
XBRLを読み込んで財務三表コピペの数値ミスを軽減する(Python)

大学の課題などで上場企業の財務を分析する際、財務数値を表計算ツールに書き写す作業があると思いますが、一番厄介なのが数字の書き写しミスです。
この道のプロフェッショナルは有料のデータベースを利用することが多いようですが、私のような大学生にはそんな高価なものに手が出ません。一方で毎年度の有価証券報告書から財務数値を書き写すのも一苦労です。
そこで、Pythonを使って有価証券報告書などの財務報告文書を一定のデータ形式に標準化している「XBRL」データを読み込んで、毎年の財務数値をCSVファイルに出力するプログラムを作ろうと思います。
CSVに出力するまでの流れ
今回のプログラムは予め対象企業のXBRLを一括でダウンロードしておくことを想定しています。EDINETを使えば過去5年分の有価証券報告書XBRLをダウンロードすることが可能です。
取り込んだXBRLを1つのフォルダにまとめ、Pythonで各年のXBRLを探し出し、1年ごとの財務数値をデータフレーム化、最後にCSV形式に書き出します。
要約すれば、Pythonのコードで実行するのは:
毎年のXBRLファイルを探す→財務情報を抜き出す→整理→CSVへ出力
の手順になります。
使用するPythonライブラリ
今回主に利用するライブラリはArelleです。これまでに多くのPythonツールを利用してきましたが、一番初心者にもやさしいのがこのArelleだと思います。
Arelleには複数のバージョンがあるようですが、今回はこちらのサイトを参考にインストールしました。↓
また、Arelleの使い方、コードの書き方はこちらのサイトを参考にしています↓
前提
今回は家電量販店とリフォーム事業を展開するヤマダホールディングス(証券コード:9831)の財務数値を抜き出すことにします。
過去5年間の有価証券報告書をEDINETからダウンロードし、ZIPファイル直下のフォルダ(アルファベットのSから始まるフォルダ)を このプロジェクト用のファイルに展開します。
ファイル階層は以下を想定しています:
root
┗ project.py
┗ 9831
┗ S100AP63
┗ S100DHCA
┗ S100G3R1
┗ S100J0ZP
┗ S100LU4W
┗ 9831_fin_data.csv ☚書き出したCSVファイルコード例
## project.py
from arelle import Cntlr
import pandas as pd
from arelle import Cntlr
import glob
####xbrlを特定する
xbrl_file_dirs = list()
for xbrl_file_dir in glob.glob('./9831/**/XBRL/PublicDoc/*.xbrl'):
xbrl_file_dirs.append(xbrl_file_dir)
for xbrl_file in xbrl_file_dirs:
ctrl = Cntlr.Cntlr(logFileName='logToPrint')
model_xbrl = ctrl.modelManager.load(xbrl_file)
fact_datas = list()
for fact in model_xbrl.facts:
if fact.unit is not None and str(fact.unit.value) == 'JPY':
label_ja = fact.concept.label(preferredLabel=None, lang='ja', linkroleHint=None)
x_value = fact.xValue
if fact.context.startDatetime:
start_date = fact.context.startDatetime
else:
start_date = None
if fact.context.endDatetime:
end_date = fact.context.endDatetime
else:
end_date = None
fact_datas.append([
label_ja,
x_value,
start_date,
end_date,
fact.contextID,
])
else:
continue
df = pd.DataFrame(fact_datas,
columns=['勘定科目', '金額', '期首', '期末', 'contextID',] )
df_d = df[df['contextID'] == 'CurrentYearDuration']
df_i = df[df['contextID'] == 'CurrentYearInstant']
df_m = pd.concat([df_d, df_i])
df_m.to_csv("./9831/9831_fin_data.csv", mode = 'a', encoding='cp932', errors='ignore', index = False)実行結果
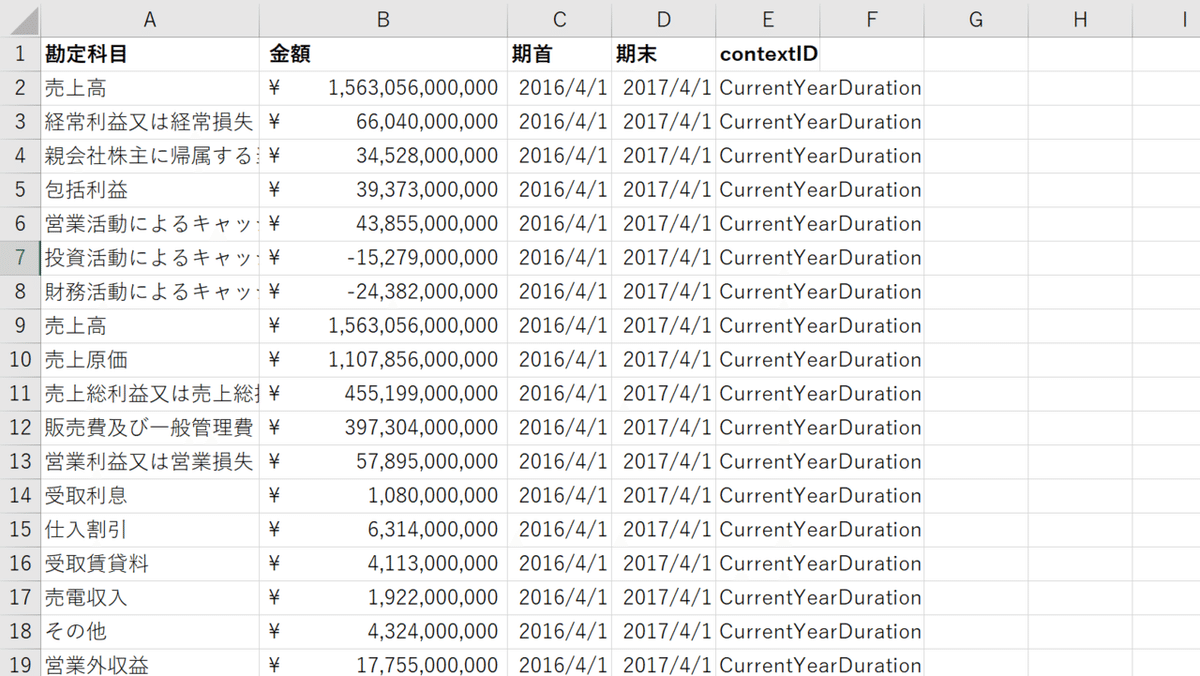
会計数値が多きく指数表記になるため、書式を変更するなどして見やすくしました。
結局、ここから先は年度ごとに手動で勘定科目を調整した横持ちのデータに編集することになりますが、これだけでかなりの数値ミス削減・時短に繋がると思います。
気を付けないといけない点
財務3表以外の数値(有価証券報告書の冒頭に登場する経営指標など)も拾ってしまうので注意が必要ですが、財務諸表の科目の並び方からある程度どこからがBS、PL、CFなのかが推察できるので(順番は狂っていないので)大丈夫だと思います。
この記事が気に入ったらサポートをしてみませんか?