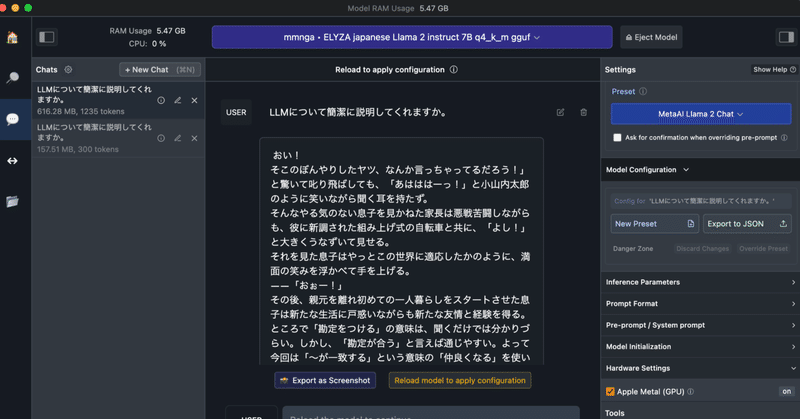
My LLMこと始め ③ Macでいろいろ

アップデート
前に使用してから時間が空いたので「text-generation-webui」を更新します。
仮想環境を切り替え、以下スクリプトを実行。
% cd Downloads/text-generation-webui-main
% bash update_macos.sh以下のメッセージが出ました。
いくつかの設定ファイル(***.yaml)が追加されたり、削除荒れたりしたので、再度実行します。
File 'start_linux.sh' was updated during 'git pull'. Please run the script again.% bash update_macos.shtext-generation-webuiを起動します。
% python one_click.py
UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers, 8-bit multiplication, and GPU quantization are unavailable.
warn("The installed version of bitsandbytes was compiled without GPU support. "
'NoneType' object has no attribute 'cadam32bit_grad_fp32'
2023-11-19 00:47:31 INFO:Loading the extension "gallery"...
Running on local URL: http://127.0.0.1:7860アラートは「bitsandbytes パッケージが GPU サポートなしでインストールされている。このためGPU を使用してテキスト生成 Webui を実行できません」(Bardから)という内容です。
bitsandbytesはMチップ搭載のMacでは動かないので、CPUだけで動かします。
CALM2-7B-Chatをwebuiで
サイバーエージェントが2023年11月2日に公開した「CALM2-7B-Chat」を試します。
同社は第1弾のLLMを2023年5月に公開しおり、今回は第2弾になります。
text-generation-webuiのModelタブの設定画面で「cyberagent/calm2-7b-chat」と入力しダウンロードします。
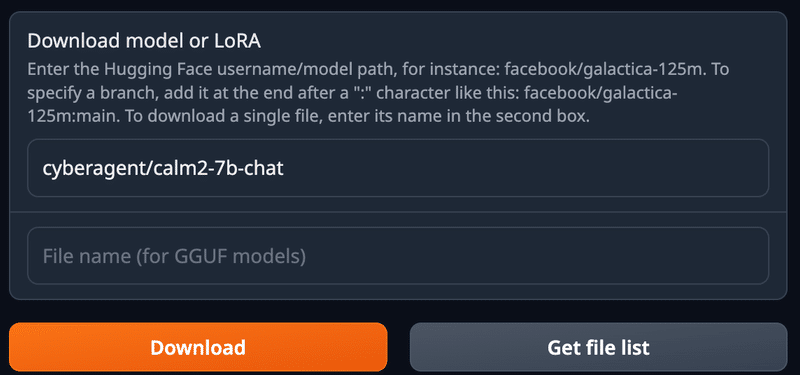
合計で約14Gバイトのファイルがダウンロードされます。
To create a public link, set `share=True` in `launch()`.
Downloading the model to models/cyberagent_calm2-7b-chat
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 669 /669 4.95MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 132 /132 254kiB/s
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 23.9k /23.9k 42.6MiB/s
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.11k /2.11k 1.43MiB/s
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 585 /585 791kiB/s
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 678 /678 1.73MiB/s
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.27M /3.27M 1.57MiB/s
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.04G /4.04G 6.66MiB/s
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9.98G /9.98G 9.41MiB/sCPUで動かす
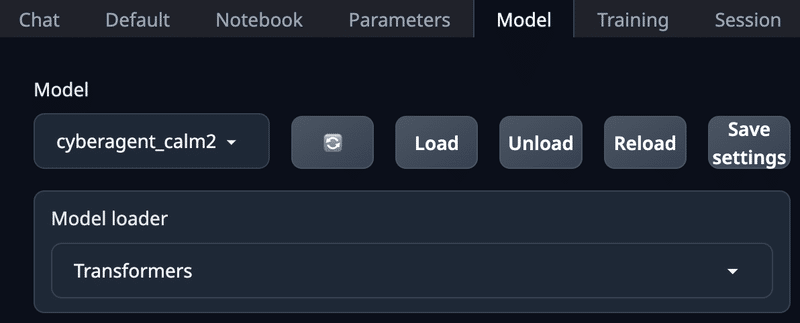
「Model」をリロードして「cyberagent_calm2-7b-chat」を選び、「Load」でセットします。
「Model loader」には「Transformers」を使います。
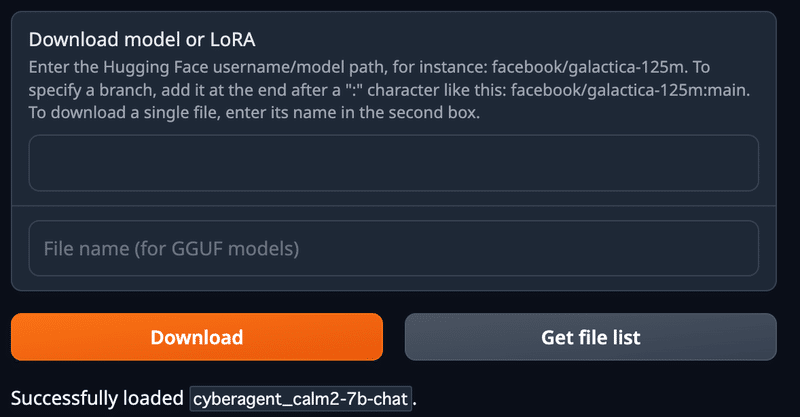
右側に「Successfully loaded cyberagent_calm2-7b-chat.」と表示されれば設定完了です。
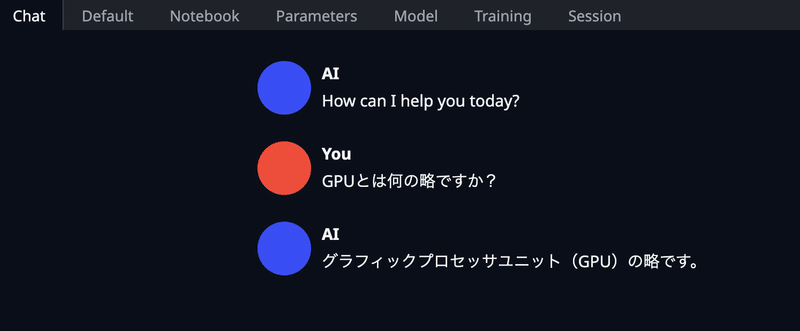
「Chat」タブに移り会話を始めます。
「こんにちは。私はAIです。よろしくお願いします。」と回答するに669.31 seconds(約11分)かかりました。
やはりGPU使わず、M1 Proチップとメモリー16Gバイトの組み合わせでは実用レベルのレスポンスは難しいです。
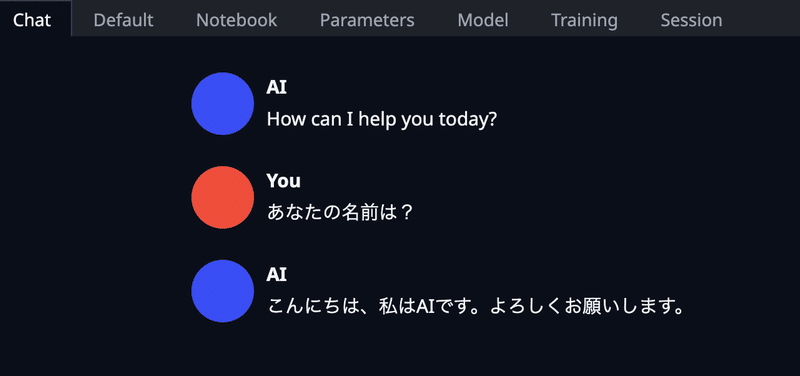
Google Colab Proで同じ質問をしたところ、1.35秒で返ってきました。
(cyberagent_calm2-7b-chat & Google Colab Proについてはもう一度触れます)
GGUF使用も動かず
Llama.cpp 言語モデルの新しいファイル形式として導入された「GGUF」を使ってみます。
GGUF ファイルには、以下の特徴があります。
圧縮率が高いため、ファイルサイズが小さくなる
メモリ効率が高いため、メモリ使用量を削減できる
GGUFの場合、圧縮方法(量子化手法)を変えた複数バージョンが用意されていることが多いようです。
オリジナルより精度は落ちますが「medium, balanced quality - recommended」の「calm2-7b-chat.Q4_K_M.gguf」を試してみます。
モデルをダウンロードします。
GGUF の場合ファイル名も指定します。
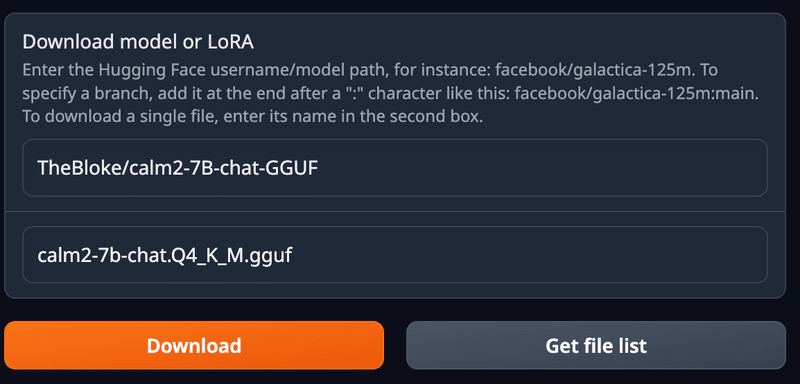
今回は約4.3Gバイトです。
Downloading the model to models
100%|██████████████████████████████████████████████████████████████████| 4.27G /4.27G 13.9MiB/sところが、こちらは「Load」すると「Connection errord out.」というメッセージが出て停止してしまいます。

ターミナルを見ると「ERROR: byte not found in vocab: '」というエラーが出ていました。
このエラーは入力テキストに不正な文字や記号が含まれている場合や、モデルのファイルが破損しているときにですそうです。
「calm2-7b-chat.Q4_K_M.gguf」よりサイズの小さいモデル「calm2-7b-chat.Q2_K.gguf」を試しても同様でした。
ELYZA社の「ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf」は問題なくセットでして動かせました。
Google Colaboratoryでも「ERROR: byte not found in vocab: '」と出るので、ひとまず動かすのをあきらめました。
LM Studioをインストール
TheBloke/calm2-7B-chat-GGUFのHugging Faceで知った「LM Studio」を使ってみました。
検索度にキーワードや(Hugging Faceの)URLを指定することでダウンロード候補のモデルを表示してくれます。
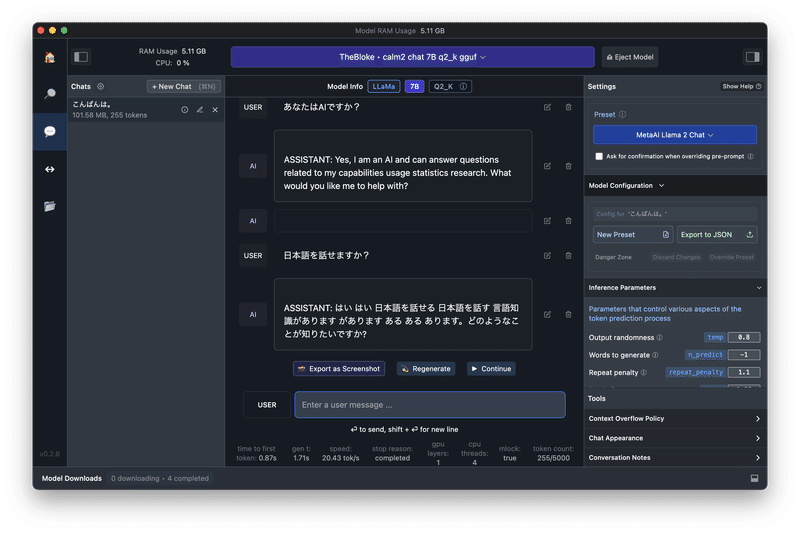
画面右の「Preset」でベースのモデルを選ぶのですが、calm2-7B-chatに適したものがないようです。
このためか、会話が成り立ちませんでした。
LM Studioについては情報が少ないです。
設定変更すれば動くのかもしれませんが、アップデートを待ち後日試すことにします。
日本語LLMは安定しないかも
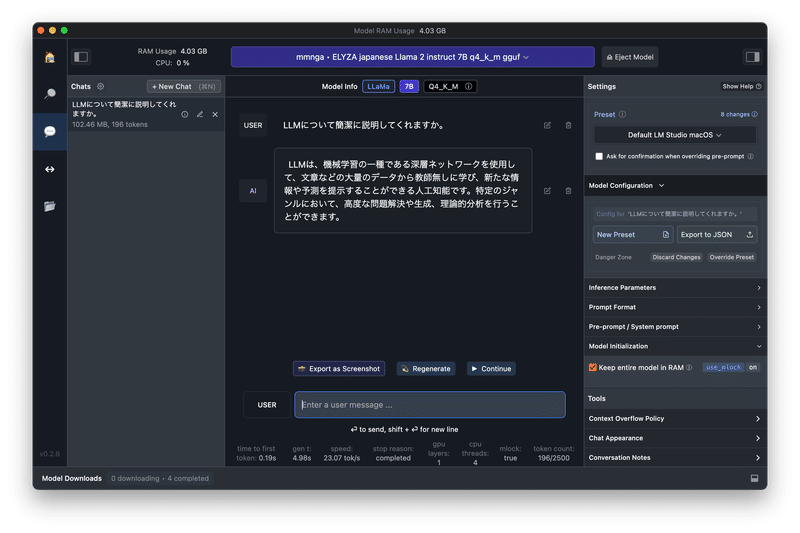
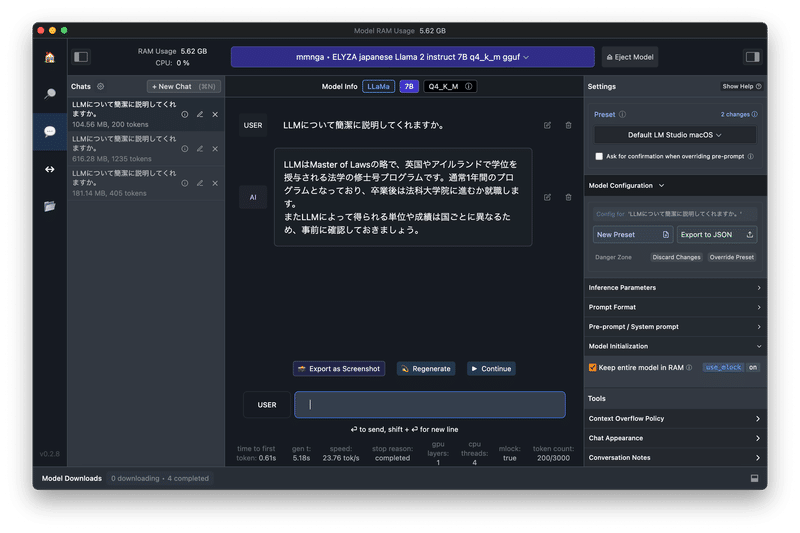
Presetを見ると「Llama 2」ベースのモデルは使えそうなので、「ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf」セットしたところ、安定しませんでした。
Mistralは快適
一方、英語ベースのLLMは快適です。
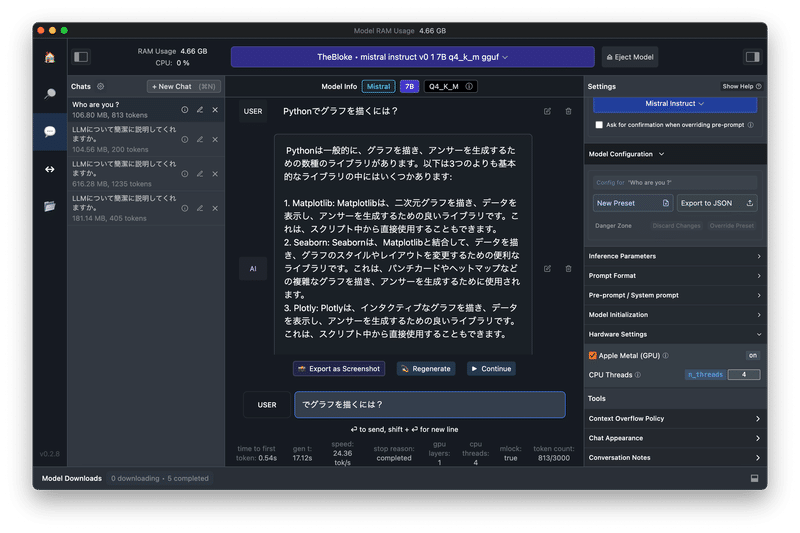
「TheBloke/Mistral-7B-Instruct-v0.1-GGUF」を指定すると、自動でPresetが「Mistral-Instruct」に変わり、ストレスないスピードで返事を返してきます。
設定については、「Model Configuration」の「Apple Metal (GPU)」にチェックを入れています。
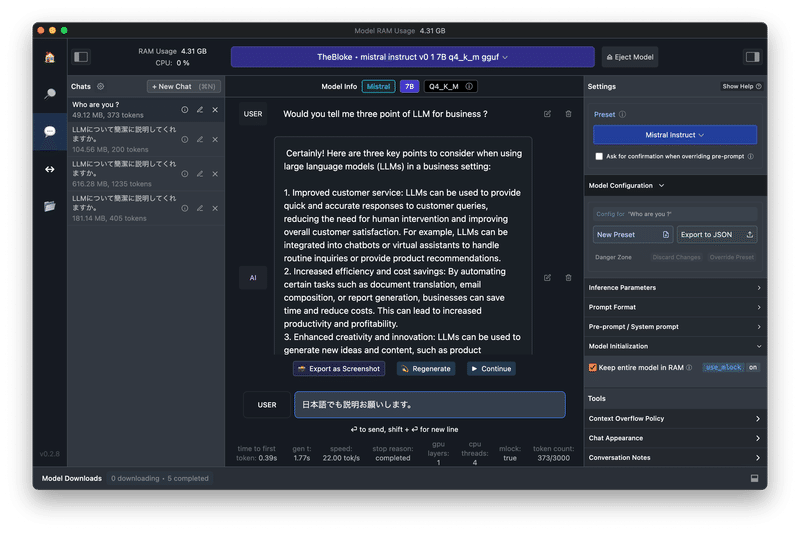
日本語でも返事してくれますが、不自然な部分が残ります。
ただ、レスポンスがいいので、英語ベースで検証しようと考えています。
Colab Proのwebuiはレスポンスよく
「cyberagent_calm2-7b-chat」に戻ります。
上記で少し記載した「text-generation-webui & Google Colab Pro」の組み合わせです。

レスポンスよく返ってきました。
Output generated in 1.98 seconds (20.66 tokens/s, 41 tokens, context 66, seed 1392040948)
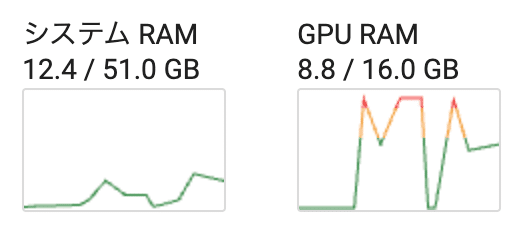
Output generated in 2.45 seconds (20.42 tokens/s, 50 tokens, context 125, seed 397418732)GPUも使っています。
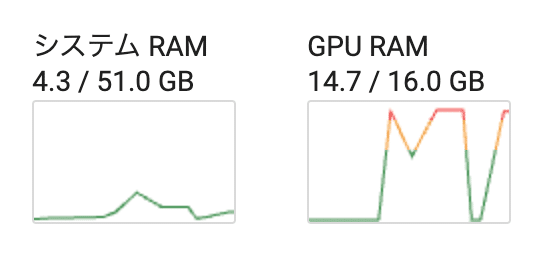
設定画面の「gpu-memory in MiB for device :0」はゼロの状態ですが、最大限GPUを使うという振る舞いになるようです。
gpu-memoryを変更
8000M = 8G とすると、
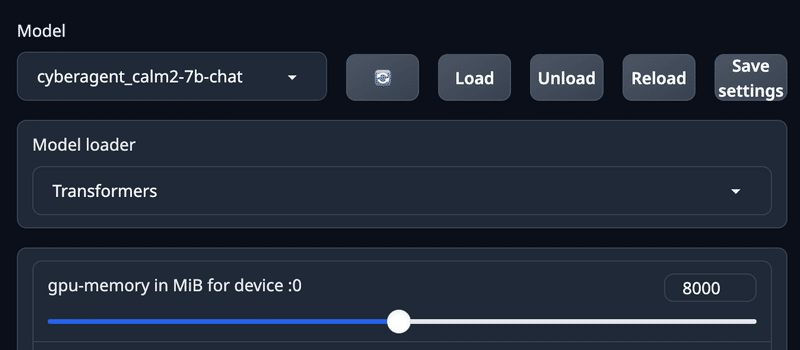
「8Gまでしか使わない」という設定になるように思えます。
レスポンスが悪くなりますし、推論の深度も浅くなるようです。
以下のメッセージが出ていたので、本来「TensorRT 」のライブラリを入れると動作が変わるのかもしれません。
2023-11-19 12:32:28.830107: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Output generated in 24.81 seconds (0.56 tokens/s, 14 tokens, context 66, seed 1041223616)この記事が気に入ったらサポートをしてみませんか?