
関数で簡単webスクレイピング

IMPORTHTML関数
こんにちは。
突然ですが皆さんはwebスクレイピングってご存知でしょうか?
Wikipediaで調べてみると、「ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。」と書かれています。
なにやらとっても難しそうですね🤔
実際普通にスクレイピングするのであればプログラミングの知識が必要でプログラミングを学んでいない方にとってはかなりハードルが高いです。
ですがGoogleSpreadsheetを使うとプログラミングの知識がなくても誰でも簡単にwebサイト上の文章や表、リストなどを抽出することが出来ます。
(HTMLで書かれているサイトに限ります)
今回は一例として IMPORTHTML関数 というGoogleSpreadsheet独自の関数を使ってMリーグ公式サイトから「2021-22 チーム成績表」を抽出してみたいと思います。
※操作はWindow10によるものとなります。
まずはGoogleSpreadsheetを立ち上げ新しいシートを開きます。
作業しやすいようにウィンドウを2つ並べ、片方にスプレッドシート、もう片方にMリーグ公式サイトの成績表ページを表示させておきました。

ではこのMリーグの成績表ページから赤坂ドリブンズの成績表をスクレイピングしたいと思います。

まずスプレッドシートの成績表を抽出したいセルに「=IMPORTHTML(""」と入力します。

次に成績表ページのURLをコピー。

先程入力したスプレッドシートの数式の「""」ダブルクオーテーションの間に貼り付けます。

カーソルを末尾に移動させ、続けて「,"table",1」と入力してみます。

IMPORTHTML関数はtable(表)またはlist(リスト)を抽出する関数のため、第2引数にはどちらかを「""」で囲って指定します。
第3引数である「1」はそのtableまたはlistが対象ページの何番目にあるかを指定しています。
成績表ページを見てみると、赤坂ドリブンズの表は一番上にありそうなので「1」と入力してみました。
ではこれでEnterキーを押してみましょう。

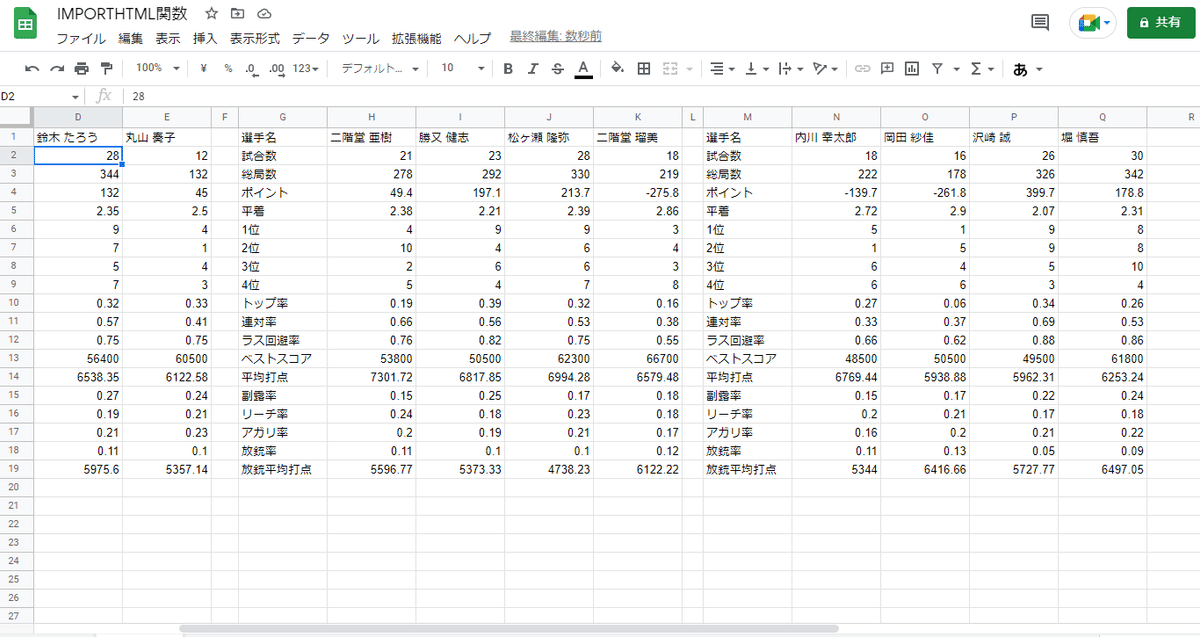
はい、抽出できました。とっても簡単ですね。
ちなみに数式の第3引数である数字を2や3に変えると、ページ内の2、3番目の表のEX風林火山、KADOKAWAサクラナイツの成績表が抽出されます。
もちろんこれは対象ページが更新されればスプレッドシートにも自動反映されます。
※スクレイピングを行う上での注意点!
非常に便利なスクレイピングなのですが、使い方によっては著作権法や業務妨害罪に抵触する可能性があります。
著作権法で創作物の複製が認められるのは、その目的が私的利用あるいは情報解析の場合のみで、それ以外は違法となるようです。
サイトによっては利用規約でスクレイピングが禁止されている場合もございます。
またサイトへの過度なアクセスによってサーバに大きな負荷を掛けると業務妨害罪に抵触する可能性もございます。
スクレイピングをする際はこれらのことを踏まえた上で自己責任でお願いいたします。
この記事が気に入ったらサポートをしてみませんか?