
OpenAI WhisperでYouTubeや音源を文字起こしする方法

こんにちは、Choimirai Schoolのサンミンです。
【主要な変更内容】
(2022.09.26)Gradioに音源をアップする機能を追加
(2022.09.25)番外編:CLIで文字起こしする方法を追加
0 はじめに
GogoleColabのnotebookで紹介しているWhisperは、PythonライブラリーのGradioを利用して実装しています。GUIの詳細は下記図と説明を参照してください。
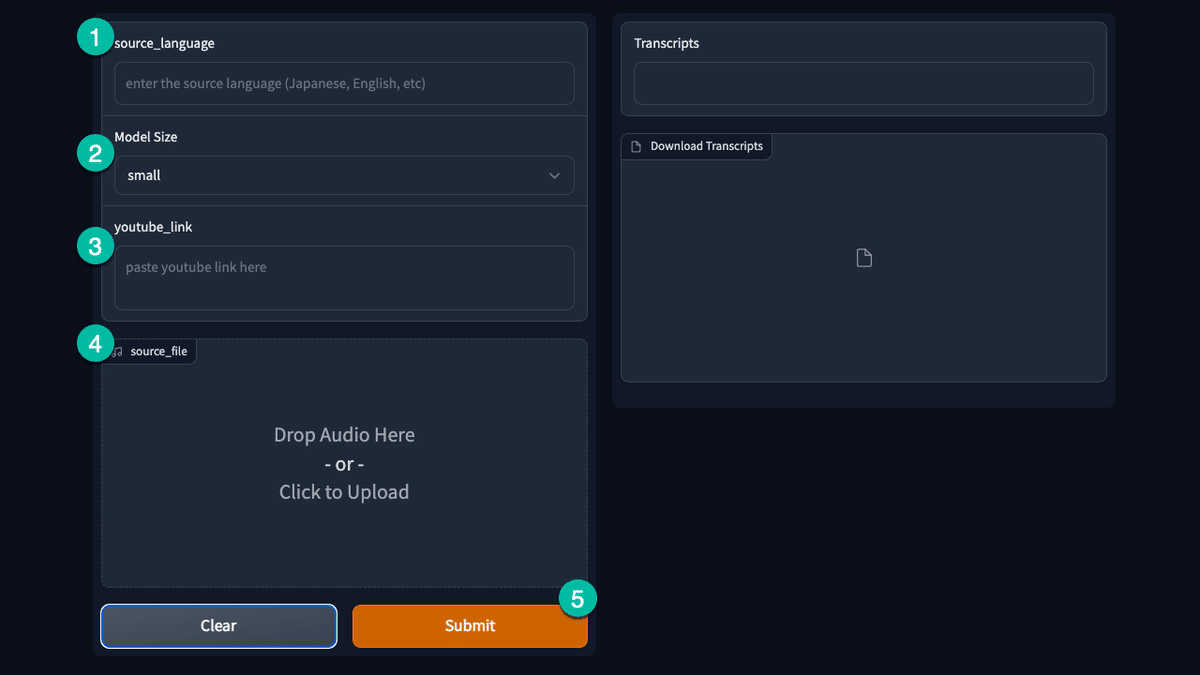
①YouTube動画や音源の言語:音源に合わせ、JapaneseやEnglishを入力
②文字起こし時に利用するモデル:medium以上がオススメです
③YouTube動画へのリンク:該当動画へのリンクを貼り付けます
④音源のアップロード:ご自分お音源をアップできます
⑤「Submit」ボタンの押下で処理がスタートします
※重要:
1. ③と④は、一つだけを入力してください
2. アップされた音源や文字起こしされた情報はサーバーに残ります
3. デモ用のリンク先は予告なしで利用できなくなる可能性があります
4. リンク先が変わる時もあります。上記の図からアクセスしてください
5. 文字起こしのリクエストが多いと比例して所用時間も長くなります
OpenAIのWhisperを利用すれば誰でも簡単に文字起こしができます。しかも、無料で!
. @OpenAI のWhisperを使ってひろゆき(@hirox246)さんのYouTube動画を文字起こししてみた。想像以上にすごい😮。 https://t.co/DY14ZYoCxE pic.twitter.com/dSeEAW4BgW
— sangmin.eth @ChoimiraiSchool (@gijigae) September 24, 2022
今回のnoteでは噂のWisperをGoogle Colabで実行する方法をシェアします。文字起こしの対象とするのはこちらの動画です。
1 Google Colabページを開く
手順はとても簡単。下記のリンクをクリックしますとWhisper YouTube in SRTのページへ遷移います。
Google Colabのページはこのまま操作してもいいですし、ご自分のGoogle Driveへコピーして利用することもできます。コピーする際は、「Copy to Drive」を押下してください。

2 RuntimeをGPUに変更
ページが表示されましたら、まずRuntimeをクリックし、

Runtimeの種別をGPUに変更してください。
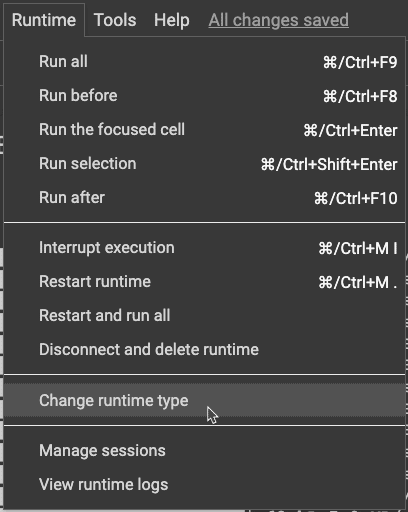
Hardware acceleratorをGPUに変更し、Saveで変更内容を保存します。

3 パッケージのインストール
元のページへ戻りましたら、①のボタンを押して、必要なパッケージをインストールします。

インストールが無事に終わりますと次のようなテキストが表示されます。
4 YouTubeの文字起こし
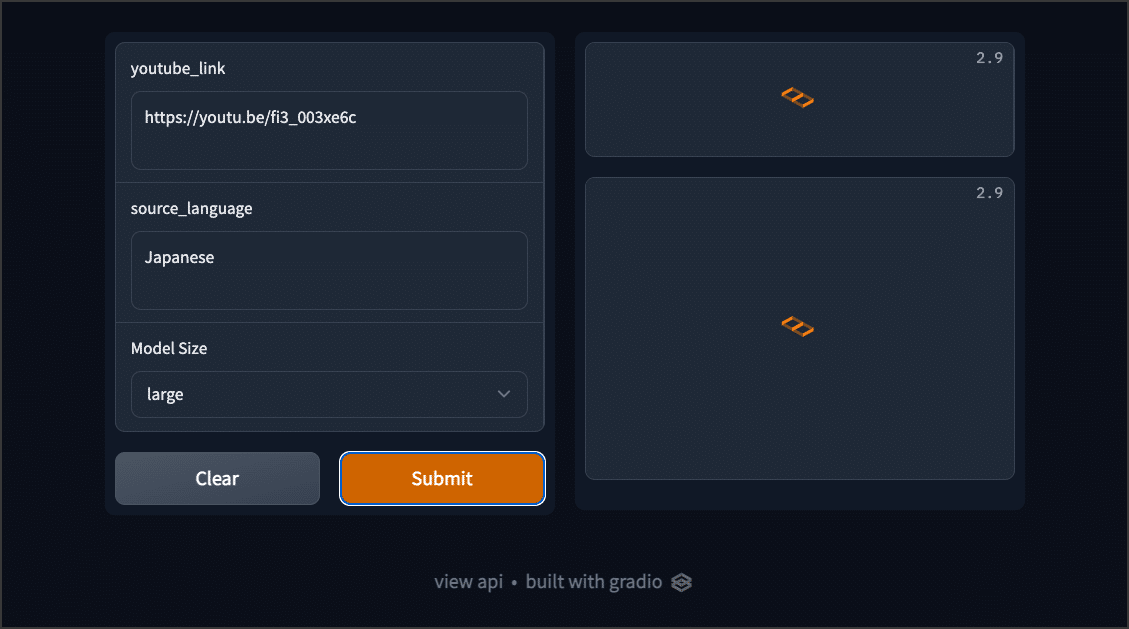
パッケージのインストールが終わりましたら次はアプリの立ち上げです。「Launch the APP」のすぐ下にある②のボタンを押下してください。少し時間が経ちますと次のように Gradio の画面が表示されます。

それぞれのテキストボックスに必要な情報を入力し「Submit」ボタンをクリックします。
youtube_link: YouTube動画へのリンク
source_langage: 該当動画の言語
Model Size: 文字起こしに利用するモデル

下記の図は、記入例の一つです。

Submitボタンを押しますと次のようにタイマーがスタートします。
5 音源の文字起こし
【追記:2022.09.26】ファイルをアップロードする機能を追加しました。ご自分のファイルを使って文字起こしをする時は、YouTube Link欄を空欄にしたまま、ファイルをアップロードし「Submit」ボタンを押してください。

下記のツイートは、音源のアップロードから文字起こしまでの一連の流れを録画した動画です。
音源をアップロード+文字起こしが完了するまでの流れを録画した動画です📺。Whisperのlargeモデルを利用した場合の所要時間は、6分の動画に対し、8分でした。mediumモデルを選択しますと4分前後で終わると思います。 pic.twitter.com/0zqyGAApde
— sangmin.eth @ChoimiraiSchool (@gijigae) September 26, 2022
6 モデルの種類
モデルサイズが小さければ小さいほど処理スピードは早くなりますが、精度は落ちます。まずは、largeモデルから試すことをお勧めしたいです。
長さ6分の動画の場合、文字起こしにかかる時間の目安は、
Large: 7分
Medium: 3~4分
Small: 1~2分
7 字幕をダウンロード
文字起こしの作業が完了しますと画面の上には字幕のテキストが表示され、下へスクロールしますと次のように字幕をファイルとしてダウンロードできるセクションがあります。
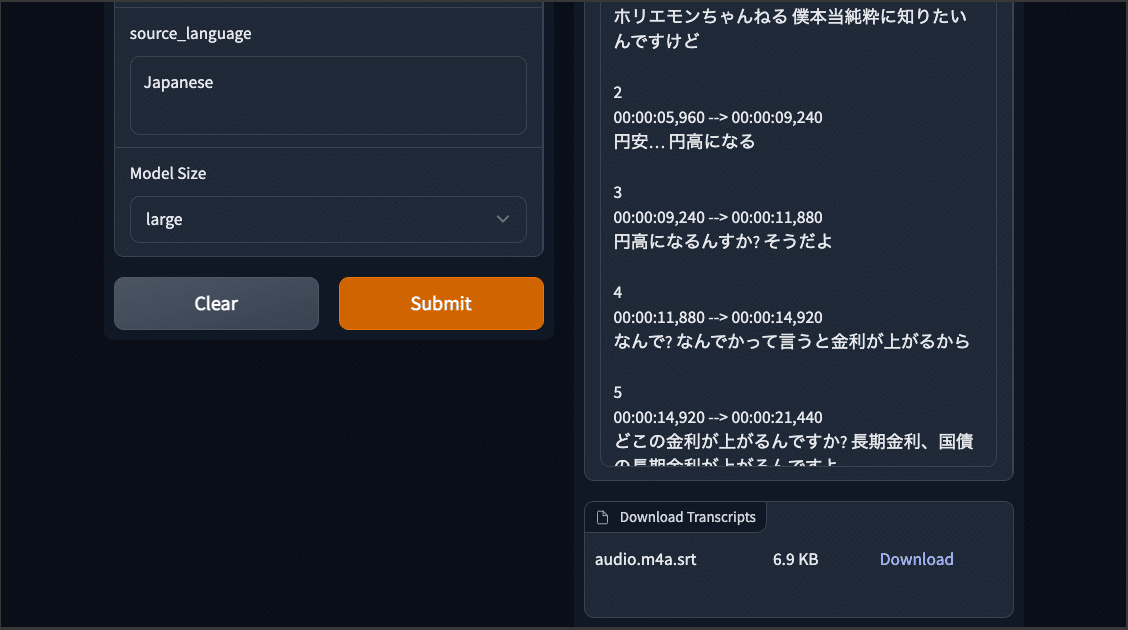
Downloadのボタンをクリックしますとファイルがローカル環境へダウンロードされます。下記のテキストは、堀江さんの動画をLargeモデルで書き起こし+ダウンロードした字幕です。
1
00:00:00,000 --> 00:00:05,960
ホリエモンちゃんねる 僕本当純粋に知りたいんですけど
2
00:00:05,960 --> 00:00:09,240
円安… 円高になる
3
00:00:09,240 --> 00:00:11,880
円高になるんすか? そうだよ
4
00:00:11,880 --> 00:00:14,920
なんで? なんでかって言うと金利が上がるから
5
00:00:14,920 --> 00:00:21,440
どこの金利が上がるんですか? 長期金利、国債の長期金利が上がるんですよ
6
00:00:21,440 --> 00:00:29,040
じゃあどういうことかって言うと金融ひきめになるわけ 要はコロナでめちゃくちゃ金融緩和してたでしょ世界的にね
全文はこちらのファイルを参考にしてください。
8 まとめ
今回シェアしたGoogle Colabを利用すれば、どなたでも簡単に高い精度の文字起こしができます。あと、OpenAIのWhisperはオープンソースとして公開されていますので今後、話者ごとの文字起こしなど新たな機能も追加されていくと期待しています。
Whisperはオープンソースとして公開されているので、いろんなチームが加わって発展させていくはず。すると、音紋を使って話者を識別し、話者ごとの文字起こしができるのも時間の問題。言語に関わる仕事をされている方は、技術の変化に注目すべきです。
— sangmin.eth @ChoimiraiSchool (@gijigae) September 24, 2022
9 番外編:CLIで文字起こし
シェアしたGoogle Colabからはご自分の音源をアップロードし、文字起こしをすることもできます。手順は、
1. 左にあるフォルダを選択
2. contentの右側にある3つの点を押下
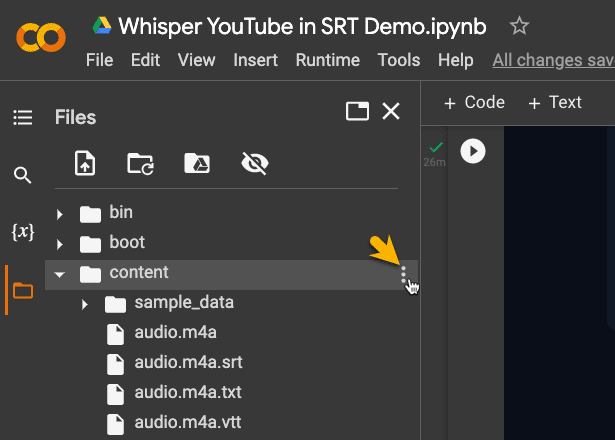
3. UploadメニューからローカルのファイルをColabへアップ
4. 新しいセルを追加し下記のコードを実行
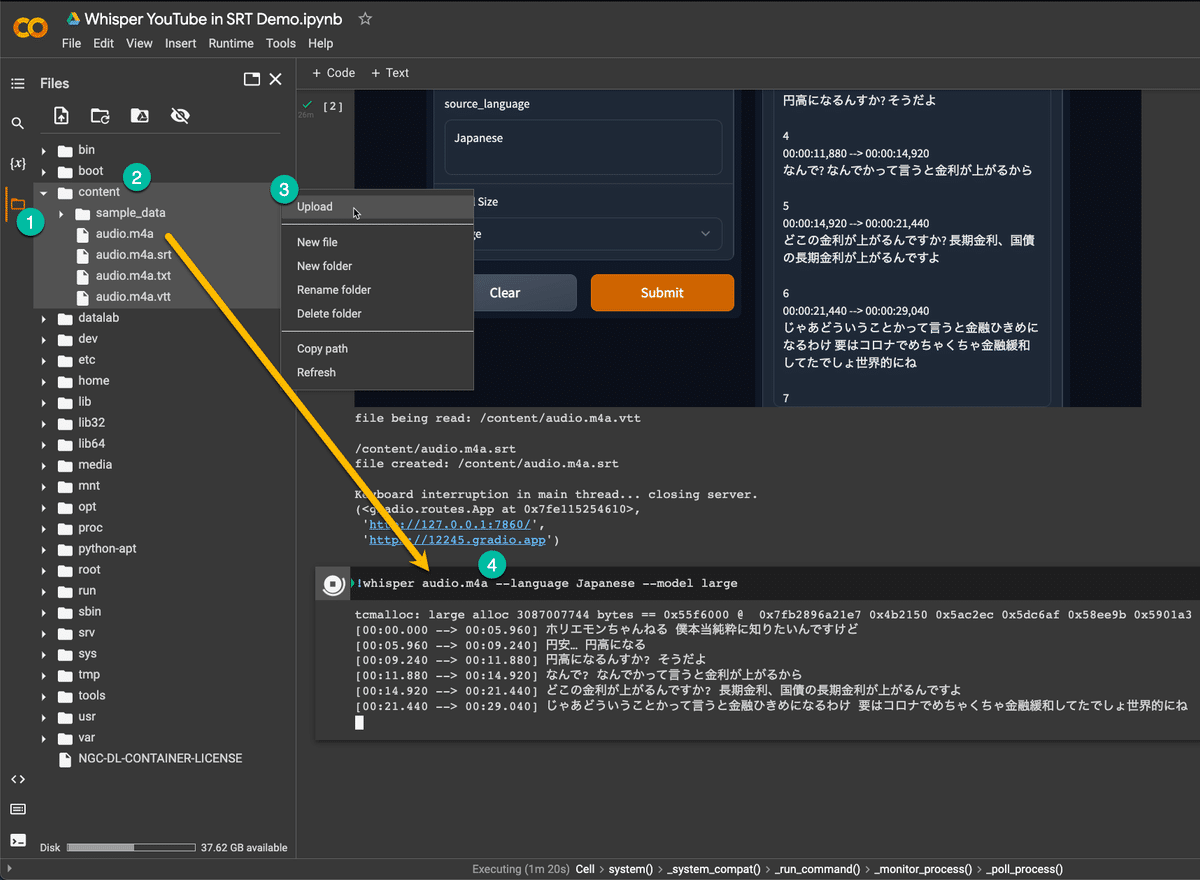
注意:下記のコードにある「audio.m4a」はcontentフォルダにアップロードしたファイル名です。ファイル名に合わせ、変更してください。
!whisper audio.m4a --language Japanese --model large生成された文字起こしのファイルはcontentフォルダに保存されます。文字起こしの結果を英語に翻訳したい場合は、"--task translate" のパラメータを渡すだけで対応できます。
!whisper audio.m4a --language Japanese --model large --task translateこの記事が気に入ったらサポートをしてみませんか?