
手書き化学構造認識モデルDECIMER V2を解説&動かしてみた

PDFの中に埋もれている化学構造をSMILESなどのコンピュータが扱える形にしたいと思ったことはありますか?
最近だと化学構造を手書きで描いた画像をChatGPTでSMILESに変換させてみようとしましたが、うまくいきませんでした。
ベンゼンぐらいだったらうまくいくSMILESに変換してくれますが、カフェインぐらいになると無理です。
そこで見つけたのが、手書き化学構造認識モデルであるDECIMER(Deep lEarning for Chemical IMagE Recognition)です。
DECIMER は手書きの化学構造をうまいことSMILESに変換してくれるのですよ。イメージは以下ですね。
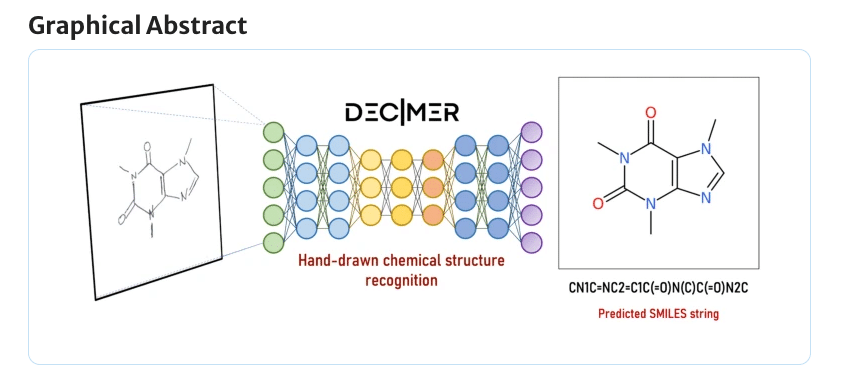
そんなDECIMERの新モデルであるDECIMER V2が出たとのことで、今回は手書き化学構造認識モデルであるDECIMER (Deep lEarning for Chemical IMagE Recognition)が手書きの化学式をSMILESに変換する仕組みと動作を解説していきます。
以下が大元になる論文ですので一度読んでみてください。
前提
このブログは前提としてある程度DeepLearningのCNNぐらいまでの知識があることを前提に書いています。
DECIMERの仕組みの解説
全体像
DECIMERの仕組みをざっくり言うと
EfficientNetで手書き画像をベクトル化して、それ入力としてTransformerで文字列SMILESに変換するDeepLearningモデルです。
ほんとこれが全てです。Transformerの恩恵を受けてめちゃくちゃ精度が上がったモデルの一つですね。以下のモデルの図でほとんど解説終わりなのです。
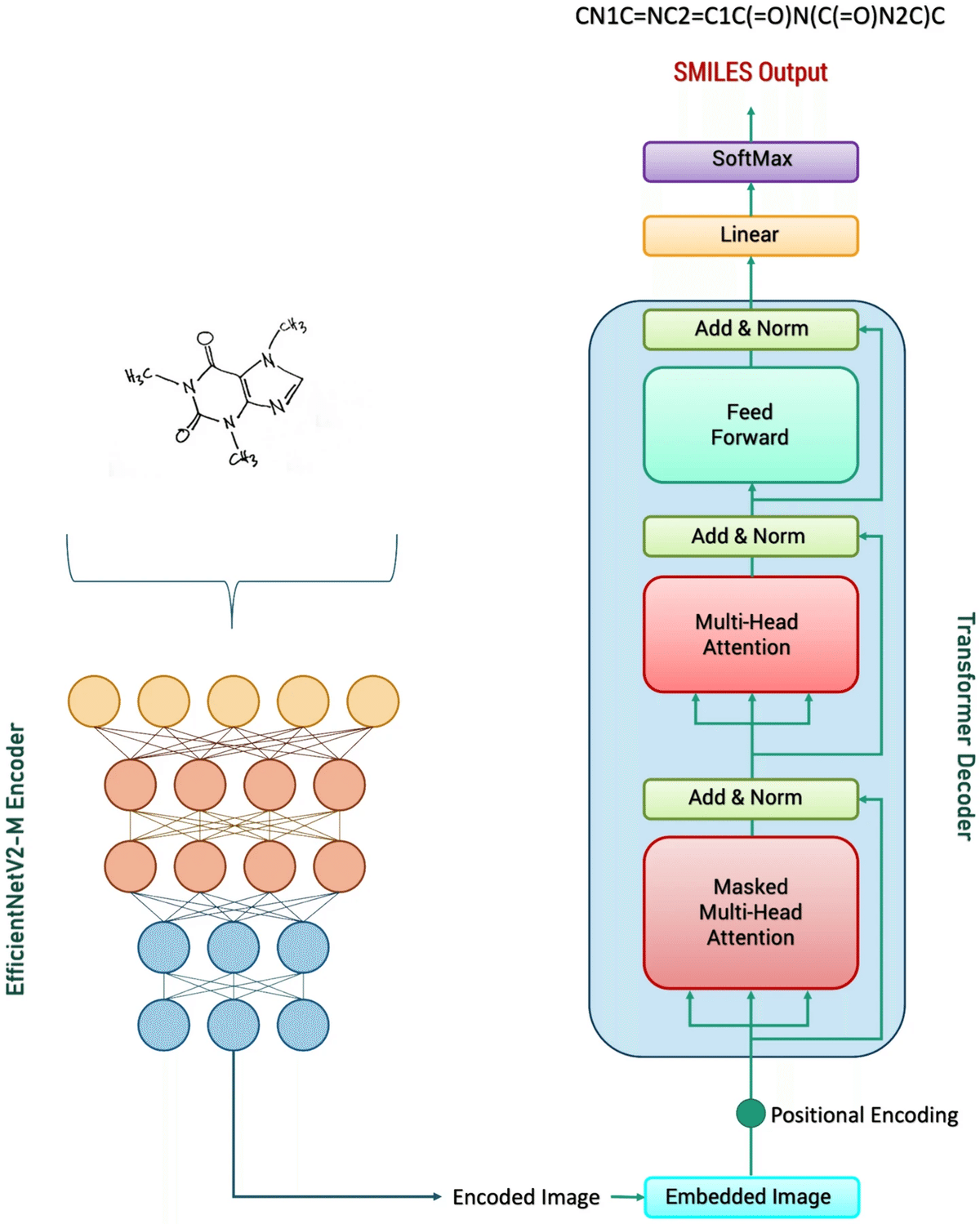
ただこれだけだとDECIMERへの納得感が足りないと思います。その要因は主にEfficientNetとTransformerについてイマイチわからないことが原因だと思います。
EfficientNetとTransformerについて説明を書いていくことでDECIMERに関しても流れをざっくり理解できるようにしていきましょう。
前提にもある通りディープラーニングをCNNぐらいまでわかってる人がなんとなく理解できるように書いていきたいと思います。
EfficientNet部分
EfficientNetは、Googleの研究者によって2019年に提案された畳み込みニューラルネットワーク(CNN)アーキテクチャで、当時高い精度を維持しながら計算効率と学習効率を大幅に向上させることができたモデルとして有名です。
2019年なので比較的最近のアーキテクチャですね。
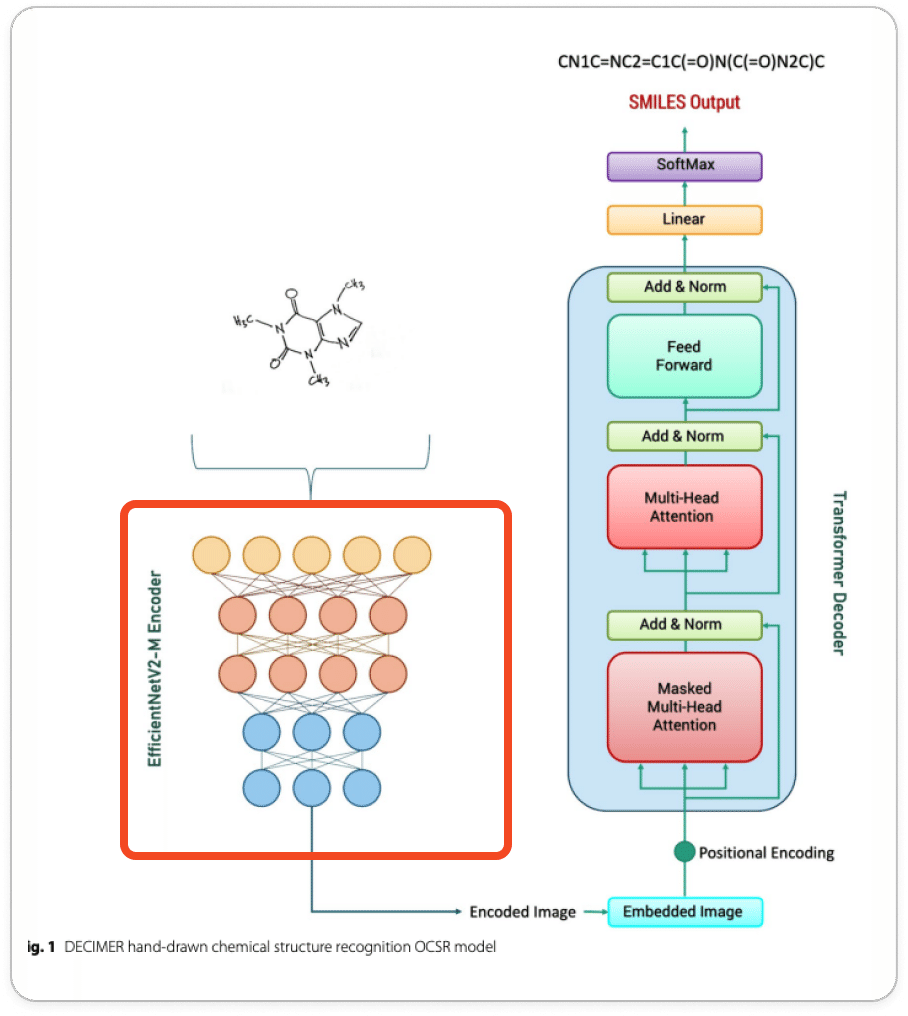
一般的なCNNと比べて何が違うかを知ることがEfficientNetざっくり理解するためには重要です。
ざっくり言うと、EfficientNetはCNNアーキテクチャでスケールあげる時にいじることのできるパラメータ「Resolution (解像度)」「Width」「Depth」の3つをバランスよく調整したやつです
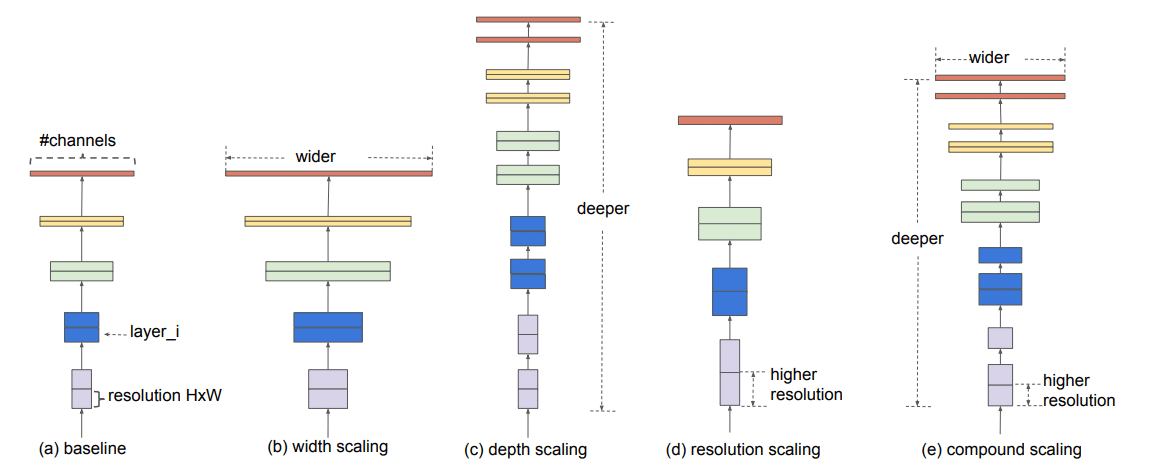
そのおかげでパラメータも少なくなり学習効率がいい!その割に精度が高い。(2019時点ではEfficientNetV1がSoTA(最高精度))というのが肝でした。
つまりEfficientNetはいい感じのCNNなんですね。
以下がEfficientNetのV2-Sモデルのアーキテクチャです。
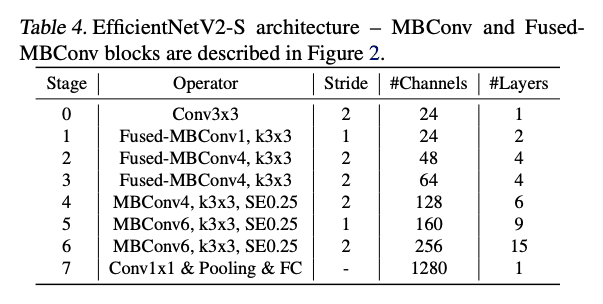
DECIMERではEfficientNetV2-Mモデルの最後の全結合層(FC)だけ取り除いて使用しています(※上記の表はSモデルなので注意)。
全結合層だけ取り除いているのは手書き文字画像のベクトル表現を取り出すためです。
ここまでをまとめると「つまりDECIMERではEfficientNetを使って手書き文字画像のベクトル表現をいい感じに取り出す」のです。
Transformer部分
次にDECIMERのTransformer部分の説明です。
DECIMER V2では使用しているTransformerはデコーダーモデルを採用しています。
DECIMER V1ではエンコーダーデコーダーモデルだったのですが、デコーダーのみにした方が精度が上がったようです。
では実際にTransformerのデコーダーの説明ですが、詳しい解説は他に任せてここでは理解した気になるように、入力から出力までの流れを説明をしていこうと思います。
※ コードを確認した感じ、若干元の図だと入力出力がわかりにくかったので別で入力関係がわかるように線を引いています。
まずは入力
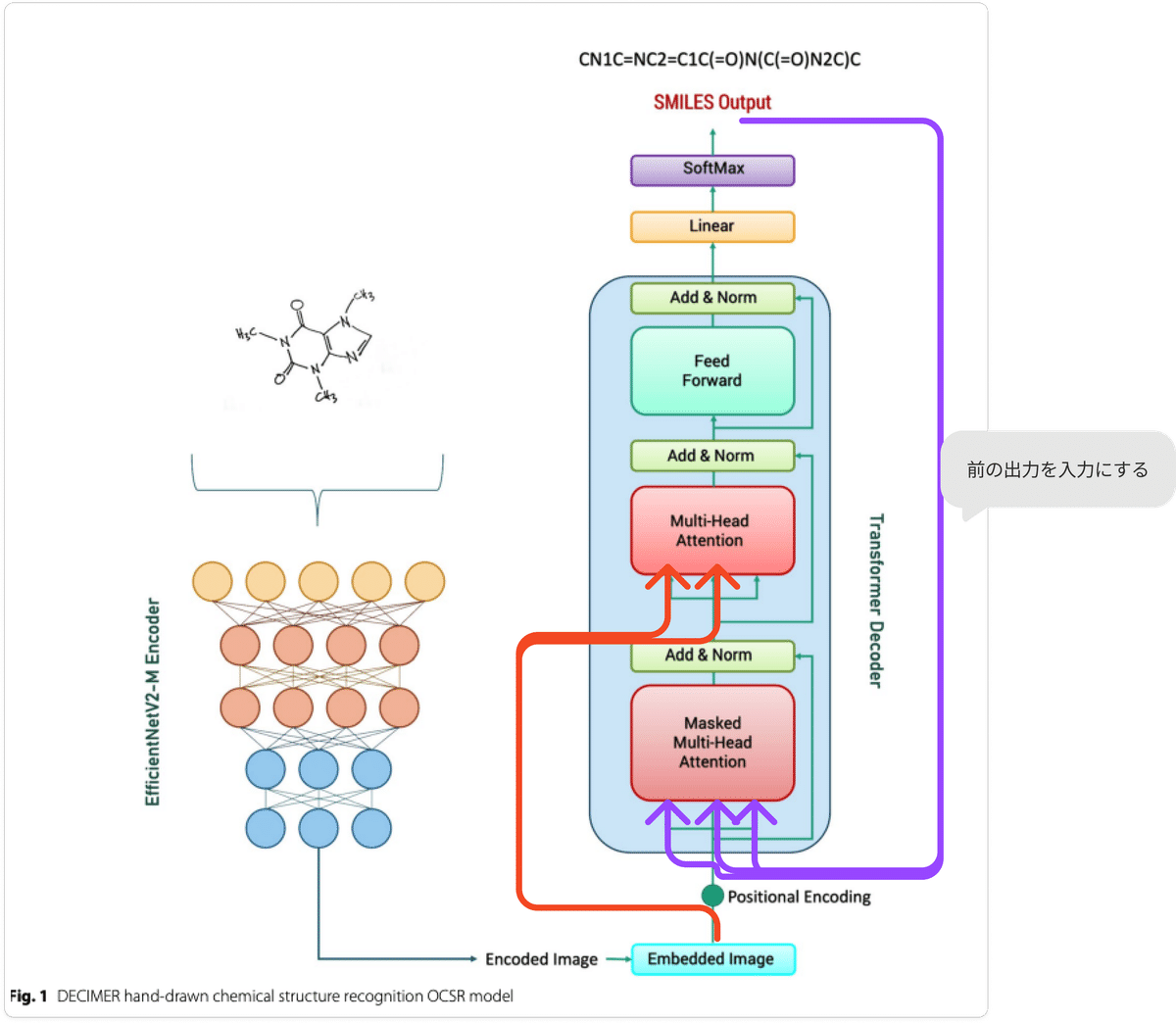
EfficientNetで化学構造の画像をベクトル表現に変換にしたものをと生成した前の文字列を入力として使います
Masked Multi-Head Attention

前の出力文字列をベクトル化したものをこの層へ入力します。紫矢印ですね。
生成中のSMILES文字列内の関係性を計算して、次の予測のためSMILES文字列内のコンテキストをここでは出力する。
Multi-Head Attention

入力がEfficinentNetの出力である化学構造画像のベクトル表現+Masked Multi-Head Attentionの出力です。
ベクトル化した化学構造画像のベクトル表現全体に注目し、どの部分がSMILES文字列の生成の関係性を計算します。
次の予測のために必要な化学構造画像とSMILES文字列内のコンテキストをここでは出力する。
フィードフォワードネットワーク(Feed Forward)+ Softmax

ここではMulti-Head Attentionの出力を受け取り、次のSMILESの文字列が何かの確率を計算します。
出力
次の文字列を選択し、入力に戻ります。このプロセスを繰り返し、SMILES文字列を一文字ずつ生成していきます。特別な終了文字が生成されるまで、または最大長に達するまで続けます。
Transformerのモジュールが実行していることをまとめると
EfficientNetで処理した化学構造画像と生成中のSMILES文字列を入力としてSMILESを作成するです。
DECIMERの動きまとめ
つまりDECIMERはEfficientNetで手書き画像をいい感じのCNNでベクトル化して、それ入力としてTransformerで文字列SMILESを出力させるDeepLearningモデルです。最初にも言った通りなのですが、順を追うと納得感が出たと思います。
細かいモデルの違いで結構精度が違う
Transformerにも EffecientNetにもモデルのバージョンが付いていたりしてそれぞれアーキテクチャに違いがあります。
論文中では、以下の組みで精度比較していました。
Transformer エンコーダーデコーダー+ EffecientNetV2
Transformerデコーダー+ EffecientNetV1
Transformerデコーダー+ EffecientNetV2

基本Transformerデコーダー+ EffecientNetV2の組み合わせが精度良かったみたいですね。Transformerデコーダー+ EffecientNetV1もそこそこ良くなってるのでTransformerはデコーダーモデル使ってた方が良さそうだとも論文中では言っていました。

動かしてみた
Colabで動かしてみる。
では実際に動かしてみましょう。
動作環境はGoogleColabです。動かす時は必ずGPUかTPUを使いましょう。
DECIMERのリポジトリは以下です。
まずはDECIMERをColab上でimportできるようにします。
!pip install git+https://github.com/Kohulan/DECIMER-Image_Transformer.git次に画像(化学構造)をアップロードし、それをDECIMERに渡すことでSMILESを予測させるコードです。
# 必要なライブラリのインポート
from google.colab import files
from DECIMER import predict_SMILES
import os
# 画像のアップロード
uploaded = files.upload()
# アップロードされた画像のパスを取得
image_path = next(iter(uploaded))
# SMILES予測の実行
SMILES = predict_SMILES(image_path)
print(f"Predicted SMILES: {SMILES}")
os.remove(image_path)これで全部です。簡単ですね。実際に動かしてみましょう
画像は以下にベンチマーク用の画像があるのそれでやってみましょう!
1枚目
まず一つ目
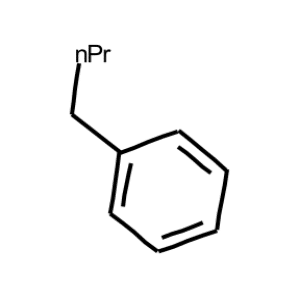
Saving DECIMER_test_1.png to DECIMER_test_1.png
Predicted SMILES: CCCCC1=CC=CC=C1答え:
CCCCC1=CC=CC=C1正解ですね!いい感じです
2枚目
では二枚目です。
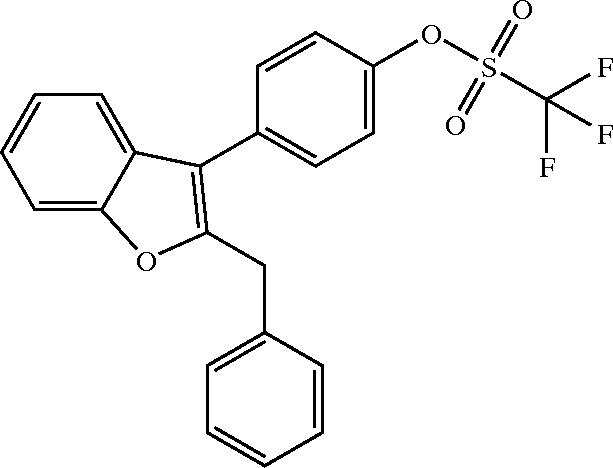
Saving DECIMER_test_0.png to DECIMER_test_0.png
Predicted SMILES:
C1=CC=C(C=C1)CC2=C(C3=CC=C(C=C3)OS(=O)(=O)C(F)(F)F)C4=CC=CC=C4O2答えは
C1=CC=C(C=C1)CC2=C(C3=CC=C(C=C3)OS(=O)(=O)C(F)(F)F)C4=C(C=CC=C4)O2微妙に違う?MolViewで可視化して比較してみましょう。
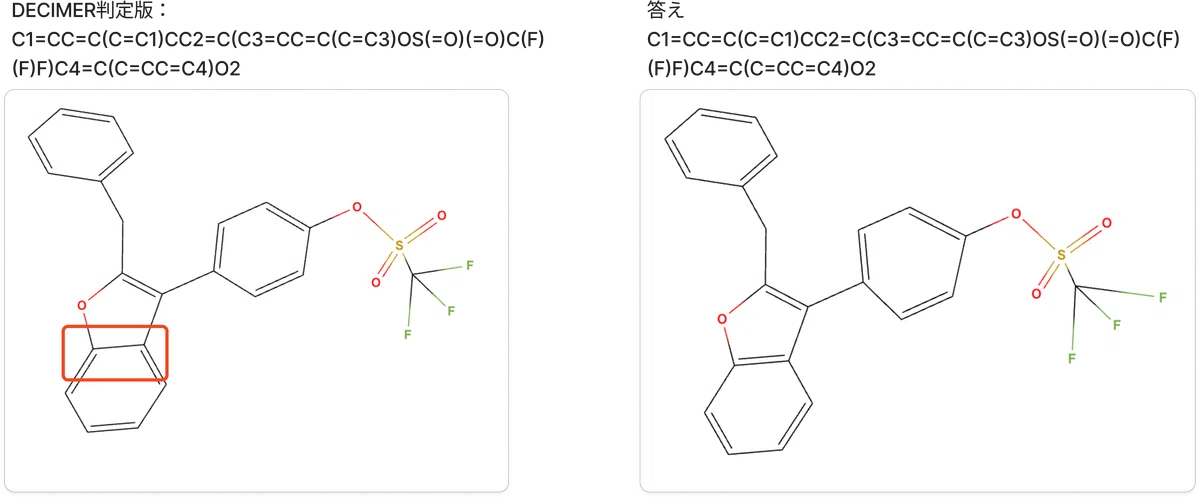
左側のDECIMER判定したものはベンゼン環内の結合位置が違いますがSMILES的には一緒っぽいですね。
でもここまで大きくてもSMILESへの変換ができるのはすごいですね。
弊社の化学人員にDECIMERを見せコメントをいただきました。
スマホでもできるようになれば「あの構造どんなのだっけ?」や「どこにメモしたかなあ」という場面が減りそうです。複雑な立体構造や、急いで書いた雑な構造でも読み取ってくれると更に捗りそう!検証してみて欲しいです。
いい感じですね。
他に比べると精度は?
肝心の他の手書き認識モデルとの比較です。他のモデルに比べても精度出てますね。

実際に使ってみた感じもかなり精度良さそうです。すごくいいですねこれ。
最後に
実はQunaSys内でDECIMERをセルフホスティングして使えるようにしています。結構精度良くて感動していたのですが、さらにV2が出たので記事にしてみました。
LLM✖︎化学領域でお困りのことがある方がいましたらお気軽に下記までお問い合わせください!