
FooocusのInput Imageを今後も使うためのメモ

画像を用意
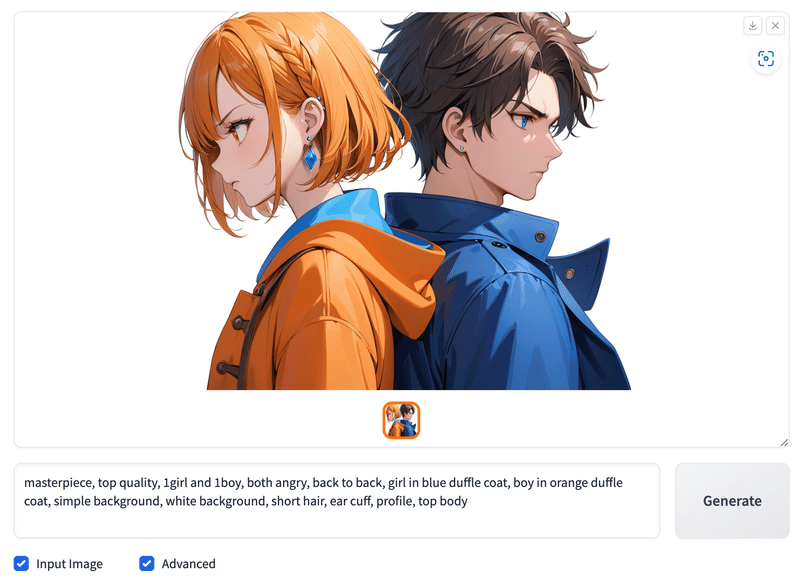
FooocusのInput image。
Image Prompt など、画像をプロンプトとして使うImage To Image機能が使用可能。
# Fooocusを使い、angry(怒っている)を使ったプロンプトで画像生成。
# 使用したモデルはCivitaiから取得したanima_pencil-XL。
# 画面下のAdvancedにチェック。
# Model→Base Modelで以下コードでダウンロードしたモデルを選択。
# Fooocusインストール
!pip install pygit2==1.12.2
%cd /content
!git clone https://github.com/lllyasviel/Fooocus.git
# デフォルトモデル以外を使用
# anima_pencil-XL (上記のblue_pencil-XL の上位バージョン)
# https://civitai.com/models/261336
!apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/435001 -d /content/Fooocus/models/checkpoints -o anima_pencil-XL.safetensors
%cd /content/Fooocus
!python entry_with_update.py --sharemasterpiece, top quality, 1girl and 1boy, both angry, back to back, girl in blue duffle coat, boy in orange duffle coat, simple background, white background, short hair, ear cuff, profile, top body

Upscale Variation(変化)
Upscale VariationのVariationは元画像に対して変更を強弱で指定。
Disabled、Vary(Subtle)、Vary(Strong)はそれぞれ、
元画像を参考にしない、ちょっと変更、大きく変更。
元画像&プロンプトの組み合わせで使用。
Upscaleについては後述。
# Fooocusの画面下からInput Image。
# Upscale Variationタブの、Vary(Subtle)にチェック。
# Vary(Subtle)はちょっとの変化。
# プロンプトにlaughing(笑い)。
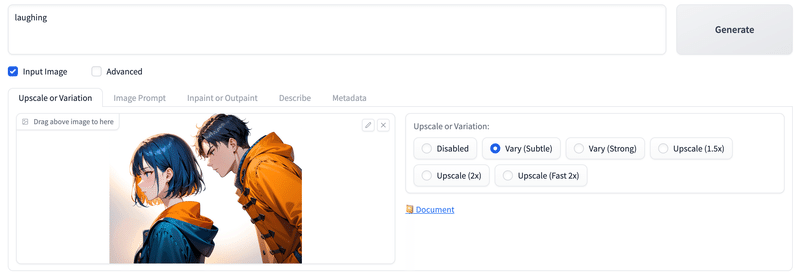
生成結果。

# 強めに変化するVary(Strong)にチェック。
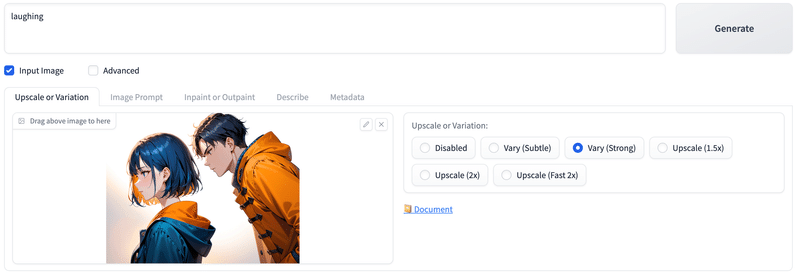
生成結果。

Impaint or Outpaint
Impaint or Outpaintは部分修正。
こちらも元画像&プロンプトの組み合わせで使用。
# Impaint or Outpaintタブを選択。
# ペンツールで再描画エリア指定(今回は耳付近)。
# プロンプトに「silver big earring」。
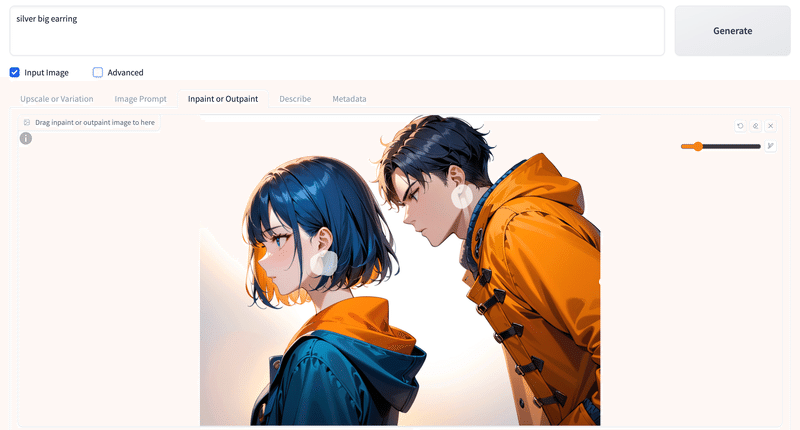
生成結果。
色や形状は異なるけど、プロンプト通りイヤリングを追加生成。

Upscale or Variation(拡大)
Upscale or VariationのUpscaleは画像拡大。
2xを選べば縦横の解像度を2倍。
# Upscale or Variationに戻りUpscale(2x)。
# Upscaleは画像拡大し精細な画像を生成。
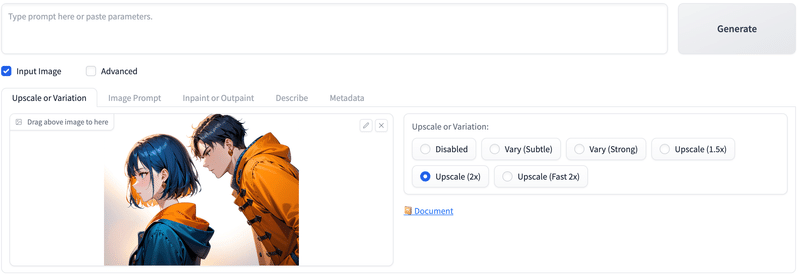
生成結果(上がUpscale前、下がUpscale後)。


Image Promot
Image Promotは画像をプロンプトに使う。
Upscale Variationは元画像&テキストプロンプトで一部分変更。
Image Promotは元画像&テキストプロンプトで全体的に変化を与える。
Image Promotについては他の機能もあるので後述。
# Image Promptタブで犬の画像をアップロード

# プロンプトに「black cat」。
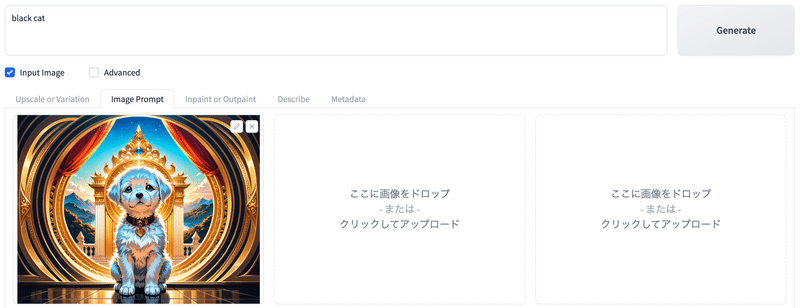
生成結果。

うまくいかないのでアニメエディション
複数画像のパターンで試してみる。
モデルによってうまくいかないことがあるらしい。
Fooocusのアニメ用プリセットに切り替え。
%cd /content/Fooocus
!python entry_with_update.py --preset anime --shareまず以下のプロンプトで画像生成。
masterpiece, top quality, 1girl and 1boy, both smiling, back to back, girl in blue duffle coat, boy in orange duffle coat, full body
もう一枚の背景に使う画像は、ChatGPTのDALL·E 3で生成。
# Image Promptタブ。
# 画面下のAdvancedにチェック。
# 2枚の画像をアップロード。
# ImagePromptのラジオボタンにチェック。
# Stop AtとWeightはデフォルトのまま。
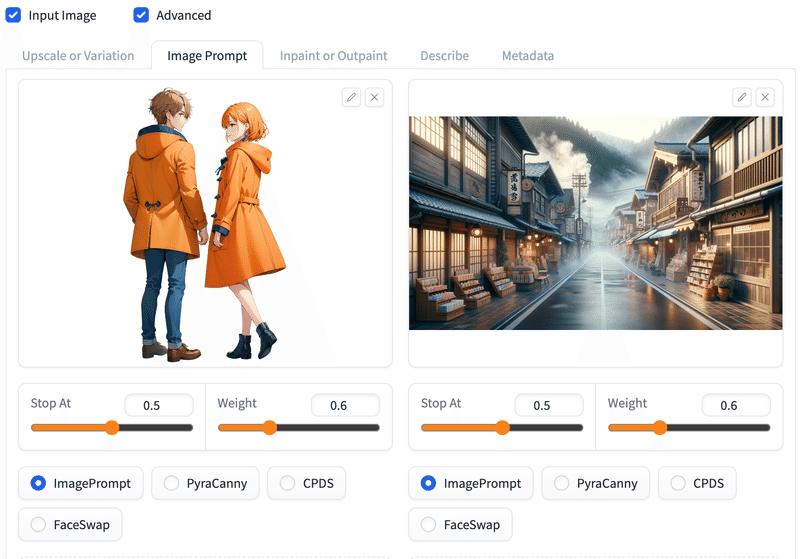
生成結果。

Stop AtとWeight
# Stop Atは生成開始からどのタイミングまで影響範囲か(らしい)。
# Weightは画像の影響の強さ。
# Weightの方がわかりやすいの主にこちらを使う。
画面右のWeightを大きくした例。
(テキストのプロンプトは使用していない)
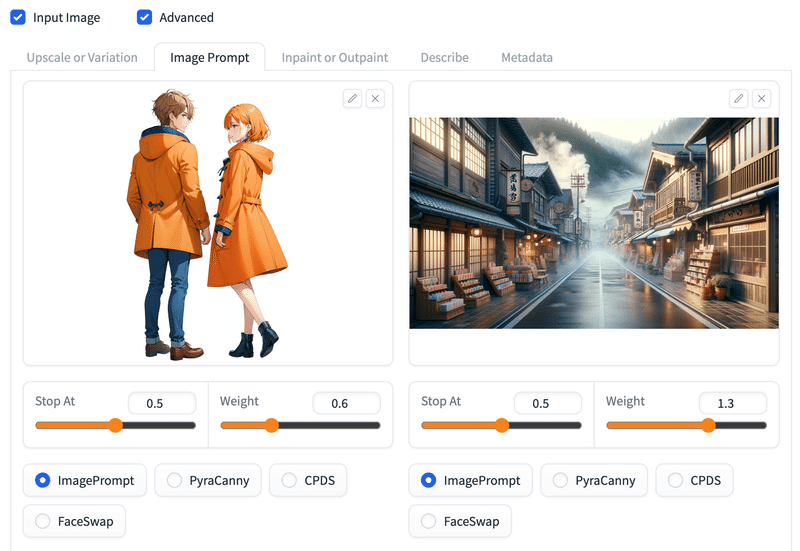
生成結果。
右画像の背景の影響を強く受けている。

左画像のWeightを大きくした例。
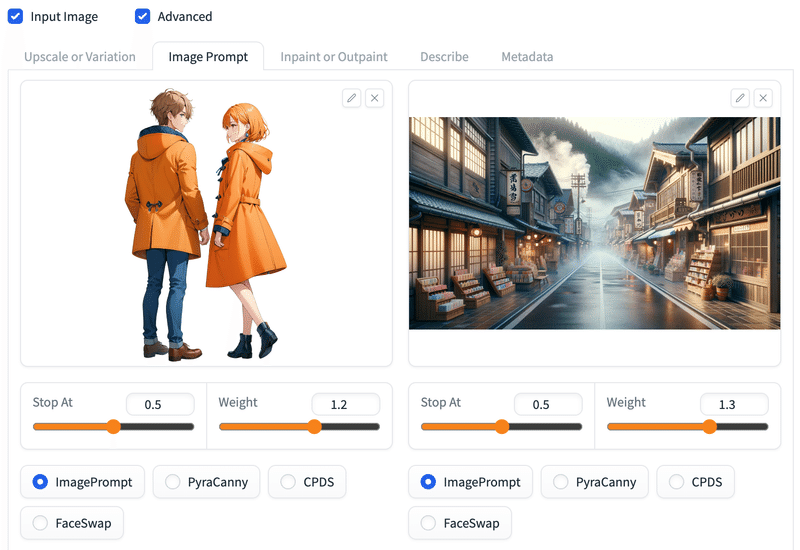
生成結果。
左画像のキャラクターが目立つ。

背景と馴染んでないので、左画像のWeightを下げる
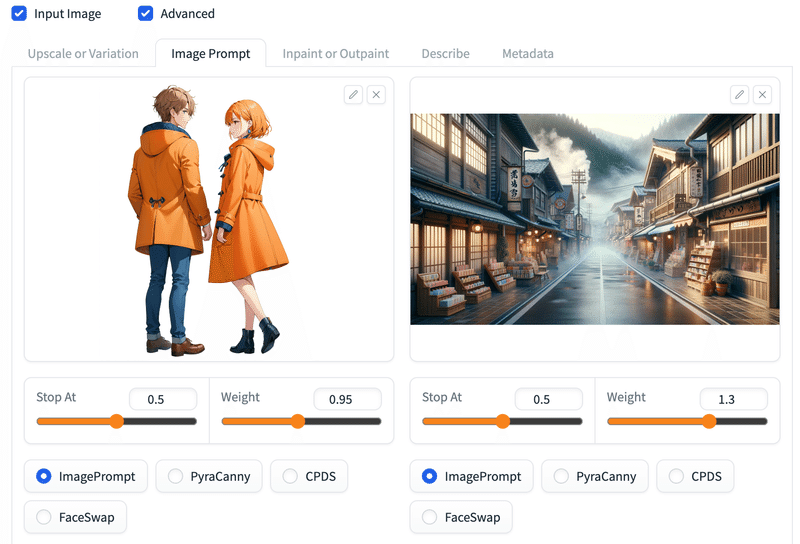
生成結果。

画像3枚を掛け合わせ
# 3枚目の画像を追加。
# 最初にWeightで調整(3枚目)。
# 追加でStop Atの値を大きくすると効果的(らしい)。
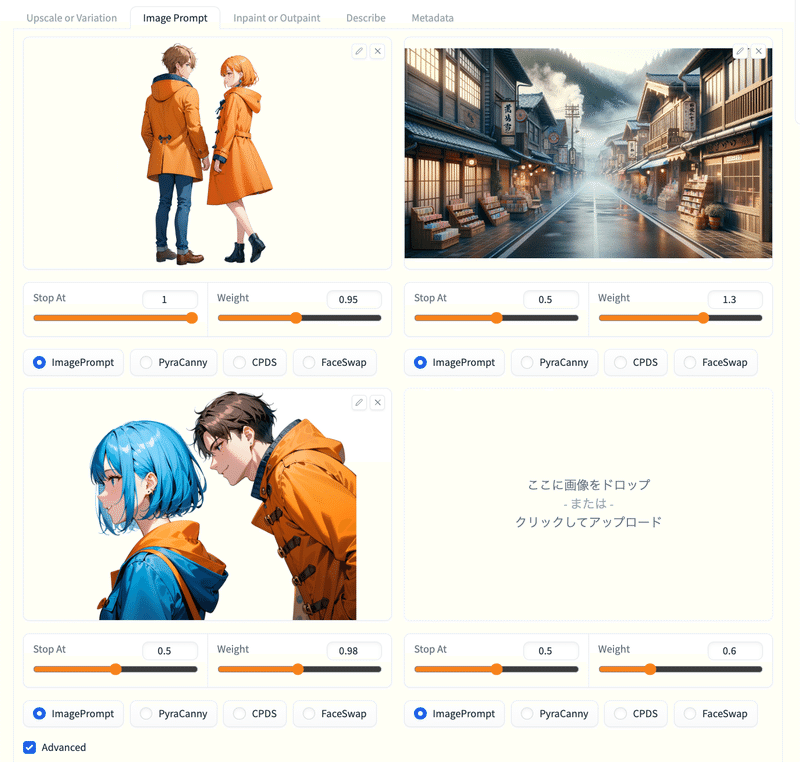
生成結果。
Weightで3枚目の画像の洋服の色が反映。
追加で1枚目のStop Atを大きくすることでポーズを似せられた模様。
複数の画像を重ねるのでなく、1枚の画像のポーズを真似る機能は次。

Image PromptのPynaCanny
元画像のキャラクターと同じポーズにする場合はPynaCanny。
# Image Promptタブ。
# PynaCannyのラジオボタンにチェック。
# テキストのプロンプトは使わない。
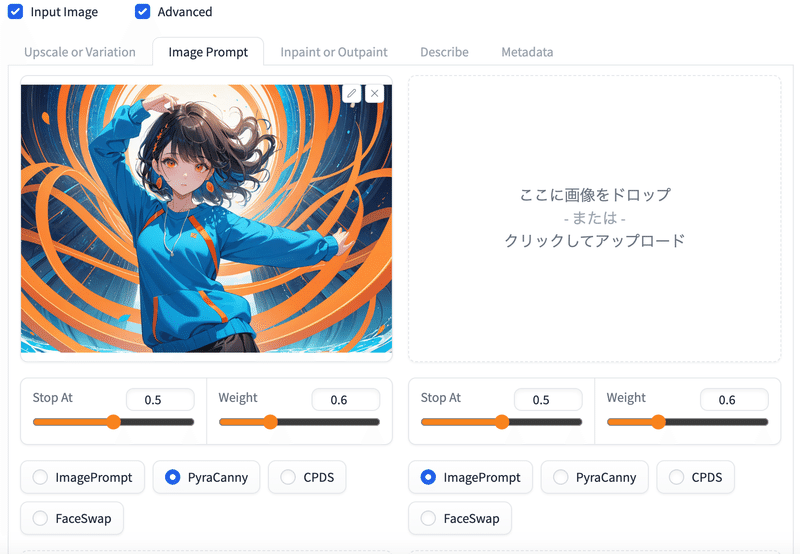
生成結果。

Image PromptのCPDS
CPDSはPynaCannyと同様にポーズを似せる。
PynaCannyの方が忠実に真似てくれる感じ。
使い分けは今後調べる。
# Image Promptタブ。
# CPDSのラジオボタンにチェック。
# テキストのプロンプトは使わない。

生成結果。

Image PromptのFaceSwap
FaceSwapは顔の部分だけ使って画像を生成する機能。
アニメスタイルのモデルはプロンプトを変えても顔が似る。
このため、Fooocusのデフォルトのプリセットに切り替え。
%cd /content/Fooocus
!python entry_with_update.py# Image Promptタブ。
# CPDSのラジオボタンにチェック。
# テキストのプロンプトを使用。
(このプロンプトで生成した画像に元画像の顔を使う)
# Weightを多少大きく調整。
ます以下のプロンプトで元画像を生成。
wearing blue stole, short hair, black hair
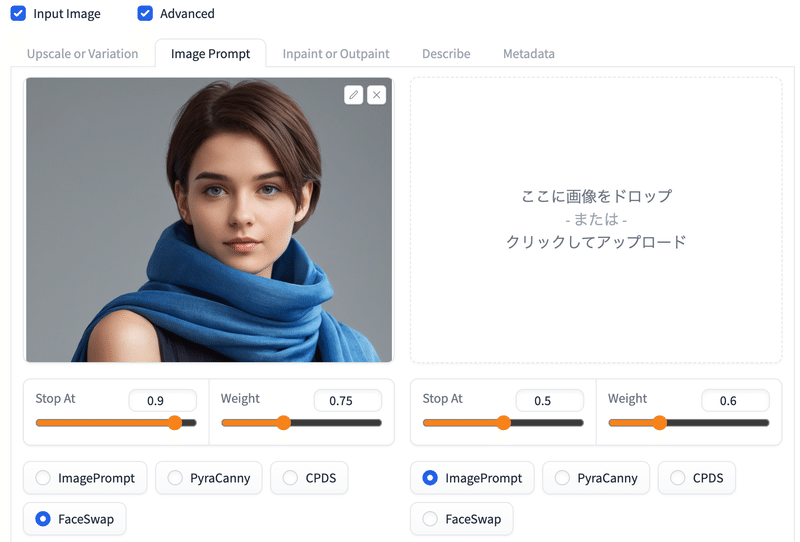
今回テキストのプロンプト。
髪の長さを認識させるため「short hair」を入れている。
wearing outdoor jacket, spring season, short hair, a bit of blue, forrest, yellow flower

リアルとアニメ調の掛け合わせ
リアル画像を作ったので、上述のImage Promptで作成したアニメ調画像とと掛け合わせ。
# Image Promptタブ。
# ImagePromptのラジオボタンにチェック。
# テキストのプロンプトを使わない。
(このプロンプトで生成した画像に元画像の顔を使う)
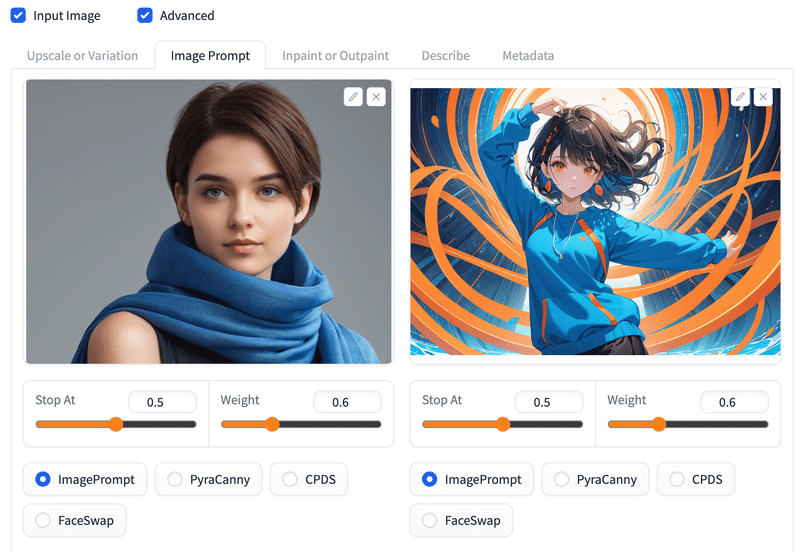
生成結果。

# Weightを多少大きく調整。

生成結果。
左側の画像の影響がより強く出る。

Descrbe
Describeは画像の説明、つまりプロンプトに変換する。
# Describeタブ。
# 今回はArtAnimeのラジオボタンにチェック。
# Describe this Image into Promptボタン。
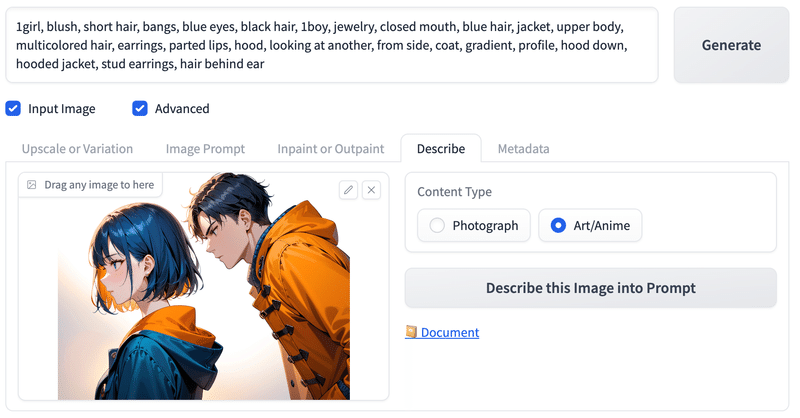
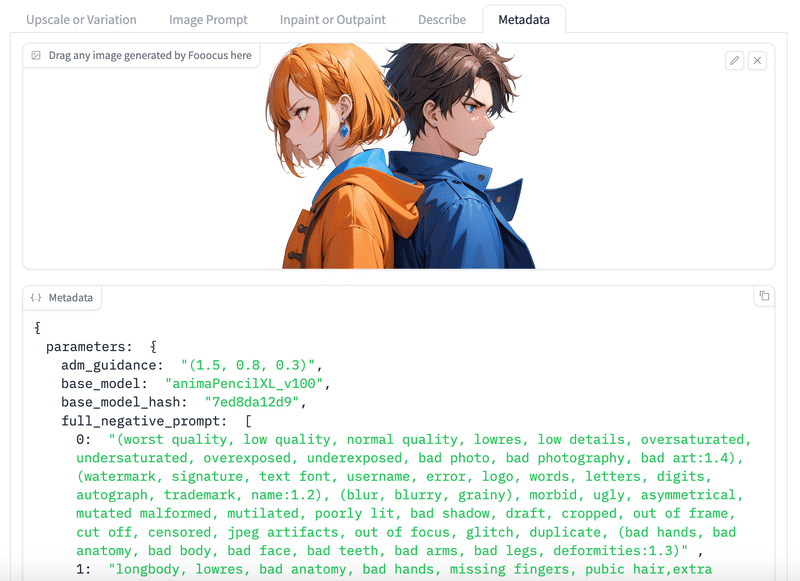
Metadata
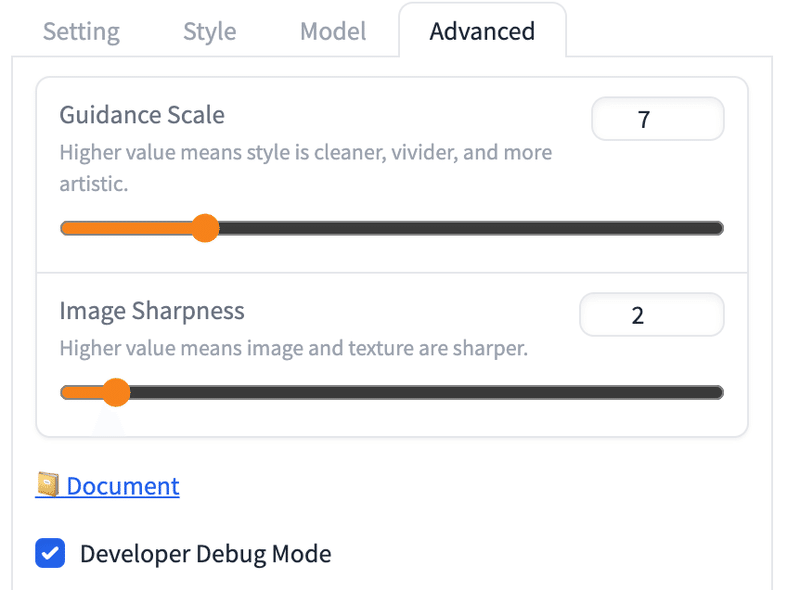
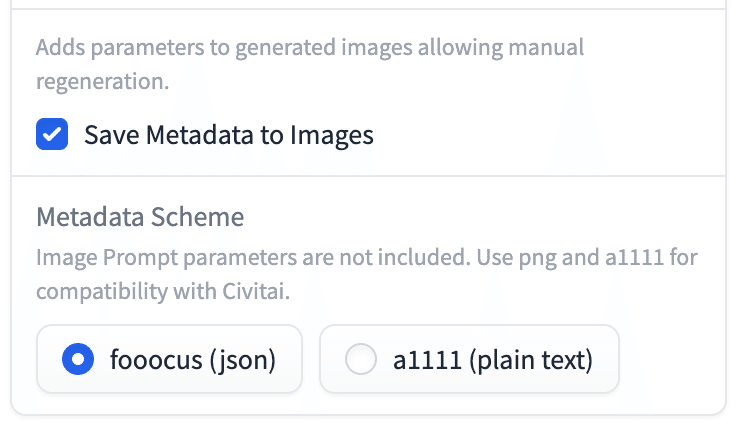
学習時に使用されたパラメータを記録するMetadata。
MetadataはJSONやPlain Textを埋め込んだPNGで保存可能。
# 記録可能にするにはAdvanced → (右パネルの)Advanced →
Developer Debug Modeにチェック →
Save Metadata to Imagesにチェック。
以下プロンプトで生成(最初に使ったものと同じ)。
masterpiece, top quality, 1girl and 1boy, both angry, back to back, girl in blue duffle coat, boy in orange duffle coat, simple background, white background, short hair, ear cuff, profile, top body
Metadataタブにこの画像をドラッグ&ドロップ。
ができるようだけど、できなかったので以下手順。
# Google Colabの/content/Fooocus/outputs/YYYY-MM-DD
に保存されたPNGファイルをダウンロード
# Metadataタブにドラッグ&ドロップ。
画像下にMetadataを表示。
# 画面下のApply Metadataボタンをクリック。
# Generateボタンをクリック。
同じ画像を生成。

この記事が気に入ったらサポートをしてみませんか?