
TopicModelの最終形態? Structured Topic Modelのご紹介

こちらの記事は、2020年2月7日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
こんにちは。レトリバの飯田です。カスタマーサクセス部 研究チームに所属しており、論文調査やそのアルゴリズムを実行するスクリプトの実装などを行なっています。 今回は、Bag of Words(BoW)表現に於いて、これがTopicModelの最終形態ではないか?と私が思っているStructured Topic Modelの紹介と再現実装をpythonで行なったので、その紹介をします。
https://github.com/retrieva/python_stm
Structured Topic Modelとは
Structured Topic Model(STM)は、2013年にMargaret E. Robertsにより提案された手法です(論文)。公式ページが存在し、2018年には、The Society for Political Methodologyと言う学会で、Statistical Software Awardを受賞しています。 この手法の特徴には、以下があります。
文書に付随する属性情報・数値情報を考慮できる
トピックの相関関係を見ることができる
推定結果がロバストである
これは、STMが元にしている手法の性質をそのまま継承しています。STMは、主に以下の手法をベースとしています。
Correlated Topic Model(CTM)
Sparse Additive Generative Model(SAGE)
順を追って説明します。
Correlated Topic Model(CTM)
CTMは、2005年にトピックモデルの推定方法で有名なLDAの著者であるDavid M. Bleiによって提案されています(論文)。日本語におけるトピックモデルの代表的な著書である、トピックモデルによる統計的潜在意味解析やトピックモデル (機械学習プロフェッショナルシリーズ)でも取り上げられています。アルゴリズムについてはこれらを参照してください。このモデルは、トピックに関する分布の事前分布をディリクレ分布ではなく、正規分布とし、正規分布からサンプリングされた値に対してsoftmax関数を適用することによって、トピックに関する分布を多項分布とします。正規分布を推定することになるので、相関を求めることができます。 グラフィカルモデルは以下のようになります。

また、アルゴリズムは以下です。なお、dは文書のindex、nは文書中の単語のindex、kはトピックのindexです。

Sparse Additive Generative Model(SAGE)
SAGEは、文書の属性情報ごとに単語分布を切り替えることを可能にした手法です(論文)。概念図は以下の通りです。

これは、単語の分布の事前分布を共通成分mと各属性情報やトピック固有の成分κに分け、各データ固有の成分は、平均0の正規分布から生成していると考えます。式で書くと以下の通りです。

vは単語種類のindexです。 さらに、この平均0の正規分布の分散の事前分布をラプラス分布にすることによって、メタデータによって切り替える成分をスパース推定します。スパース推定することによって、トピックや各属性情報の成分を少量の単語によって変化させるように誘発できるため、ロバストさが生まれます。アルゴリズムは以下の通りです。
mを非一様分布を用いた表す(多くの場合、対象とする文書の単語頻度)
各トピックkに対して以下を行う
各文書dに対して以下を行う
文書の属性情報を-トピック分布θdからトピックkをサンプルする
単語をwd,nをトピックー単語分布ϕkからサンプルする
STMの更なる特徴
さて、以上の通り、トピックの相関 と 推定がロバスト と言う点についてはCTMとSAGEの特徴でした。STMで提案されているアルゴリズムには加えて以下の特徴があります。
文書-トピック分布の推定に対して文書属性情報を考慮できる(SAGEでは単語-トピックの分布のみ)
文書-トピック分布の推定を積分消去により高速化
この2点を[2]に沿って見ていきたいと思います。また、使われ方についても、合わせてご紹介します。
文書ートピックの分布の推定に対し文書属性情報を考慮できる
STMのグラフィカルモデルは以下の通りです。
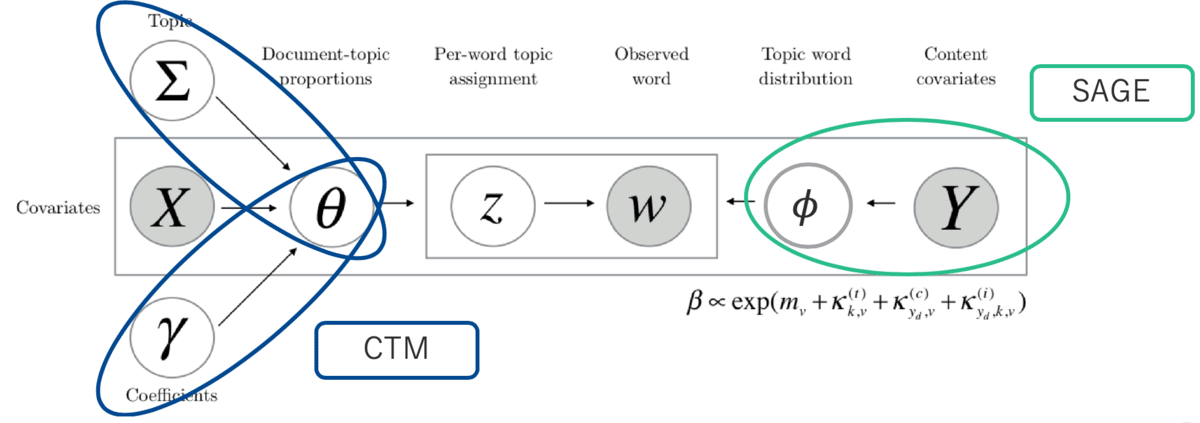
記号は、基本的にこの図に準拠していきます。
グラフィカルモデル上、文書ートピックの分布に対して、Xと記載されたデータが観測された状態で記述されており、文書の属性情報が考慮できることがわかります(黒塗りは観測されていることを表す)。実際は、Xを独立変数とし、各文書でのトピックの正規分布での値を説明変数として回帰することによって、推定値を求めた後、次のステップでその推定値を用いて各文書におけるトピック割合を求めていきます。
それでは、式展開を見ていきます。STMでは変分推論を用いて推定を行なっています。[2]の式(6)より、ELBOが導出されます。

なお、adは文書の属性情報です。(グラフィカルモデル中では、ydとなっています。) グラフィカルモデルおよび仮定した分布に従って、展開すると式(7)になります。
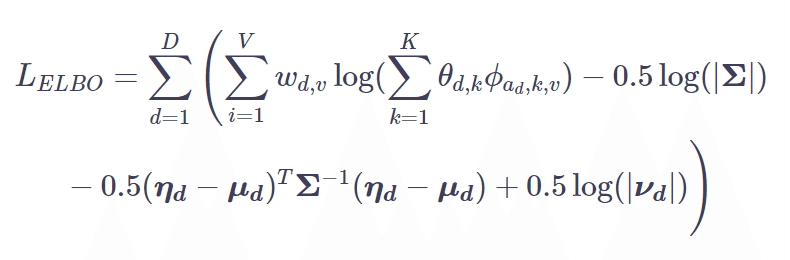
[2]の式(7)で出てくるηに対して、softmax関数を適用すると、θ (文書-トピック分布)になります。そのため、回帰によってηを推定することで、付属情報を考慮します。これは逆に、付属情報の考慮は、回帰係数に現れることを意味しています(バックドアなどは考えないとします。)。また、分散は[2]の式(11)によって更新されます。

※わかりやすさのため、論文とは表記を変えています。正確な表記は論文のものです。
積分消去による高速化
LDAおよびCTMは、通常各単語に対してどのようなトピックが割り当てられているかを推定し、その推定結果を集計して、θやϕ (単語ートピック分布)を算出します。STMでは、これを積分消去によって高速化しています。 これは、論文の式(7)から(8)を導出する過程に出てきます。この詳細は、4にあります。詳しく見ていきます。
まず、[4]の式(5)で、ηが積分消去されています。
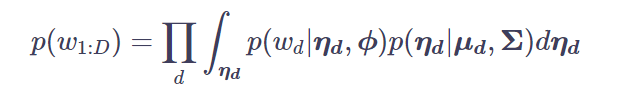
これをイエンセンの不等式を使って変分近似しているのが、[4]の式(6)~(9)になります。ここではp(ηd|μd,Σ)を q(ηd|λd,νd)で近似しています。

以降、λdは、結果ηdとして採用されるため、わかりやすさのため、表記は ηdで行います。(前節もそのようにしており、これが、論文の表記とのずれになります)
[4]の式(9)の各項は、今仮定している分布において、それぞれ式(10)と式(12)になっています。

よって、これらを代入することで、[4]の式(9)は[2]の(7)式になり、ηに関するところを取り出すと、[2]の式(8)となります。
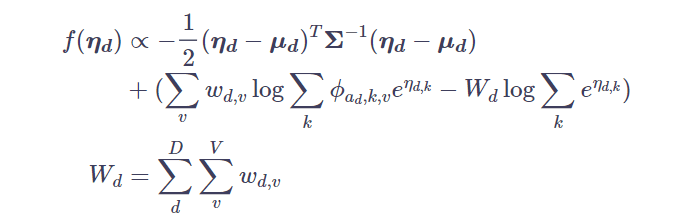
これで、なぜ高速化できるのでしょうか。これは、単語一つずつに対してtopicを推定するのではなく、事前に文書毎に単語をカウントし、出現する単語の項のみを考慮することによって、単語に関するsoftmaxや内積計算を大幅に減らすことができるからです。これによって、高速化を達成しています。
STMの使い方
[2]に沿って、どのような場面で使われているかの例をご紹介します。中国に関する報道について、各メディアによってどのように異なっているのかを分析しています。なお、著者は各トピックの頻度の高い単語とそのトピックの割り当てが大きい記事を読んで、トピックに名前づけをしています。
Covariate(Y)の使い方
[2]のFig6は、中国政府の政策に関するトピックについて、どのメディアかの情報をCovarianceとして付与した場合のトピックの単語の差異です。これを見る限りAgence France Presse (AFP)と the Associated Press (AP)は、Tiananmen(天安門), Zhao(おそらく毛沢東)と行ったような天安門事件を大きく取り上げており、British Broad- casting Corporation (BBC)・Japan Economic Newswire (JEN)・Xinhua (XIN)は、reform, build, advancing, fowardと行った発展を想起させる単語が多く含まれています。

Prevarence(X)の使い方
[2]のFig7では、法輪功弾圧についての分析を行なっています。Fig7の右側は、各メディアでの ηの平均値になります(これは、ダミー変数を使用している場合、回帰係数の値と同じです)。このことから、法輪功弾圧についてもっとも述べているメディアはAPであることがわかります。

STMの実装
以上までで、STMのアルゴリズムの概要・優位性・使用方法について見てきました。以下では、アルゴリズム部分の実装について一部解説します。
1. 変分推論
変分推論を行なっているため、基本的には、VB-EstepとVB-Mstepに分けています。また、属性情報毎にアルゴリズムが変わるため、抽象化を行なっています。以下が該当箇所です。
def inference(self, iter_num):
"""learning once iteration"""
# E-step
# update q_eta and q_z
phi_updater, q_v, variance_topics = self.update_Estep()
# M-step
self.update_mu_and_Gamma()
# update Sigma
if iter_num > 10:
self.update_Sigma(q_v, variance_topics)
# update phi
self.update_phi(phi_updater)
2. VB-Estep
VB-Estepでは、etaの更新とその後に必要なパラメータの計算を行なっています。まず、 [積分消去による高速化]の影響は以下の部分になります。for文中の変数iには、各文書中に出現する単語のidが格納されているので、これとnumpyのfuzzy indexの仕組みを利用し、行列の一部を切り出して計算を行います。
def update_Estep(self):
E_count = np.zeros((len(self.A), self.K, self.V))
q_v = np.zeros((self.K - 1, self.K - 1))
variance_topics = np.zeros((self.K - 1, self.K - 1))
inv_Sigma = np.linalg.inv(self.Sigma)
for m, (_, i, a) in enumerate(zip(self.docs, self.docs_vocab, self.Y)):
# because fuzzy index induces copy
phi_a = self.phi[a, :, i].T
c_dv_d = self.c_dv[m, i]
η自体は、準ニュートン法で更新しています。目的関数と勾配の計算はそれぞれ以下部分です。
def eta_optim_obj(ndoc, K, x, phi, Sigma, mu, c_dv, wd):
"""
ndoc: int
x:K numpy array
phi: KxV numpy array
"""
diff = x[:K-1] - mu[ndoc, :K-1]
x -= x.max()
obj_fn = 0.5 * np.dot(diff.T, np.dot(np.linalg.inv(Sigma), diff))
obj_fn -= np.dot(c_dv, np.log(np.dot(np.exp(x), phi)))
obj_fn += wd[ndoc] * np.log(np.sum(np.exp(x)))
return obj_fn
def eta_optim_grad(ndoc, K, x, phi, Sigma, mu, c_dv, wd):
"""
ndoc: int
x:K numpy array
phi: KxV numpy arrray
"""
diff = x[:K-1] - mu[ndoc, :K-1]
x -= x.max()
q_z = np.exp(x)[:, np.newaxis] * phi
q_z /= np.sum(q_z, axis=0)
theta = np.exp(x) / np.sum(np.exp(x))
grad_fn = -1.0 * np.dot(q_z, c_dv) + wd[ndoc] * theta
grad_fn += np.append(np.dot(Sigma, diff), 0.0)
return grad_fn
3. VB-Mstep
ここでは、μ, Σとϕの更新を行なっています。Σは以下の計算をするのみです。
def update_Sigma(self, q_v, variance_topics):
self.Sigma = (q_v + variance_topics) / len(self.docs)
μについて
Prevarenceがない場合
以下の通り、平均をとります。
def update_mu_and_Gamma(self):
self.mu = np.tile(np.sum(self.eta, axis=0) / self.D, (self.D, 1))
Prevarenceがある場合
以下の通り、回帰を行います。今回、回帰も変分推定で実装しています。
def update_mu_and_Gamma(self):
tmp_Gamma = utils.RVM_regression(self.eta, self.X, self.K)
self.Gamma = tmp_Gamma[:self.D, :self.K-1]
self.mu = np.dot(self.X, self.Gamma)ϕについて
Covariateがない場合
Estepで計算した、各トピックでのカウントの期待値を用いて、以下の通り確率にします。
def update_phi(self, q_z):
# ref: Variational EM Algorithms for Correlated Topic Models / Mohhammad Emtiaz Khan et al
for k in range(self.K):
self.phi[0, k, :] = q_z[0, k, :]
self.phi[0, :, :] = q_z[0] / np.sum(q_z[0, :, :], axis=1)[:, np.newaxis]
Covariateがある場合
SAGEのアルゴリズムを適用します。最適化計算をする前の前処理部分が長いので、目的関数と勾配部分のみ示します。
def kappa_obj(kappa_param, kappa_other, c_k, bigC_k, gaussprec):
p1 = -1 * np.sum(c_k * kappa_param)
demon_kappas = kappa_other * np.exp(kappa_param)
lseout = np.log(np.sum(demon_kappas, axis=1))
p2 = np.sum(bigC_k * lseout)
p3 = 0.5 * np.sum(kappa_param**2 * gaussprec)
return p1 + p2 + p3
def kappa_grad(kappa_param, kappa_other, c_k, bigC_k, gaussprec):
denom_kappas = kappa_other * np.exp(kappa_param)
betaout = denom_kappas / np.sum(denom_kappas, axis=1)[:, np.newaxis]
p2 = np.sum(bigC_k[:, np.newaxis] * betaout, axis=0) # sum up the non focus axis
p3 = kappa_param * gaussprec
return -c_k + p2 + p3
その他
文書ートピック分布と単語ートピック分布はLDAで初期化しています。LDAでの初期化およびその周辺のコードはこちらを使用しています
本家のRの実装では、SAGE部分の実装をポアソン回帰を利用した実装になっています。同様に実装しましたが、発散してしまったため、SAGEの元論文のアルゴリズムで実装しています。
まとめ
Structured Topic Modelは、計量政治学から出てきた手法であるため、あまり知られてはいませんが、BoWでトピックモデルを行うのであれば、もっとも使い勝手の良い手法ではないかと思っています。特に、文書に付与された属性情報と合わせて見ることができるので、既存のアルゴリズムより少ないデータでも、分析に耐えうるものと思われます。 不明な点 ・ 間違っている点 や こんな使い方 ができるなどありましたらtwitterのメンションやDMなどでご連絡ください。
参考文献
※一部リンク切れのものもございます