
bit vectorで編集距離の計算を高速化する

こちらの記事は、2019年6月17日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
レトリバ製品開発部の@ysk24okです。
本記事ではbit vectorを用いて編集距離の計算を高速化するアルゴリズムを紹介します。論文はこちらです。
クエリの長さをm、検索対象のテキストの長さを$n$としたとき編集距離の計算量は$O(mn)$であることが知られていますが、bit vectorを活用することでword長を$w$とすると計算量を$O\bigl(\frac{m}{w}n\bigr)$($m\leq w$のときは$O(n)$)に低減できる手法になります。
1999年発表の古い論文ですが、この論文で提案されているアルゴリズムが弊社の製品に実装されていて初見では理解できなかったことに加え、日本語での論文解説が無いようだったので解説記事を書くことにしました。
本文中の数式番号は論文中のそれと対応させています。
編集距離(Levenshtein Distance)とは
編集距離とは、2つの文字列が与えられたときにその2つの文字列がどれだけ似ているかを表す距離です。編集距離が小さければ小さいほど似ていて、大きければ大きいほど似ていないということになります。
片方の文字列をもう片方の文字列に一致するよう変形させるために必要な操作の最低適用回数が編集距離として表されます。この操作には置換・挿入・削除の3つあります。例えばwikipediaの記事で使用されている例を使うと、 kittenを sittingに変形させるためには、
kを sに置換
eを iに置換
gを末尾に挿入
の3回の操作が最低でも必要になるため、編集距離は3になります。
近似文字列照合(approximate string matching)における編集距離
先の例では2つの文字列が完全に一致するための編集距離を求めましたが、ある文字列の中から別のある文字列を探索する文字列照合においても編集距離を使用することができます。
近似文字列照合とは、クエリ文字列を$P=p_{1}p_{2}\cdots p_{i} \cdots p_{m}$、テキストを$T=t_{1}t_{2}\cdots t_{j} \cdots t_{n}$として、$T$に対して$P$で検索したときに編集距離が$k$以内でマッチする$T$中の位置$j$を全て求める問題です。
編集距離の計算
編集距離の計算は$(m+1) \times (n+1)$の2次元配列を利用した動的計画法で解けることが知られています。
論文中の例を使い、$P$= match、$T$= remachineとします。
まず、2次元配列の0行目と0列目を以下のように初期化します。

0行目と0列目は空文字を意味します。
2次元配列中の各要素は編集距離の値を表し、$C[i,j]$とおきます。例えば、$C[2,3]$は maと remaの編集距離です。
$C[0,0]$であれば空文字同士の比較なので編集距離は0、$C[1,0]$であれば空文字と mの比較となり $T$に mを挿入するので編集距離は1になります。近似文字列照合では$T$のどの位置からマッチしてもよいため、$C[0,j]$は常に0になります。
編集距離は以下の式で求めることができます。
$$ C[i,j]=\min \bigl\{C[i-1,j-1] + (\mbox{if}\ p_{i}=t_{j}\ \mbox{then}\ 0\ \mbox{else}\ 1), C[i-1,j]+1,C[i,j-1]+1\bigr\} \tag{1} $$
よって、例えば$C[1,1]$を求めるためには$C[0,0]$と$C[0,1]$と$C[1,0]$が必要です。2次元配列を左上から埋めていく流れになるので、計算量は$O(mn)$となります。
全要素を埋めると以下のようになります。

$P$が$T$にマッチするための編集距離を知るには $C[m,j]$を見ればよく、例えば編集距離2以内でマッチするのは$j=5,6,7$の位置であるということがわかります。
提案手法
本論文の提案手法を解説していきます。
まず、提案手法では2次元配列の要素間の差分に注目し、$\Delta h[i,j]=C[i,j]-C[i,j-1], \Delta v[i,j]=C[i,j]-C[i-1,j]$とおきます。
$Score_{j}=C[m,j]$とおくと、
$$ Score_j=Score_{j-1}+\Delta h[m,j] $$
で計算できます。Score0=C[m,0]=mなので、

で2次元配列のm行目の値を全て求めることができます。
従来の動的計画法を用いた解き方だと$Score_{j-1}+\Delta h[m,j]$の計算に$O(m)$かかるため全体では$O(mn)$かかってしまいますが、提案手法ではbit vectorを使って$Score_{j-1}+\Delta h[m,j]$を並列に計算するので$O(1)$(クエリ長mがword長$w$より短い場合)で済み、全体を$O(n)$で計算することができます。
cell structure
まず、$\Delta h[i-1,j],\Delta v[i,j-1],\Delta h[i,j],\Delta v[i,j]$を四辺としたcellに着目します。
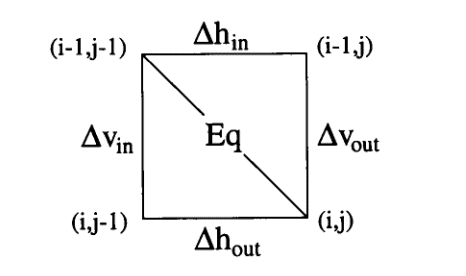
$\Delta h[i,j]$を展開していきます。論文中の式3bと同じですが、式変形をやや丁寧に進めます。 $Eq[i,j]$を$p_{i}=t_{j}$のとき1、そうでないとき0になる変数として、
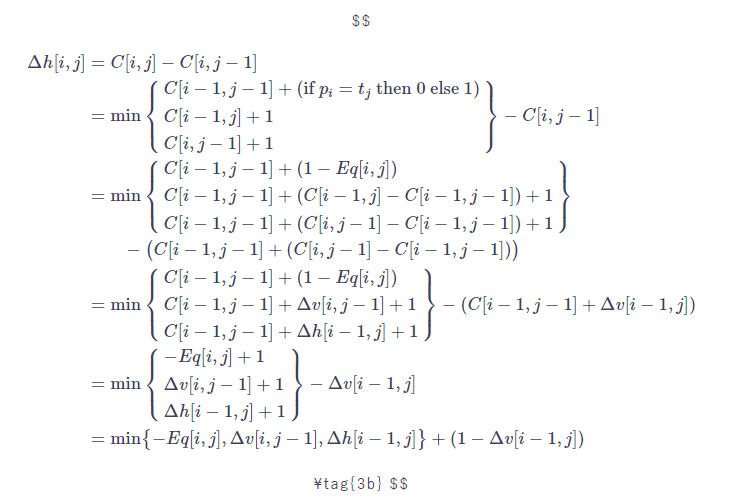
$\Delta v[i,j]$についても同様に展開し、
$$ \Delta v[i,j]=\min \bigl\{-Eq[i,j], \Delta v[i,j-1],\Delta h[i-1,j]\bigr\} + (1 - \Delta h[i-1,j]) \tag{3a} $$
となります。
式3a・3bより、 $\Delta v_{out}=\Delta v[i,j], \Delta h_{out}=\Delta h[i,j]$はともに$\Delta v_{in}=\Delta v[i,j-1], \Delta h_{in}=\Delta h[i-1,j],Eq=Eq[i,j]$に依存していることがわかります。
cell logic
ここで、式3aと3bをビット演算で計算することを考えてみましょう。
式3bをさらに変形させてみます。

$Xh=\min \{Eq, -\Delta h_{in}\}$とおいて、まず$Xh$の値が$Eq$と$\Delta h_{in}$の値によってどう変わるかを表で書いてみます。

上の表より、$Xh$が1になるのは
$Eq$が1のとき
$Eq$が0かつ$\Delta h_{in}$が-1のとき
の2パターンだということがわかります。
Lemma1から$\Delta h[i,j], \Delta v[i,j] \in \{-1,0,1\}$であることが証明されています。しかし3値をとる値をbooleanで表すことはできません。そこで、$Mh,Ph$という2つのboolean変数を用意します。$Ph$は$\Delta h[i,j]$が1の時に1になる変数、$Mh$は$\Delta h[i,j]$が-1の時に1になる変数とします。
$Mh,Ph$を用いて$Xh$をビット演算で表すと
$$ Xh=Eq\ or\ Mh_{in} $$
となります。
次に、式3b'の$\Delta h_{out}$を$Xh$を使って表すと、
$$ \Delta h_{out}=\min \{-Xh,\Delta v_{in}\} + (1 - \Delta v_{in}) \tag{3b''} $$
となり、$\Delta h_{out}$は$Xh$と$\Delta v_{in}$の値に依存することがわかります。
$\Delta h_{out}$が$Xh$と$\Delta v_{in}$の値によってどう変わるかを先ほどと同様に表で書いてみます。

この表より、$\Delta h_{out}$が1になるのは
$\Delta v_{in}$が-1のとき
$\Delta v_{in}$が0かつ$Xh$が0のとき
の2パターン、$\Delta h_{out}$が-1になるのは
$\Delta v_{in}$が1かつ$Xh$が1のとき
の1パターンだとわかります。
$\Delta v$も3値をとる値なので先ほどと同様に$Mv,Pv$の2つのboolean変数を使って、

と表せます。先ほど導出した$Xh$の式もまとめると、
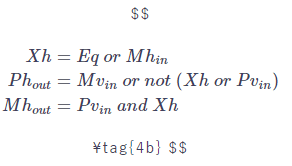
$\Delta v_{out}$についても同様に、
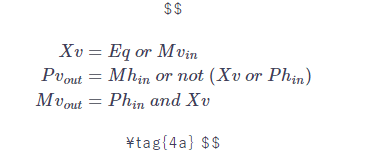
と表せます。これで$\Delta h_{out}$と$\Delta v_{out}$の計算をビット演算化できました。
cell logicの並列化
式4aと式4bを見てみると、$\Delta v_{out}, \Delta h_{out}$のどちらを求めるにも$\Delta v_{in}, \Delta h_{in}$に依存しているため、並列化は難しそうです。
しかし、$\Delta h_{out}$が$\Delta h_{in}$に依存しなくなり、$\Delta v_{in}$のみから求めることができるとしたらどうでしょうか。
$j$列目の各cellにおいて、$\Delta v_{in}$が与えられているとすると$\Delta h_{out}$を求めることができます。このとき、$\Delta h_{out}$は$\Delta h_{in}$に依存しないことから$j$列目の各cell間の依存も存在しないため、各cellの$\Delta h_{out}$の計算は並列におこなうことができます。
$j$列目の各cellにおいて、前ステップで求めた$\Delta h_{out}$をその下のcellの$\Delta h_{in}$として利用すると、$\Delta v_{in}$は既に与えられているため、そのcellの$\Delta v_{out}$を求めることができます。この時も、$j$列目の各cell間に依存は存在しないため、$\Delta v_{out}$の計算も並列におこなうことができます。
2ステップ目が終わった後、$j+1$列目の全cellにおいて$\Delta v_{in}$が与えられている状態なので、1ステップ目から繰り返していくことができます。このようにして、上の2ステップを繰り返していくことでcell logicの並列化ができそうです。
では、どのようにして$\Delta v_{in}$のみから$\Delta h_{out}$を求めることができるのでしょうか。
Eqの計算
前節では触れませんでしたが、$\Delta v_{out}$と$\Delta h_{out}$は$Eq$にも依存しています
次のようなテーブル$Peq$を考えます。
$$ Peq[s](i) \equiv (p_{i}=s) \tag{5} $$
ここで、$Peq$のキーは$T$に含まれる文字種$s$、値は長さm�のbit vectorで、文字$s$に一致する場合対応するbitが1になっています。
$Peq$は先の2ステップとは独立に求めることができます。
同じ列のcell間の依存の排除
bit vector化した$Mh$や$Pv$をそれぞれ$Mh_{j}, Pv_{j}$と表すことにして、式4bの1つ目の式を展開してみます(論文ではLemma2中の式9にあたりますが、式番号が消えている上に、微妙に展開が間違っている気がしており、おそらく下の展開が正しいのではないかと思います)。

となります。この式から、$Xh_{j}(i)$のビットが1になるのは、
$Peq[t_i](j)=1$のとき
$Pv_{j-1}(i-1)=1$かつ$Peq[t_j](i-1)=1$のとき
$Pv_{j-1}(i-1)=1$かつ$Pv_{j-1}(i-2)=1$かつ$Peq[t_j](i-2)=1$のとき
...
のいずれかの条件に合致したときだとわかります。
これらをまとめると、
パターン1: $E(i)=Peq[t_j](i)=1$のとき
パターン2: $E(i)=0$のとき、開区間$[k,i-1](k\leq i)$において$P=Pv_{j-1}=1$、かつ$E(k)=1$
の2パターンにまとめられます。
ここで、論文中の例を取り出してみます。

のとき、$Xh$がどうなるかを考えてみます。
まずパターン1より、$Xh$の11,8,5,1ビット目は1になります。 次にパターン2より、例えば10bit目において、9bit目では$P$が1に、8bit目で$P,E$ともに1なので、$Xh$の8bit目は1になります。6,7ビット目も同様に1になります。よって、$Xh$は

になることがわかります。
これをどのようにビット演算で計算すればよいでしょうか?
まず、$P\And E$と$P$を足し合わせてみます。

パターン2では、$k$ビット目で$P,E$ともに1になるため、$P\And E$が1となる位置が区切りになります。さらに、開区間$[k,i-1]$では$P$は1になるので、$(P \And E)+P$を計算すると繰り上げにより$[k,i-1]$は0になります。しかし、$Xh$では$[k,i-1]$(例えば9,10bit目)は1になるはずです。また、3,4bit目は下位に$P$と$E$ともに1となる箇所が存在しないため0になるはずにも関わらず1になっています。
そこで、$(P \And E)+P$と$P$でXORを取ってみます。

これでパターン2の場合は網羅できました。最後にパターン1も網羅するために$E$とのORを計算します。

これで$Xv$と一致することが確認できました。
よって、
$$ Xh_{j}=(((Peq[t_j]\And Pv_{j-1})+Pv_{j-1})\verb!^!Pv_{j-1})|Peq[t_j] \tag{10} $$
と表すことができ、$\Delta h_{out}$の$\Delta h_{in}$への依存を排除することができました。
比較
通常の編集距離の計算とbit vectorを利用した編集距離の計算で処理時間を比較してみます。
#include <algorithm>#include <cassert>#include <chrono>#include <iostream>#include <string>#include <random>#include <unordered_map>#include <vector> std::vector<int> EditDistance(const std::string& query, const std::string& text, int k) { size_t m = query.size(), n = text.size(); std::vector<int> result; std::vector<int> prev(m + 1, 0); for (size_t i = 0; i < m; i++) { prev[i+1] = prev[i] + 1; } std::vector<int> next(m + 1, 0); for (size_t j = 0; j < n; j++) { for (size_t i = 0; i < m; i++) { if (query[i] == text[j]) { next[i+1] = prev[i]; } else { next[i+1] = std::min({prev[i] + 1, prev[i+1] + 1, next[i] + 1}); } } if (next[m] <= k) { result.push_back(j); } prev.swap(next); } return result;} std::vector<int> EditDistanceBitVector(const std::string& query, const std::string& text, int k) { size_t m = query.size(), n = text.size(); std::vector<int> result; std::unordered_map<char, uint64_t> peq; for (size_t i = 0; i < m; i++) { peq[query[i]] |= uint64_t(1) << i; } uint64_t pv = ~ uint64_t(0); uint64_t mv = 0; int score = m; for (size_t j = 0; j < n; j++) { uint64_t eq = peq.find(text[j]) != peq.end() ? peq[text[j]] : 0; uint64_t xv = eq | mv; uint64_t xh = (((eq & pv) + pv) ^ pv) | eq; uint64_t ph = mv | ~ (xh | pv); uint64_t mh = pv & xh; if ((ph & (1 << (m - 1))) != 0) { score++; } else if ((mh & (1 << (m - 1))) != 0) { score--; } ph <<= 1; mh <<= 1; pv = mh | ~ (xv | ph); mv = ph & xv; if (score <= k) { result.push_back(j); } } return result;} std::string generate_random_string(size_t size) { const char alphabets[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"; std::string s(size, 'A'); std::random_device rng; for (int i = 0; i < size; i++) { s[i] = alphabets[rng() % 26]; } return s;} int main() { std::string query = generate_random_string(64); std::string text = generate_random_string(10000); int k = 2; int exec_count = 1000; std::chrono::system_clock::time_point start, end; double elapsed; std::vector<int> result, result_bit_vector; start = std::chrono::system_clock::now(); for (int i = 0; i < exec_count; i++) { result = EditDistance(query, text, k); } end = std::chrono::system_clock::now(); elapsed = std::chrono::duration_cast<std::chrono::nanoseconds>(end-start).count(); std::cout << elapsed / 1000 / exec_count << " msec" << std::endl; start = std::chrono::system_clock::now(); for (int i = 0; i < exec_count; i++) { result_bit_vector = EditDistanceBitVector(query, text, k); } end = std::chrono::system_clock::now(); elapsed = std::chrono::duration_cast<std::chrono::nanoseconds>(end-start).count(); std::cout << elapsed / 1000 / exec_count << " msec" << std::endl; assert(result == result_bit_vector);}view rawedit_distance.cpp hosted with ❤ by GitHub
通常の編集距離計算を EditDistance()で、bit vectorを利用した編集距離計算を EditDistanceBitVector()でおこなっています。 両関数ともにマッチする$j$の位置をstd::vectorに入れて返しており、それらが一致することを確認するため最後にassertしています。
実行環境
MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports)で、最適化オプションなしでコンパイルしました。
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.14.5
BuildVersion: 18F132
$ g++ --version
Configured with: --prefix=/Library/Developer/CommandLineTools/usr --with-gxx-include-dir=/Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/c++/4.2.1
Apple LLVM version 10.0.1 (clang-1001.0.46.4)
Target: x86_64-apple-darwin18.6.0
Thread model: posix
InstalledDir: /Library/Developer/CommandLineTools/usr/bin結果
テキストとクエリをランダムに生成し、テキストは1000文字固定でクエリの長さを変えた時の処理時間を計測しました。 1000回各関数を実行して平均を取るのを1回のサンプリングとして10回繰り返し(サンプルサイズ=10)、95%信頼区間で処理時間を求めています。

通常の動的計画法ではクエリが長くなるにつれ処理時間も伸びていますが、bit vectorを用いた動的計画法ではほぼ処理時間は変わっていません。そのため、後者の高速化による恩恵はクエリが長いほど大きいと言うことができます。
まとめ
本記事ではbit vectorを用いて編集距離の計算を高速化する手法を紹介しました。論文のChapter3を中心に解説しており、論文と合わせて読み進めていただけると幸いです。不明な点や間違っている点などありましたらtwitterのメンションやDMなどでご連絡ください。