ビジネスマン必読!AI時代のビジネススキル:大規模言語モデル(LLM)を理解する

今日、ビジネスの世界ではAIの理解がますます重要になっています。特に、大規模言語モデル(LLM)は、その進化と影響力により、ビジネスパーソンが知っておくべき重要なトピックとなっています。今回は、AIリサーチャーのSebastian Raschkaさんの記事を参考に、LLMの基礎についてわかりやすく解説します。これからのビジネスシーンで一歩先を行くために、LLMの基本を押さえておきましょう。
1. LLMとは何か?
大規模言語モデル(LLM)は、自然言語処理(NLP)の分野で急速に進化しています。これらのモデルは、人間のように文章を理解し、生成する能力を持っています。そのため、コンピュータビジョンや計算生物学などの分野でも革新的な影響を与えています。

2. トランスフォーマーとは?
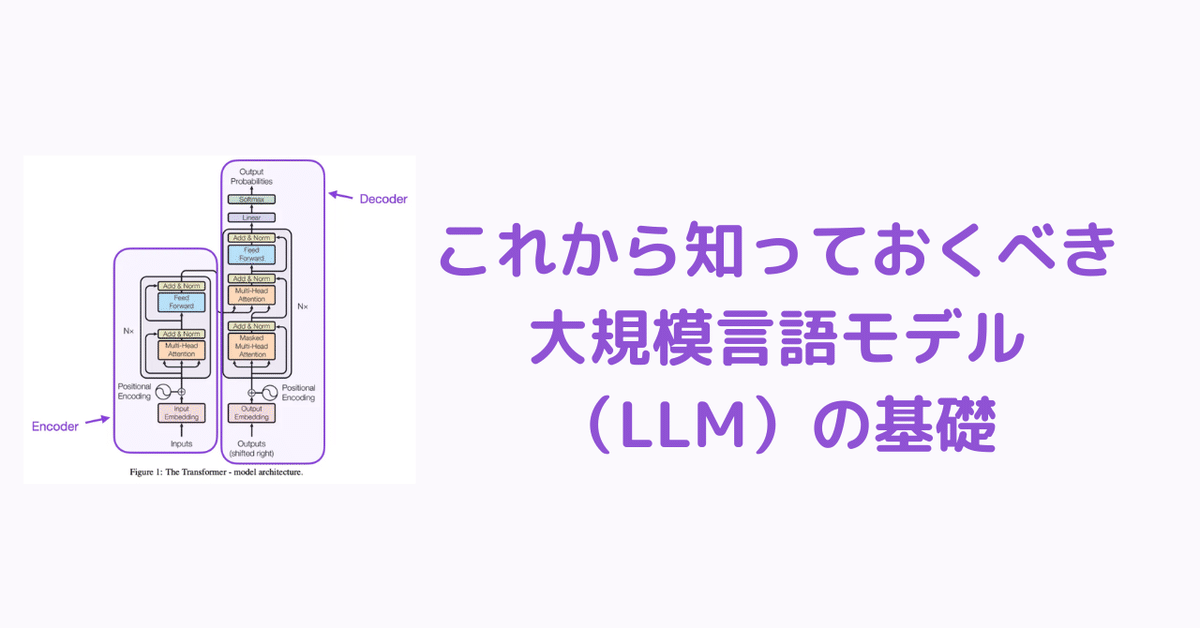
トランスフォーマーは、LLMの一種で、自然言語処理の分野を変革しました。これらのモデルは、文章の中の単語やフレーズの関係を理解するための「注意メカニズム」を使用します。これにより、モデルは長い文章をより正確に翻訳したり、理解したりすることが可能になります。
3. トランスフォーマーの進化
トランスフォーマーは、時間の経過とともに進化し続けています。例えば、最初のトランスフォーマーはエンコーダとデコーダの2つの部分から成り立っていましたが、現在ではこれらの部分は個別のモジュールとして使用されることが多くなっています。また、新たな概念や技術が導入され、トランスフォーマーの基礎となる要素が強化されています。
4. ファインチューニングとは?
LLMを特定のタスクに適応させるためには、ファインチューニングというプロセスが必要です。これは、大量のテキストデータでモデルを訓練し、その後、特定のタスクに特化したデータでモデルを微調整するという手法です。この手法は、BERT、GPT-2/3/4、RoBERTaなどの基礎モデルで一般的に使用されています。
5. BERTとGPT
BERTとGPTは、LLMの重要な例です。BERTは、マスクされた言語モデルと次の文予測を組み合わせたもので、テキスト分類などの予測モデリングタスクに適しています。一方、GPTは単方向の自己回帰モデルで、翻訳や要約などのテキスト生成タスクに適しています。

6. BART: エンコーダとデコーダの統合
BARTは、BERTとGPTの特性を組み合わせたモデルです。BARTはエンコーダとデコーダの両方を使用し、マスクされた言語モデルと自己回帰モデルの両方の特性を持っています。これにより、BARTはテキスト分類やテキスト生成の両方のタスクに対応できます。
7. データの重要性
LLMの性能は、訓練に使用されるデータの量と質に大きく依存します。大量のデータを使用することで、モデルはより多くのパターンを学び、より複雑なタスクを解決する能力を持つことができます。しかし、データの質も重要で、偏ったデータや誤ったデータはモデルの性能を低下させる可能性があります。
8. LLMの限界と課題
LLMは強力なツールである一方で、いくつかの限界と課題があります。例えば、モデルは訓練データに含まれる情報しか理解できないため、新しい情報や未知の概念に対応する能力は限定的です。また、モデルは人間のように意識的な思考や感情を持つことはできません。
9. 未来の展望
LLMの進化はまだ始まったばかりで、これからも新たな技術やアプローチが開発されることでしょう。また、モデルの理解力や適応力を向上させるための研究も進行中です。これらの進歩により、LLMはさらに多くの分野で有用なツールとなることが期待されています。

最後に
以上、大規模言語モデル(LLM)の基礎について解説しました。これらの知識は、これからのビジネスシーンで活躍するための重要なスキルとなります。この記事が、LLMの理解とその活用に役立つことを願っています。もし、この記事が役立ったと感じたら、ぜひ同僚や友人と共有してください。一緒に、AIの未来を切り開いていきましょう。
参考記事
この記事が気に入ったらサポートをしてみませんか?