワシ、タカ、ハヤブサなど)、strix(フクロウ)、lanius(モズ)の4属を含めている。",
]
embeddings = model.encode(sentences, convert_to_tensor=True)
print(embeddings.size())
# [4, 1024]
similarities = F.cosine_similarity(embeddings.unsqueeze(0), embeddings.unsqueeze(1), dim=2)
print(similarities)
# [[1.0000, 0.9429, 0.6565, 0.6997],
# [0.9429, 1.0000, 0.6579, 0.6768],
# [0.6565, 0.6579, 1.0000, 0.8933],
# [0.6997, 0.6768, 0.8933, 1.0000]]基本的にサンプルコードをそのまま実行していますが、RoSEtta-base-ja に関して下記のエラーに遭遇し、`trust_remote_code=True` の記述が必須でしたので加えています。また、ruri-large では sentences に `"クエリ: xxx"`あるいは `"文章: yyy"`、GLuCoSE-base-ja-v2 / RoSEtta-base-ja では `"query: xxx"`あるいは`"passage: yyy"`といった指定が必要であることにご注意ください。
ValueError: Loading pkshatech/RoSEtta-base requires you to execute the configuration file in that repo on your local machine. Make sure you have read the code there to avoid malicious use, then set the option `trust_remote_code=True` to remove this error.GLuCoSE-base-ja-v2 / RoSEtta-base-ja のどちらもサンプルコードでは unsqueeze メソッドがないので numpy から PyTorch tensor に変換しています。
モデルの実行
各ファイルの実行。初回実行時にモデルのダウンロードが入るため、少し時間がかかります。
uv run ruri-large.py
uv run RoSEtta-base-ja.py
uv run GLuCoSE-base-ja-v2.py手元の実行結果を記載します。
$ uv run ruri-large.py
torch.Size([4, 1024])
tensor([[1.0000, 0.9429, 0.6565, 0.6997],
[0.9429, 1.0000, 0.6579, 0.6768],
[0.6565, 0.6579, 1.0000, 0.8933],
[0.6997, 0.6768, 0.8933, 1.0000]], device='mps:0')$ uv run RoSEtta-base-ja.py
(2, 768)
tensor([[1.0000, 0.5910],
[0.5910, 1.0000]])$ uv run GLuCoSE-base-ja-v2.py
(2, 768)
tensor([[1.0000, 0.6050],
[0.6050, 1.0000]])それぞれのモデルを試せるデモアプリケーション
上記で言及した三つのモデルを統一的に使えるデモアプリケーションを作成します。ただし、先述したように Ruri を使う際はクエリと文章が必要になることにご注意ください。
パッケージを追加します。
uv add gradioちなみに蛇足ですが、uv を使われている方向けですが `uvx ruff format app.py` とすると ruff を簡単に実行できます。
ファイルを作成します。
touch app.pyapp.py の中身を下記のように記述します。
# app.py
import gradio as gr
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
def load_model(model_name):
if model_name == "GLuCoSE-base-ja-v2":
return SentenceTransformer("pkshatech/GLuCoSE-base-ja-v2")
elif model_name == "RoSEtta-base":
return SentenceTransformer("pkshatech/RoSEtta-base", trust_remote_code=True)
elif model_name == "ruri-large":
return SentenceTransformer("cl-nagoya/ruri-large")
def get_similarities(model_name, sentences):
model = load_model(model_name)
if model_name in ["GLuCoSE-base-ja-v2", "RoSEtta-base"]:
sentences = [
"query: " + s if i % 2 == 0 else "passage: " + s
for i, s in enumerate(sentences)
]
elif model_name == "ruri-large":
sentences = [
"クエリ: " + s if i % 2 == 0 else "文章: " + s
for i, s in enumerate(sentences)
]
embeddings = model.encode(sentences, convert_to_tensor=True)
similarities = F.cosine_similarity(
embeddings.unsqueeze(0), embeddings.unsqueeze(1), dim=2
)
return similarities.cpu().numpy()
def format_similarities(similarities):
return "\n".join([" ".join([f"{val:.4f}" for val in row]) for row in similarities])
def process_input(model_name, input_text):
sentences = [s.strip() for s in input_text.split("\n") if s.strip()]
similarities = get_similarities(model_name, sentences)
return format_similarities(similarities)
models = ["GLuCoSE-base-ja-v2", "RoSEtta-base", "ruri-large"]
with gr.Blocks() as demo:
gr.Markdown("# Sentence Similarity Demo")
with gr.Row():
with gr.Column():
model_dropdown = gr.Dropdown(
choices=models, label="Select Model", value=models[0]
)
input_text = gr.Textbox(
lines=5,
label="Input Sentences (one per line)",
placeholder="Enter query and passage pairs, alternating lines.",
)
gr.Markdown("""
**Note:** Prefixes ('query:' / 'passage:' or 'クエリ:' / '文章:') are added automatically. Just input your sentences.
""")
submit_btn = gr.Button(value="Calculate Similarities")
with gr.Column():
output_text = gr.Textbox(label="Similarity Matrix", lines=10)
submit_btn.click(
process_input, inputs=[model_dropdown, input_text], outputs=output_text
)
gr.Examples(
examples=[
[
"GLuCoSE-base-ja-v2",
"PKSHAはどんな会社ですか?\n研究開発したアルゴリズムを、多くの企業のソフトウエア・オペレーションに導入しています。",
],
[
"RoSEtta-base",
"PKSHAはどんな会社ですか?\n研究開発したアルゴリズムを、多くの企業のソフトウエア・オペレーションに導入しています。",
],
[
"ruri-large",
"瑠璃色はどんな色?\n瑠璃色(るりいろ)は、紫みを帯びた濃い青。名は、半貴石の瑠璃(ラピスラズリ、英: lapis lazuli)による。JIS慣用色名では「こい紫みの青」(略号 dp-pB)と定義している[1][2]。\nワシやタカのように、鋭いくちばしと爪を持った大型の鳥類を総称して「何類」というでしょう?\nワシ、タカ、ハゲワシ、ハヤブサ、コンドル、フクロウが代表的である。これらの猛禽類はリンネ前後の時代(17~18世紀)には鷲類・鷹類・隼類及び梟類に分類された。ちなみにリンネは狩りをする鳥を単一の目(もく)にまとめ、vultur(コンドル、ハゲワシ)、falco(ワシ、タカ、ハヤブサなど)、strix(フクロウ)、lanius(モズ)の4属を含めている。",
],
],
inputs=[model_dropdown, input_text],
)
demo.launch()
app.py を実行します。
uv run app.pyローカルサーバが立ち上がるのでブラウザで `http://127.0.0.1:7860` を開いてください。
$ uv run app.py
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.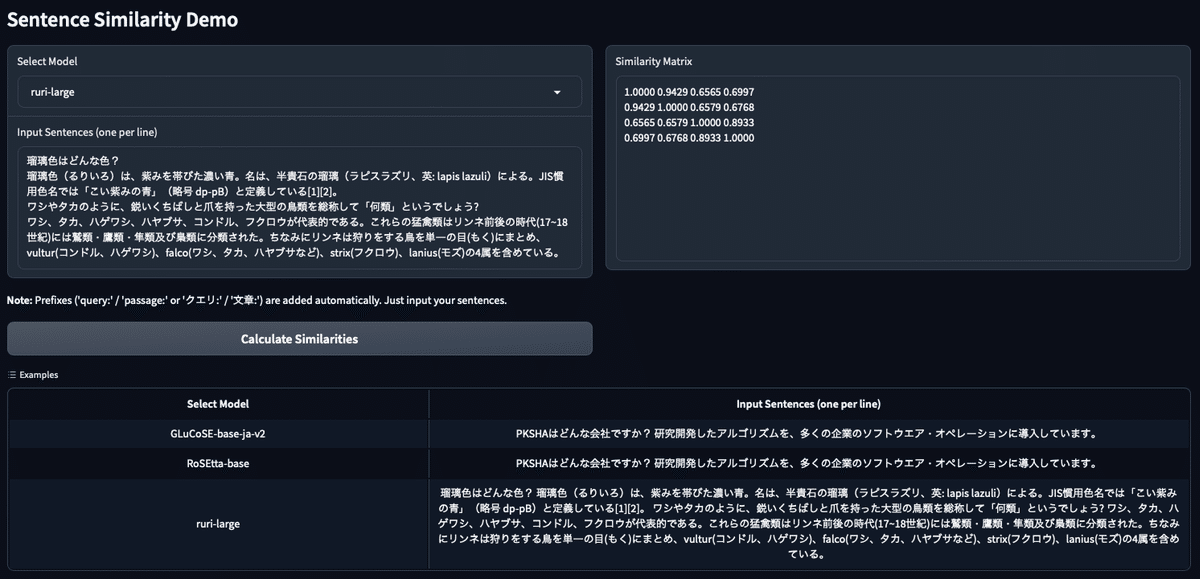
追記1
GLuCoSE v2 とRoSEtta を使う際も query: / passage: の prefix が必要だそうです。モデルカードが更新され次第、手元で確認し、修正箇所が発生した際は記事を修正しておきます。
早速!さすが!ありがとうございます!!
— やの (@yano0_c) September 4, 2024
おかげさまでどこにも書いていないことを思い出したのですが、GLuCoSE v2やRoSEttaを使う際にはquery: とpassage: というプレフィックスが必要です🙇♂️🙇♂️(mE5などと同様) モデルカードに追記しておきますが、noteの方は可能でしたら追記頂けると助かります…!
追記2
2024/9/9 時点のモデルカードの最新版に対応、prefix 部分と推論コードを修正しました。また、上記の比較デモを Hugging Face Spaces にて公開しました。
最後に
海外だと BAAI や Jina、intfloat あたりが埋め込みモデルを頑張っている印象ですが、日本語文書用途の RAG であればわざわざマルチリンガルのものを使わずとも良いと思うので、商用利用可で公開してくださるのはうれしいですね!
締めるのに適した言葉が特に思いつかず恐縮ですが、note や X をフォローいただけるとうれしいです!