Bert-VITS2をvits-simple-apiを利用してAPIを通して推論する方法(2023-12-13)

Artrajz/vits-simple-apiを利用すると、VITS API をシンプルにコールすることができます。
text2speech や音声変換の機能を備えています。Bert-VITS2 モデルにも対応しています。
HuggingFace Spacesにオンラインデモがありますので、導入前に使用感を掴むことができます。ただし、Bert-VITS2モデルはホストされていなかったので試せませんでした。
CPU 版と、CUDA を利用して高速推論できる GPU 版があります。
7z でも配布されているため、Git 操作ができなくても利用できます。が、なぜか配布されている 7z の展開に失敗したため、今回は Git を使用します。
Docker イメージが配布されているので、デプロイもしやすそうです(未検証)。
なお、モデルの学習およびUI上での推論はBert-VITS2 (ver 2.1) の学習方法(2023-12-01)の記事がたいへん詳しいです。
2023/12/18追記:
EasyBertVits2を利用すると導入を自動化することができ、APIも利用できるようです。が、現状出力フォーマットがwav固定となるため、mp3等で得たい場合はvits-simple-apiに分がありそうです。
https://github.com/Zuntan03/EasyBertVits2
導入
README.mdに丁寧に書かれているのですが、ここでも簡単に翻訳します。
リポジトリをクローンする
Git の導入がまだの方は先にインストールしてください。
インストールしたいディレクトリで右クリック→「Git Bash Here」して、以下のコマンドを実行してください。今回は C:\ にインストールしました。
git clone https://github.com/Artrajz/vits-simple-api.gitResolving deltas: 100% (1515/1515), done. と出れば成功です。
依存関係をインストールする
Python を導入していない場合、先にインストールします。(Add Python to PATHにチェックを入れて、パスを通しておいてください。)
先に仮想環境に入ります。Powershellで一行ずつ実行してください。
cd c:\vits-simple-api
python -m venv venv
.\venv\Scripts\Activate.ps1
仮想環境内で以下を実行すると仮想環境内に依存関係をインストールできます。
pip install -r requirements.txt途中、pybind11が無いぞと怒られた場合、以下のコマンドで別途インストール(アップグレードは必要ないかも):
pip install wheel setuptools pip --upgrade
pip install pybind11pyopenjtalkだと変なのが入るらしいので以下を実行:
pip install pyopenjtalk-prebuiltERROR: Could not build wheels for fasttext, which is required to install pyproject.toml-based projectsと言われたので以下を実行:
pip install fasttext-wheelそして requirements.txtからpyopenjtalkとfasttextを削除し、再度requirements.txtをインストールしました。pip listで一通り入っていたら成功です。
pip install -r requirements.txtなお、ここまで終わってから README.md にもfastText と pyopenjtalk についての補足があることに気付きました。かなしい。
また、感情ベクトルを生成するモデルが何故かダウンロードされずエラーが出るので手動でダウンロードしておきましょう。
curl -L -o bert_vits2/emotional/wav2vec2-large-robust-12-ft-emotion-msp-dim/pytorch_model.bin https://huggingface.co/audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim/resolve/main/pytorch_model.bin ~ここまで1時間~
依存関係のインストールが完了したら、venv内で以下を実行します。
python app.pyなにやらAPI_KEYやUsernameやらPasswordやら色々と出てきますが、これらは ./config.yml に自動で保存されています。Username と Password は /admin を使用するときに必要になります。API_KEYはconfig.pyで設定することで有効にできます(後述)。
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:23456
* Running on http://192.168.0.106:23456
2023-12-13 11:14:11 [INFO] [_internal._log:187] Press CTRL+C to quitと表示されたらサーバー起動成功です。Ctrl を押しながら URL をクリックすると、ブラウザで Web UI が開きます。( http://localhost:23456/ )
モデルのロード
初期状態だとモデルが追加されていないので、id のプルダウンに未加载任模型(モデル未ロード)と表示されています。
UI もシンプルで良い。
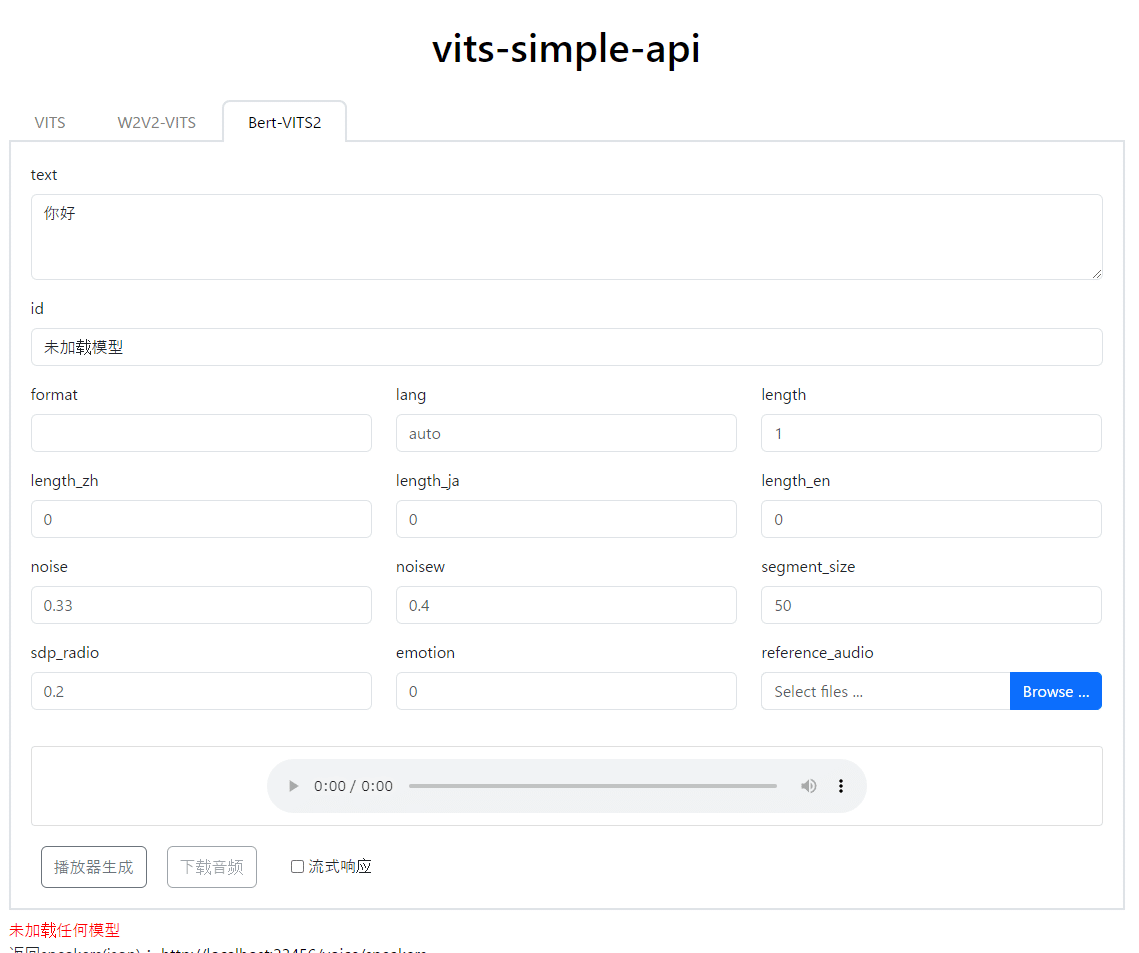
./Model/ フォルダに、モデルごとのフォルダを作成して .pth と config.json を入れます
./config.yml の model_config.model_list[] (38行目くらい) に以下のようにモデルを配置します。
'model_config':
'model_list': [
[model1/G_1000.pth, model1/config.json],
[model2/G_1000.pth, model2/config.json],
]今回は以下のようにしました。
'model_config':
"model_list": [[A/G_7000.pth, A/config.json]]config.json を変更したら、ターミナルで Ctrl+C しサーバーを停止し、再度起動してください。
再起動したら何故か pytorch_model.bin のダウンロードが始まるので神妙に待ちます。
API リファレンス
基本的にはすべて GET メソッドで使用します。
config.py で API_KEY_ENABLED = True とすると、API キーによる認証が使用できます。GETのクエリにAPI Key載せるのセキュリティ的にどうなんだろう。
なお、各エンドポイントは ./tts_app/voice_api/views.py で定義されています。
GET /voice/bert-vits2
このエンドポイントで Bert-VITS2を推論させることができます。クエリパラメータで以下の内容を渡します。
なお、emotion=1を指定しないとエラーになるので注意!
text: 読み上げテキスト (必須)
生成するためのテキストです。id: 話者ID
config.ymlで定義したmodelのSpeaker IDです。0 から始まる、 model_config.model_list 配列の index です。 http://127.0.0.1:23456/voice/speakers エンドポイントでも確認できます。
{"BERT-VITS2":[{"id":0,"lang":["zh","ja","en"],"name":"A"}],"HUBERT-VITS":[],"VITS":[],"W2V2-VITS":[]}format: 出力フォーマット
出力されるオーディオデータのフォーマットを wav, ogg, silk, mp3, flac から選択できます。色々選べて親切設計です。lang: 言語
auto, zh, jaから選択でき、デフォルトはauto(自動検出)です(config.ymlで変更可)。 現時点では複数言語を混在させることはできないようです。length: 音声の長さ
基準は 1 (config.ymlで変更可) で、大きくするほど音声は長くなり読み上げが遅くなります。noise: ランダム度
サンプルノイズの割合。大きくするほどランダム性が高まるらしいです。デフォルトは0.33 (config.ymlで変更可)。なお、Bert-VITS2のデフォルトは0.6でした。noisew: SDPノイズ
Bert-VITS2でいうSDP noise。SDPはStochastic Duration Predictor(確率的持続時間予測)で、各音素がどの程度の時間発音されているかを予測するモジュールに対して、どの程度ノイズを加えるかを指定するようです。ここを大きくするほど、発音の間隔にばらつきが出やすくなるということかと思います。
デフォルトは 0.4 (config.ymlで変更可)、Bert-VITS2のデフォルトは0.8でした。
SDP に関する詳しい解説はこちら→ 【機械学習】VITSでアニメ声へ変換できるボイスチェンジャー&読み上げ器を作った話
segment_size: 分割数
機械翻訳:テキストを句読点に基づいて段落に分割し、長さがsegment_sizeを超える場合はそれらを1つの段落に結合します。 segment_size<=0 の場合、テキストは段落に分割されません。VITSでは、一文が長くなればなるほどイントネーションが不安定になりやすいという特徴があります。これはおそらく句読点で適当に段落分けをしてくれる機能でしょう。なお、出力ではそれらが結合されます。
デフォルトは50でした。
sdp_ratio: SDP/DP混合比
比率が高くなるほど、トーンのばらつきが大きくなるようです。
デフォルトは 0.2 (config.ymlで変更可)。Bert-VITS2でも同一でした。
emotion: 感情
Bert-VITS2 v2.1で使用でき、0~9の範囲で指定できます。
現状の実装だと emotion は必ず real number である必要があり、デフォルトだとエラーになるため、未指定の場合でも必ず emotion=0 をつけてください。(Issue#113)
emotionの0から9の数字はあらかじめ指定された感情スタイルらしい。挙動としては、「emotionを0から9のどれかを指定」か「感情リファレンス音声を指定」のどちらかで、感情音声を入れた場合はそちらが優先、というふるまいらしい。なんかあんまりリファレンスもこれも機能していないっぽく、そのうち改修されるっぽいver 2.2のdevブランチが見えるのでいろいろ変わるかもしれない。
実際にやってみた
VSCode の拡張機能 Thunder Client で気軽に Call してみました。
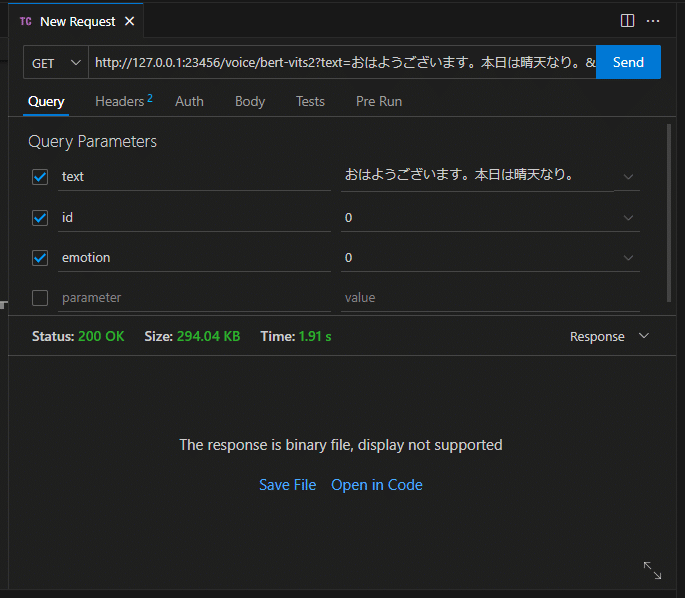
バイナリで返ってきます。これくらいの長さだと wav でも mp3 でもレスポンスは 2 秒くらいでした。
Open in Code をクリックすると VS Code 内で再生できます。
note って音声プレイヤーの埋め込みできないんですね…。
Cloudflared でサクッと公開
ngrok でもいいけど…。
Cloudflared (Cloudflare Tunnels) を利用すると、ローカルサーバーを気軽にインターネットに公開できます。
Cloudflare で管理している独自ドメインをパブリックホストとすることもできます。
もちろんローカルサーバーを立ち上げっぱなしにしないといけないので、Docker でどっかにデプロイしてもいいかもね。
おわりです。
宣伝
Xをフォローしてね: https://twitter.com/_saip_
AI声づくり技術研究会: https://discord.gg/bmNezxjCq2
litaginさんの記事経由で昨日から入りましたが、面白そうです
この記事が気に入ったらサポートをしてみませんか?