
【文系出身初心者】Eコマースデータを統計学的モデルを使って、需要予測してみた。

はじめに
本ブログでは、kaggleの一年分のEコマースのデータセットを使って、需要予測をしたいと思い、統計的モデルで予測してみました。Windows10,Python3.8、kaggleのnotebookを使用しています。
流れ
1.データのインポート
2.データの前処理
3.モデルの構築
4.予測の実行と可視化、データの比較
1.データの読み込み
まずは、kaggleの一年分のeコマースのデータセットをインポートしてみます。
データ元:https://www.kaggle.com/carrie1/ecommerce-data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from os import listdir
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
print(listdir("../input"))['ecommerce-data']
次に、データセットを読み込み、データの先頭5行を出力し、中身を把握しましょう。
data = pd.read_csv("../input/ecommerce-data/data.csv", encoding="ISO-8859-1", dtype={'CustomerID': str})
print(data.shape)
data.head()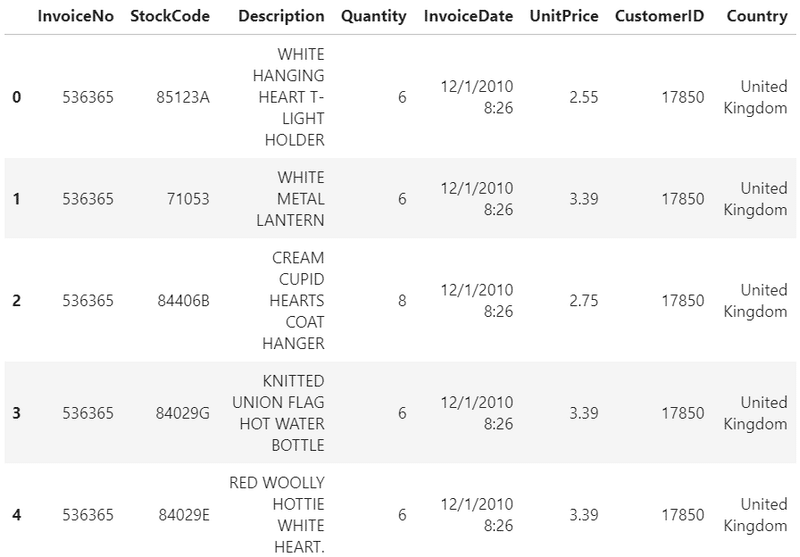
InvoiceNo.:注文番号
StockCode:商品コード
Description:商品説明
Quantity:注文数量
InvoiceDate:注文日時
UnitPrice:単価
CostomerID:お客様ID
Country:地域
このデータファイルの最初の行には、英国のお客様ID 17850の顧客が、注文番号536365の注文をしたことがわかります。さらにこの顧客は、異なる商品を複数一度に注文したことが読み取れます。
2.データの前処理
まずは、欠損値を確認していきます。
missing_percentage = data.isnull().sum() / data.shape[0] * 100
missing_percentage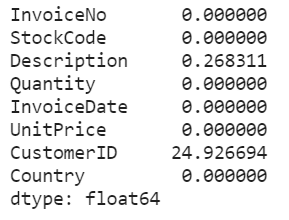
お客様ID(CustomerID)のほぼ25%が欠損しています。 さらに、商品説明(Description)も0.2%欠損していることがわかります。
まずは、商品説明(Description)の欠損値を確認します。
data[data.Description.isnull()].head()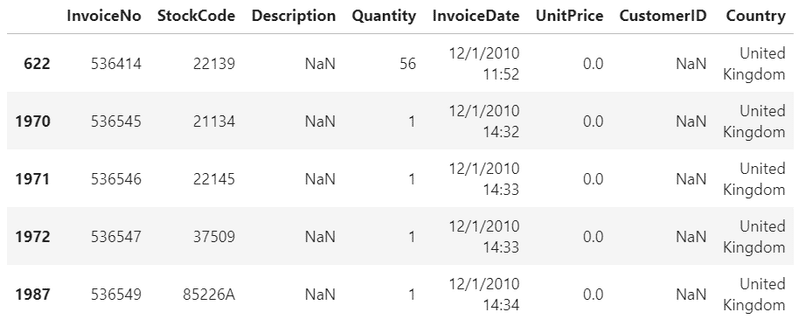
商品説明が欠損しているときは、単価が0.0のため、注文がキャンセルされているようです。
続いて、顧客(CustormerID)が欠損している場合を確認します。
data[data.CustomerID.isnull()].head()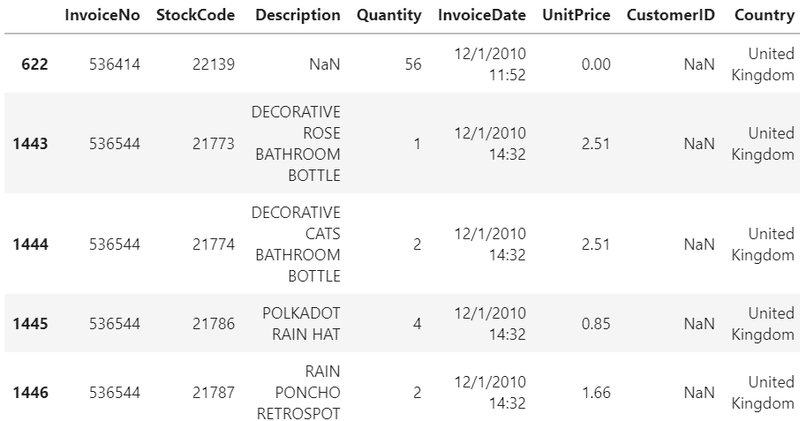
data.loc[data.CustomerID.isnull(), ["UnitPrice", "Quantity"]].describe()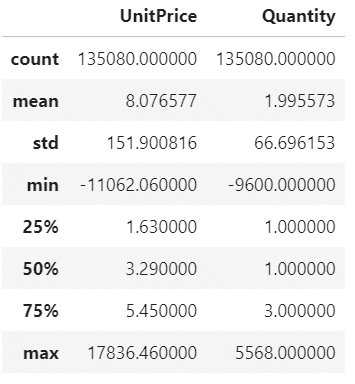
顧客IDのない単価と数量は、極端な値を示しています。
そのため、商品説明と顧客IDのない行も削除することにします。
data = data.loc[(data.CustomerID.isnull()==False) & (data.Description.isnull()==False)].copy()念のため、欠損値がないか確認します。
data.isnull().sum().sum()0
続いて、日付データを追加していきます。
data["Revenue"] = data.Quantity * data.UnitPrice
data["InvoiceDate"] = pd.to_datetime(data.InvoiceDate, cache=True)
data["Year"] = data.InvoiceDate.dt.year
data["Quarter"] = data.InvoiceDate.dt.quarter
data["Month"] = data.InvoiceDate.dt.month
data["Week"] = data.InvoiceDate.dt.week
data["Weekday"] = data.InvoiceDate.dt.weekday
data["Day"] = data.InvoiceDate.dt.day
data["Dayofyear"] = data.InvoiceDate.dt.dayofyear
data["Date"] = pd.to_datetime(data[['Year', 'Month', 'Day']])
data.head()
続いて、日付単位で売り上げを集計していきます。
data_all = data.groupby('Date',as_index=False).sum()
data_all.head()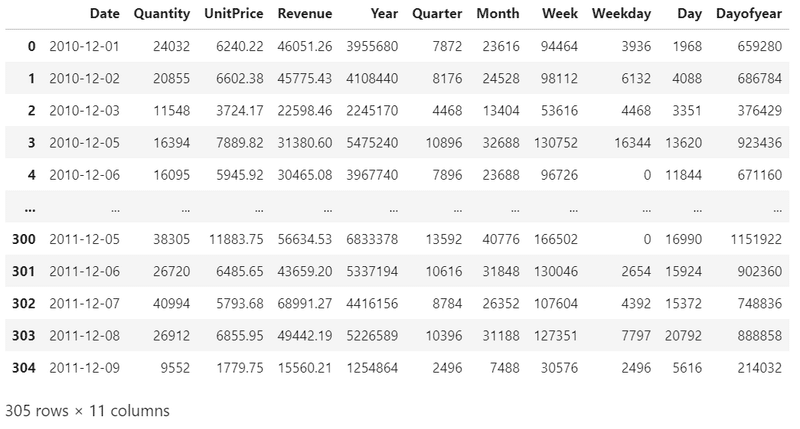
日付で集計すると、このデータは、2010年12月1日から2011年12月9日のデータということがわかりました。
次に、データの推移を見てみましょう。
xlabel = data_all['Date'].to_list()
ylabel = data_all['Revenue'].to_list()
plt.figure(figsize=(15, 8))
plt.plot(xlabel,ylabel,color = "r")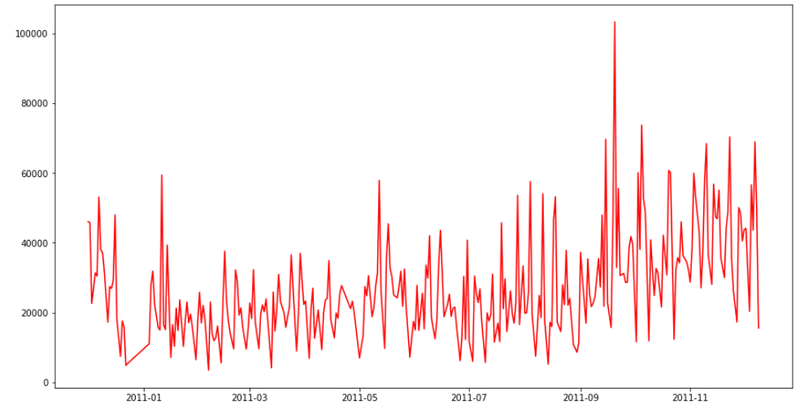
続いて、日付データをインデックスに変換し、日付と売上のデータに加工します。
data_all.index= data_all['Date']
data_all = data_all['Revenue']
data_all = pd.DataFrame(data_all,columns=['Revenue'])
時系列解析では、日付が抜けているとうまく予測ができない可能性があるので、interpolate()メソッドを使い、欠損値を補間します。
date_index = pd.date_range('2010-12-01', '2011-12-09', freq='D')
df_date = pd.DataFrame({"Date" :date_index, "Revenue" : np.nan})
df_date = df_date .set_index('Date', drop=False)
for i in df_date.index:
try :
df_date.loc[i,"Revenue"] = data_copy.loc[i,"Revenue"]
except :
df_date =df_date.drop("Date",axis=1)
data_copy = df_date.interpolate()
data_copy
3.モデルの構築
モデルの構築の前にパラメータの設定に必要なデータの周期を可視化してみます。
fig=plt.figure(figsize=(12, 8))
# 自己相関係数のグラフを出力します
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(data_copy, lags=31, ax=ax1)
plt.show()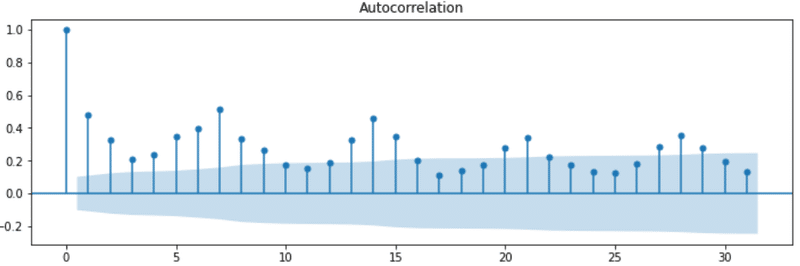
データの周期を確認すると、データの周期が7日ということがわかりました。
このままのデータで予測すると正しい予測ができない可能性があるので、売上を正規化します。
from sklearn import preprocessing
ss = preprocessing.StandardScaler()
data_copy['Revenue'] = ss.fit_transform(data_copy)
data_tsa_day = data_copy続いて、モデルの構築とパラメータを取得します。
# orderの最適化関数
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)
parameters[np.argmin(BICs)]
best_params = selectparameter(data_tsa_day, 7)
best_params[(1, 0, 1), (0, 1, 1, 7), 847.4498883938888]
4.予測の実行と可視化、データの比較
モデルをもとに、予測し、データを比較してみます。
SARIMA_sparkling_sales = sm.tsa.statespace.SARIMAX(data_tsa_day.Revenue,order=best_params[0],seasonal_order =best_params[1],enforce_stationarity=True, enforce_invertibility=True).fit() #predに予測データを代入する
pred = SARIMA_sparkling_sales.predict("2011-09-01", "2012-01-31")
# プロット用にデータをコピー
data_tsa_day_plot = data_tsa_day.copy()
pred_plot = pred.copy()
plt.plot(data_tsa_day_plot)
plt.plot(pred_plot, "r")
plt.show()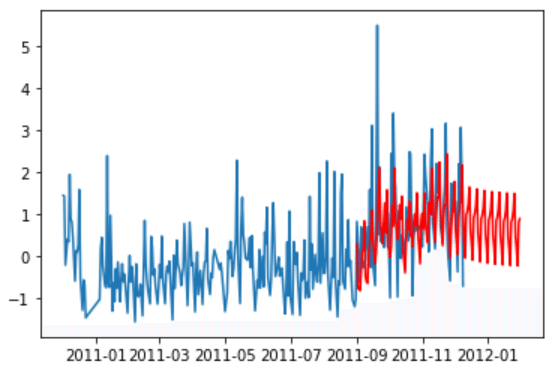
予測の結果を見ると、今回のEコマースデータでは、9月~12月は上昇傾向だが、12月以降は、減少する傾向にあることが予測されました。
ただ、データが一年分のため、季節変動などの定期的周期性が少なく、SARIMAモデルでは、精度の高い予測は難しいという結果でした。
商品や地域の情報を踏まえた予測モデルを作るとさらに精度の高い予測になると思います。
この記事が気に入ったらサポートをしてみませんか?