
逃げ先行予測の結果を精査する。
結果
12月11,12日のレースについて、「逃げ先行」を予測する値を紹介しました。
数字を紹介しっぱなしでは無責任なので、結果と照らして、現状の予測精度を確認しておきます。
僕が公開しているAIは、脚質判定( JRA-VANの脚質判定 ) を予測しています。
「逃げ ・先行」or 「中団・後方・マクリ」のいずれに該当するか、を予測して2つに分類します。
例えば戦歴が少なく、逃げ読みは難しい2歳戦ながら、指数最上位のダークペイジが「逃げ」たりと、なかなか使えるなと思わせます。

あるいはカペラSは読みやすい構成だったとはいえ、指数上位がキチッと先行しています。

以下の表は、Pythonで用意されている分類のレポートです。

赤丸部分が精度と呼ばれるもので、結果は72%でした。(2歳線は除く)
これは今の先行予測AIで事前に分かっている精度と同じです。
つまり、「逃げ ・先行」or 「中団・後方・マクリ」の予測の2択が、72%当たっているということです。
次に混同行列で、中身をチェックします。

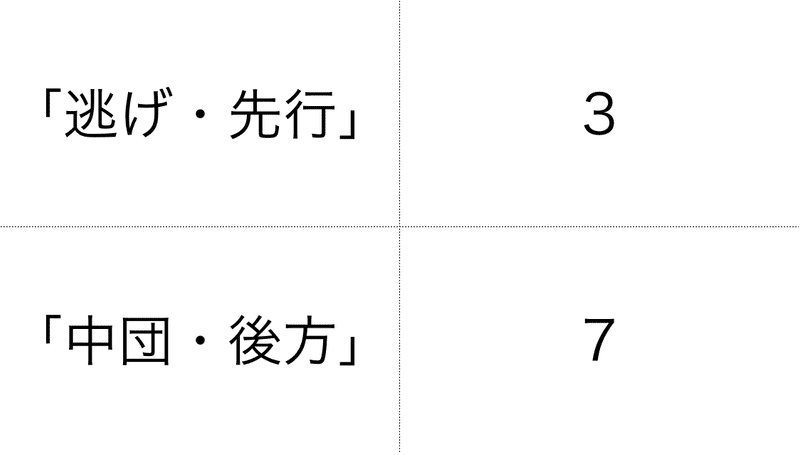
そもそもデータにおける、脚質の割合としては以下のように、先行しない馬が7割を占めるので、先行しないと予測することで、たいていは当たる問題です。
「とりこぼし」と「とりちがい」
先行馬をとりこぼす(偽陰性)VS 先行馬をとりちがえる(偽陽性)

もちろん、偽陽性も偽陰性もいずれも減らすことが最優先です。
ただ、細かなチューニングで偽陽性と偽陰性のバランスを調整できます。
つまり、2つはトレードオフな関係にあります。
どちらを優先するかは、AIを使う目的によって変わります。
・ガンの有無を見つけるシーンでは、「とりこぼし」は重大な欠陥となります。
・他方で、迷惑メールをスパムとしてはじきたいシーンでは、「とりこぼし」よりも「とりちがい」が問題になります。重要なメールがスパムとして排除されては困りますよね。
何を目標とすべきか?
翻って、競馬の先行馬を予測するシーンでは?
先行馬を見落とすコトと誤って先行馬を予測するコトの、どちらの間違いを減らしたいでしょうか?

競馬の展開予測ですから、どちらのミスも重大なミスではありません。
ただ、個人的には先行馬を見落とすことの方がリスキーだと思います。
現状、思わぬ先行馬によって展開・ペースが想定外になってしまうと、予想の前提が壊れますから。
なので、そもそも脚質を2つの値に分類していることに若干の問題も感じるので、いつも紹介する数値としては、以下のように先行確率という形で紹介しています。
これは、機械学習で「先行」or 「後方」に分類させる際に、使われる確率です。
現状はこれが50%を超えれば、「逃げ・先行」と判定しています。
ただ、この確率が高い方が、より前方にいることが多いなと体感します。
個人的には隊列の予測と、ペースの予測、これら2つの予測のベースとして、先行馬を予測したいと思っています。
なので、先行確率という形で表示する方が、実用性があります。
こうなると、「とりこぼし」と「とりちがい」の話はいったんスルーできます。
何の話?
まとまりのない書き方になりましたが、ひとまず言えることをまとめます。
・吉田しげるの機械学習の精度に、改善の余地が大いにあること
・分類の精度を測るのは、簡単ではない
・何のために予測するのかを常に意識することが大事
・実感として、展開予測が大きくズレない
・ゆえに、予測がラクになった
先行馬予測AIの内容と使うメリットは、動画で話しているのでご参考ください。
この記事が気に入ったらサポートをしてみませんか?