
[論文解説]報酬勾配を用いたビデオ拡散モデルの適応:Video Diffusion Alignment via Reward Gradients

要点
大規模なビデオデータセットを収集することの困難さを解決するため、報酬モデルを利用して、ビデオ拡散モデルを効率的に適応させる手法「VADER」を提案。
VADERは、報酬モデルからの勾配をビデオ拡散モデルに逆伝播させることで、計算およびサンプル効率を向上させる。
VADERは、テキストとビデオの整合性や美的評価など、さまざまなタスクにおいて既存の手法よりも高い性能を示す。
参照論文
タイトル:Video Diffusion Alignment via Reward Gradients
タイトル(日本語訳):報酬勾配を用いたビデオ拡散モデルの適応
AIによる動画作成技術の最新研究についての論文を見ていきます。
「VADER」という新しい方法が、AIの動画作成能力を大幅に向上させる可能性を秘めているとのことです。
AIによる動画作成の現状と課題
なぜAIによる動画作成が難しいのか
最近のAIは、驚くほどきれいな静止画を作れるようになりました。でも、動画となるとまだまだ発展途上です。なぜでしょうか?
動画は単なる静止画の連続ではありません。時間とともに変化しながら、一貫性を保つ必要があるります。例えば、歩いている人を作る場合、フレームごとに人の姿勢や背景が自然に変化していく必要があります。これが、静止画よりも難しい理由です。
今のAI動画作成の問題点
現在のAI動画作成には、主に以下のような課題があります
大量のデータが必要
高品質な動画を作るには、膨大な量の動画データを学習させる必要があります。
データの質にばらつき
集めた動画データの中には、質の低いものも含まれてしまいます。
特定の内容を作るのが難しい
例えば「赤いドレスを着た女性がダンスをする」といった具体的な内容の動画を作るのは簡単ではありません。
従来の方法とその限界
動画拡散モデルとは?
現在のAI動画作成の主流は「動画拡散モデル」と呼ばれる技術です。これは、ノイズから少しずつ動画を作っていく手法です。
具体的には以下のような流れになります
ランダムなノイズから始める
そのノイズを少しずつ「整形」していく
最終的に望みの動画ができあがる
しかし、この方法にはいくつか問題がありました
たくさんのデータが必要
特定の目的に合わせるのが難しい
作られる動画の質にばらつきがある
報酬モデルの活用
一方、静止画やテキスト作成の分野では、「報酬モデル」を使ってAIの性能を調整する方法が成功を収めています。 報酬モデルとは、AIが作った内容の質や目的との一致度を評価する仕組みです。例えば、「この画像はどれくらい美しいか」「このテキストと画像はどれくらい一致しているか」などを数値化します。 これらの報酬モデルを使ってAIを調整することで、目的に合った高品質な作品を作れるようになります。
VADERの提案
VADERとは?
VADERは、動画拡散モデルを効率よく調整する新しい方法です。この方法の核心は、「報酬モデルからの改善のヒントを直接動画作成AIに伝える」という点にあります。
VADERの仕組み
VADERは以下の手順で動作します。
動画作成AIで動画を作る
作られた動画を報酬モデルで評価する
報酬モデルの評価結果から改善のヒントを計算する
そのヒントを使って動画作成AIを調整する
これを繰り返すことで、AIは効率よく学習を進めることができます。
VADERの利点
VADERには以下のような利点があります。
少ない試行回数で効果的な学習ができる
学習に必要な計算量を減らせる
動画の各フレーム、各ピクセルレベルでの細かい調整ができる
具体例: 「赤いドレスを着た女性がバラを持っている」というテキストに基づいて動画を作る場合、VADERは以下のように動作します。
初めての動画作成:最初はぼんやりした人物とものが映っているかもしれません。
報酬モデルによる評価:「赤いドレス」「女性」「バラ」の存在と、それらの適切な配置を評価します。
改善のヒント計算:各要素をより明確に、適切に配置するための方向性を計算します。
AI調整:計算された方向性に基づいて、動画作成AIを微調整します。
この過程を繰り返すことで、テキストの内容に忠実な高品質な動画が作られていきます。
報酬モデルの種類
VADERでは、さまざまな種類の報酬モデルを使用することができます。各報酬モデルは、動画の異なる側面を評価し、AIの学習を導きます。
画像-テキスト類似性報酬
作られた動画の各フレームが、与えられたテキスト説明とどれだけ一致しているかを評価します。
例:
入力テキスト:「赤いコートを着たアライグマが雪玉を持っている」
評価方法:各フレームにアライグマ、赤いコート、雪玉が適切に描かれているかをチェック
AIの動作:画像内の物体を認識し、テキストの内容と照らし合わせて一致度を数値化します。
動画-テキスト類似性報酬
動画全体としてテキスト説明との整合性を評価します。これにより、動作や時間の流れを考慮した評価が可能になります。
例:
入力テキスト:「人がドーナツを食べている」
評価方法:動画全体を通して、人がドーナツを手に取り、口に運び、噛む一連の動作が適切に表現されているかをチェック
AIの動作:動画全体の動きを解析し、テキストで描写されている行動が適切に表現されているかを評価します。
画像生成目的の報酬
作られた動画の各フレームの品質や特定の特徴を評価します。
例:
美的評価:各フレームの構図、色使い、明暗のバランスなどを数値化
オブジェクト検出:特定の物体(例:犬、車、建物)が適切に描かれているかを確認
AIの動作:事前に学習した「美しい画像」の特徴と比較したり、物体認識技術を使って特定のオブジェクトの存在を確認したりします。
動画生成目的の報酬
動画全体としての一貫性や品質を評価します。
例:
時間的一貫性:フレーム間の動きの滑らかさや物体の連続性を評価
アクション認識:動画全体を通して特定の動作(例:走る、踊る、料理する)が適切に表現されているかを判定
AIの動作:フレーム間の変化を分析し、動きの自然さを評価したり、事前に学習した人間の動作パターンと比較したりします。
これらの報酬モデルを組み合わせることで、目的に応じた多角的な評価とAIの調整が可能になります。
実験結果
VADERの効果を確かめるため、研究チームはさまざまな実験を行いました。ここでは主な実験結果を紹介します。
報酬モデルを用いた動画作成の具体例

上の画像は、VADERを使って作られた動画の例です。左側が従来の方法、右側がVADERで調整したAIの作成結果です。 VADERを使用することで、以下のような改善が見られました。
テキストとの一致度が向上(例:「赤いコートを着たアライグマ」がより明確に表現されている)
動きの表現が自然になっている - 全体的な画質や色彩が向上している
この図は、VADERがテキストの内容をより正確に反映し、動きや画質を向上させる能力を持っていることを示しています。従来の方法では曖昧だった部分が、VADERではより鮮明に表現されています。
効率性の比較
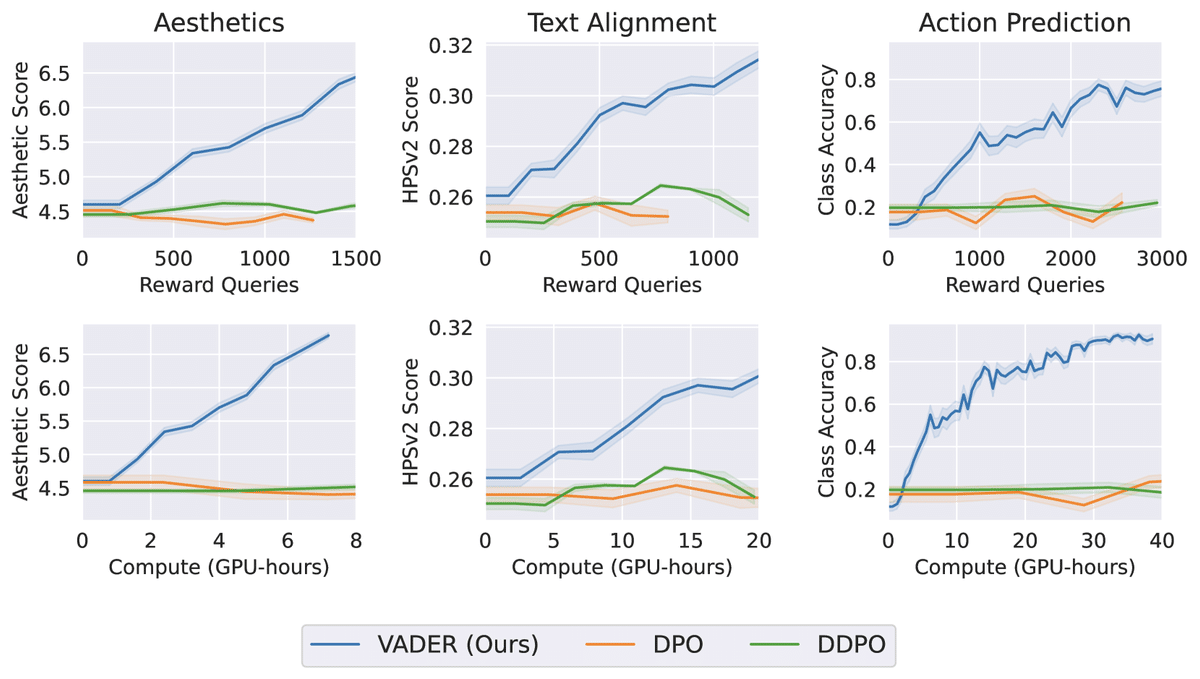
この図は、VADERと他の方法(DPO、DDPO)の効率性を比較したものです。
横軸:学習に使用したサンプル数または計算時間
縦軸:達成された報酬(性能)
VADERの特徴
少ないサンプル数で高い報酬を達成
短い計算時間で効率よく学習を進める
例えば、1000サンプルの学習で、VADERは他の方法の2倍以上の性能を達成しています。これは、VADERがより効率よく学習できることを意味します。
グラフの急な上昇は、VADERが少ない学習データでも急速に性能を向上させられることを示しています。これは、計算資源が限られている環境でも、VADERが効果的に機能する可能性を示唆しています。
AIの応用力と人間による評価
研究チームは、VADERで調整したAIが学習時に見ていないテキストに対してもどれだけ適切な動画を作れるか(応用力)を検証しました。また、作られた動画の品質を人間が評価する実験も行いました。
結果:
学習時に使用していないテキストに対しても、適切な動画を作れることを確認
人間による評価でも、VADERで調整したAIの作成結果が高く評価された
具体例:
「青い空を背景に、黄色い風船を持った子供が走っている」というテキストで動画を作った場合、VADERは以下のような点で高評価を得ました
空の青さと風船の黄色のコントラストが鮮明 - 子供の走る動作が自然で滑らか
背景の細部(例:草、木々)も適切に描写されている これらの実験結果は、VADERが実用的で汎用性の高い方法であることを示しています。
結論と今後の展望
VADERは、報酬モデルからの勾配情報を直接利用することで、ビデオ拡散モデルを効率的に調整する革新的な手法です。本研究の主な成果は以下の通りです。
サンプル効率と計算効率の大幅な向上
さまざまな報酬モデルに対応可能な柔軟なフレームワークの構築
高品質で目的に沿った動画生成の実現
研究の意義
VADERの登場は、AI動画作成技術に大きな進歩をもたらしました。特に以下の点で重要な意義があります
効率的な学習
少ないデータと計算資源で高品質な動画を生成できるようになりました。これにより、AIの動画作成技術の開発と応用がより広く行えるようになります。
柔軟な制御
様々な報酬モデルを組み合わせることで、生成される動画の内容や品質を細かく制御できるようになりました。これにより、特定の目的や要求に合わせた動画作成が可能になります。
技術の汎用性
VADERの手法は、動画生成以外のAI技術にも応用できる可能性があります。例えば、音声合成や3Dモデリングなど、時間的連続性が重要な他の分野にも適用できるかもしれません。
実世界での応用例
VADERの技術は、以下のような分野での応用が期待されます。
エンターテイメント産業
映画やアニメーションの制作において、スタッフの作業を補助し、クリエイティブな過程を加速させることができます。例えば、絵コンテから簡単なアニメーションを自動生成するなど。
教育分野
教育コンテンツの作成を支援し、複雑な概念を視覚的に説明する動画を簡単に作成できるようになります。例えば、歴史上の出来事を再現したり、科学実験のシミュレーションを作成したりすることが可能になります。
マーケティング
商品紹介や広告動画の制作を効率化し、個々の顧客に合わせたパーソナライズされた動画コンテンツを大量に生成することができるようになります。
医療・健康分野
患者教育や治療計画の説明、リハビリテーションの指導などに活用できる動画を、医療従事者が簡単に作成できるようになります。
今後の課題と展望
VADERは画期的な技術ですが、さらなる発展のために以下のような課題に取り組む必要があります:
計算効率のさらなる向上
より長い動画や高解像度の動画を生成するために、計算効率をさらに向上させる必要があります。
多様性の確保
生成される動画の多様性を確保し、同じ入力に対して常に同じ出力にならないようにする工夫が必要です。
倫理的配慮
AIによる動画生成技術の発展に伴い、深フェイクなどの悪用を防ぐための対策や、著作権に関する問題の解決が重要になってきます。
ユーザーインターフェースの改善
技術者でない一般ユーザーでも簡単に利用できるようなインターフェースの開発が求められます。
VADERの登場により、AI動画生成技術は新たな時代を迎えつつあります。今後、この技術がさらに発展し、私たちの生活や仕事をより豊かにする可能性を秘めています。同時に、技術の発展に伴う課題にも真摯に向き合い、AIと人間が協調して創造性を発揮できる未来を築いていくことが重要です。
この記事が気に入ったらサポートをしてみませんか?