Lec6:単回帰分析④結果の見方と係数の検定

みなさんこんにちは。矢野大樹です。オリンピック真っ只中ですね。今日もスケートボードの堀米選手が初代金メダリストになったりと熱い勝負が繰り広げられています。個人的な楽しみは20:00から開幕されるサッカー男子U24日本vsメキシコですかね。オリンピックの場合は欧州より中南米の方が強い傾向がありますので、これは楽しみです。あと、体操では男子の団体で我が出身校清風高校出身の選手が出場します。金メダルが取れるか、注目したいです。(なお、その清風出身の選手の監督・コーチには中3、高1、高2の体育で教科担当としてお世話になったことがあります。)
長々と話してしまいました。今日は前回の続きです。Excelで回帰分析を実行すると、次のような画面が表示されましたね。

今日はここに表示されている各種指標の説明と、係数の検定についてお話していきます。これも、卒業論文を執筆する際は必ず盛り込まないといけないので、正確に理解するようにしてください。(ただし全然難しくありません)
まず、『回帰統計』の部分から見ていきましょう。ここで重要となる指標は『決定係数』ならびに『自由度修正済み決定係数』の2つです。これらは、簡単に言うとモデルとなる直線にデータがどれくらい当てはまっているのかを表す指標です。決定係数は0から1までの値を取り、1に近いほどモデルの当てはまりが良いと言えます。ただし、この数値が低いからといって因果関係が無いと結論付けるのは誤りです。両者には全く関係がありません。逆に決定係数が0.9を超えていたからと言って因果関係があるというのもまた間違いです。

誤差項uiとは、XとYの関係性上どう頑張っても説明できない部分のことです。(これ無茶苦茶大事です。説明できないと思っていたら、実は説明できてしまった、というのが一番やってはいけないパターンです。この点については、次回説明します。)つまり、Yの動き全体のうち何%をちゃんと説明できているか、を表す指標だとも言えます。
『自由度修正済み係数』とは単回帰分析ではあまり気にする必要がありませんが、重回帰分析で説明変数の数を増やすと、決定係数の値が自動的に大きくなる傾向があります。そこで、自由度(後のt検定でも出てきます)を考慮した決定係数を考えるわけです。重回帰分析の際は、この『自由度修正済み決定係数』もちゃんと見る必要があります。
何度も言いますが、あくまで決定係数とはモデルの当てはまりを表したものであり、因果関係を表すものではないということです。この部分を結構間違えてしまいがちなので、気を付けてください。
では、次に係数の検定に移りましょう。前回のシミュレーション実験では、直線y=2xを軸としてデータを無作為に生成しました。なので、回帰分析における真の値はβ1=2です。ただし、いつも真の値が分かるとも限りません。また、使うデータによって結果が変わったりします。


例えば、上記の場合は先週生成したデータのうち、最初の10個、100個のデータを用いて回帰分析を行ったものです。結果を見てみると、それぞれβ1の値は2.259004, 1.86005となっています。今回は真の値が2であることが分かっていますので、誤差なんだろうなあってのが言えますが、真の値が分からない場合、どこまでを誤差とみなしてよいのでしょうか。また、真の値が例えば2であると結論付けて良いのでしょうか。
ここで必要となるのが、分散分析表の中にある係数と標準誤差という値を用いて計算するt統計量(t-statistics)という数値です。このt統計量(t値)を用いて判断するというわけです。


今回はt検定なのでt分布表を使用します。

(出典:James H. Stock, Mark W. Watson著/宮尾龍蔵訳『入門 計量経済学』共立出版)
だいたいの教科書や試験などで必ず配布されますし、調べればいくらでも出てくるのですが一応掲載しておきます。この表で押さえておきたい点は自由度と片側/両側という2点です。自由度とは簡単に言うと自分で設定することの出来る数のことです。例えば、三角形を作るときの角度の自由度は2です。三角形の内角和は180度なので、2つ角度を決めてしまえば、残り一つは自動的に決まってしまいます。回帰分析の場合は、(サンプル数-説明変数の数-1)で決定します。サンプル数が100で単回帰分析を行う場合は、自由度は98になります。表では自由度が120までしか具体的に書かれていませんが、120を超える場合は一番下の∞と書かれた行を使用すればOKです。
次に、両側と片側の違いですが、簡単に言うと臨界値をどこに設定するかの違いです。
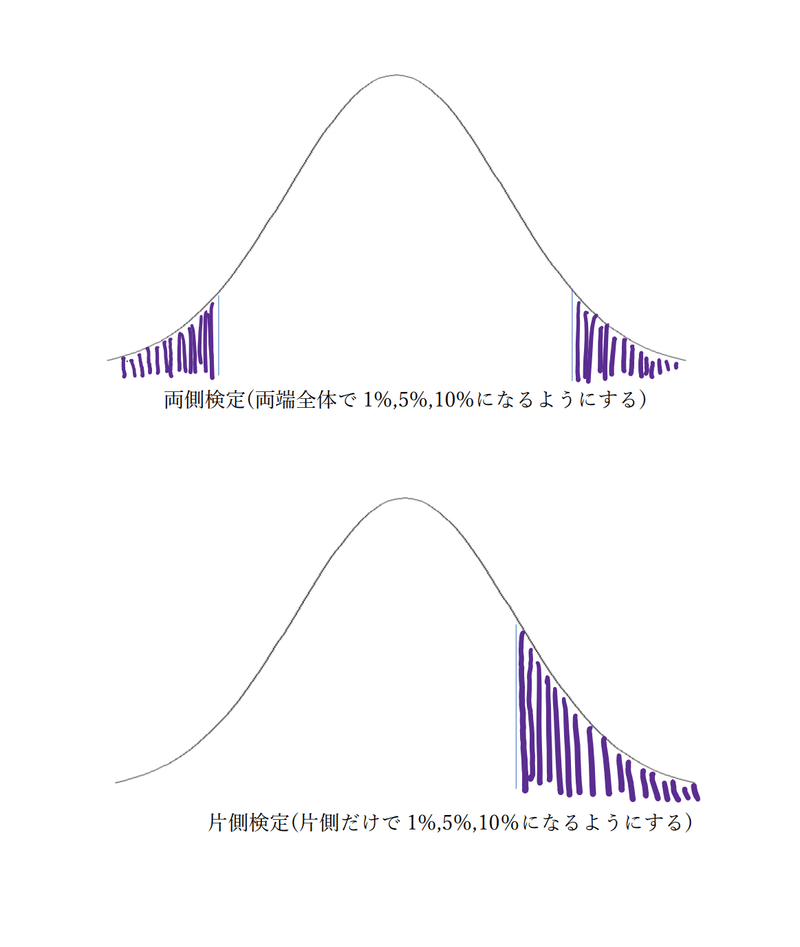
回帰分析では、基本的に両側検定を使用します。(片側検定はよほど特殊な場合を除き殆ど使用しません) 。そもそも、t分布を用いた検定の意味とは、真の値と思う数字が本当にそうなのかを確かめるためにありました。もし真の値が2なのであれば、程度の誤差はあれ出力結果は2に近い数字が出るはずで、2から極端に離れた数字は出にくいはずです。もし2より極端に離れた値が出てしまったならば、通常の確率では起こりえないことが起こってしまったと考え、最初の考え、つまり真の値が2であると予想したことそのものがおかしいのではないか、と考えるわけです。そして、その極端に離れているかどうかの基準が、臨界値ということになります。
ということは、極端に離れているかどうかを知りたいわけなので、片側だけでは不十分でしょうという話になります。よって、両側検定を用いることが多いのです。
両側検定で有意水準5%で検定する場合、両サイド合わせて5%になるように設定します。つまり、片方ずつ2.5%で設定するというわけです。10%の場合は片方ずつ5%で、1%の場合は片方ずつ0.5%です。これらの数字が、t分布表に記載されている片側と両側の意味です。
一般的な回帰分析では、有意水準は5%を採用すると言いました。また、片側検定ではなく両側検定で行うことが多くなると言いました。卒業論文では、両側検定の有意水準5%で検定することが一般的です。なので、t分布表のちょうど真ん中の列(両側5%/片側2.5%)はよく使うことになると思います。特に、データ数は通常は少なくとも数百以上はあるはずなので、(逆にデータ数が少なすぎると回帰分析が正しく因果関係を反映しなくなります。)自由度∞の行と両側5%/片側2.5%の列が交わるところにある1.96という数字は本当に臨界値としてよく使うので覚えておいてください。一般的には、出力されたt統計量が1.96を上回るかどうかで判断します。
ちなみに、ExcelやR、Stataの回帰分析の結果を見ると、t統計量が自動的に計算されていますが、これは真の値をβ1=0と想定した上でのt統計量です。つまり、帰無仮説H0をβ1=0、対立仮説をβ1≠0としたうえでの検定になります。この時のt統計量は、真の値と仮定した数値が0なので、単に出力された係数の値÷標準誤差で求めることが出来ます。(実際に、一番最初の画像で書かれている係数1.987011をその横の標準誤差0.043964で割るとt=45.2114.....という数字が出てきます。明らかに45.2114.....>1.96なので、今回は帰無仮説H0:β1=0を棄却して、対立仮説を採択します。)
何でβ1=0を自動的に計算するのかというと、一番嫌なのがβ1=0の時だからです。β1=0とは、説明変数と被説明変数の間に一切の因果関係が認められないということを表します。少なくとも、出てきた係数が0ではないということは真っ先に証明したい、というわけです。
長くなりましたが、これがいわゆるt検定、t値というものです。無茶苦茶大事なので、是非抑えてください。
次に、t値の横に記載されているp値について説明します。これは簡単です。p値とは、t値について|t|より分布の端にある面積が、分布全体に占める割合のことです。

p値はt値と違って、自力で計算することが出来ません。機械が勝手にやってくれます。有意水準を5%と設定した場合、p値が0.05を下回っていたらこれは明らかにt値が臨界値より大きいことを表していますので帰無仮説を棄却するという話になります。ただ、メインはあくまでt値であるということに注意してください。
最後に、信頼区間(confidence interval)のお話をして終わりにします。信頼区間とは、ある確率で真の値がこの区間に含まれていますよ、ということです。先ほども言いましたが、真の値は基本的には分かりません。また、検定をやったとしても具体的な数値を導出することまでは出来ません。なので、せめてこの範囲に真の値が含まれていますよ、ということだけでも知りたいわけです。今ある確率でと言いましたが、基本的には95%の確率を使います。(他には90%と99%があります。) 95%の確率で真の値が含まれている範囲を調べよう!というわけです。
計算自体はとても簡単です。出てきた係数の値と臨界値、それから標準誤差を使って次のように計算します。

臨界値はt検定の時に使った値です。多くの場合は1.96になると思います。ただこれもExcelやRでの結果出力の際に95%の信頼区間は記載されていますので、手計算する必要は基本ないでしょう。導出方法とその意味だけ押さえておけば十分です。
長々と話しましたが、今日の内容をしっかり理解すれば、回帰分析の結果を正しく分析できるようになります。是非抑えておいてください!!
来週は、私期末試験がありますので、記事の更新をお休みさせていただきます。次回は、出力されたβ1の値が、本当に因果関係を反映しているかどうかについてのお話をさせていただきます。
一番最初の記事で、回帰分析は極めて厳密な仮定の下実行されるものであると言いました。その『極めて厳密な仮定』を次回お話します。この仮定をきっちり分かっていないと、本当は因果関係を表していないのに、因果関係を表していると間違った結論を下してしまう事もあります。かなり難しいお話になりますが、ここを乗り切ることが出来れば、回帰分析の基礎は完成したと言えると思います。次回かなりの難所です。私も頑張りますので、是非最後までお付き合い下さい。
Best Regards,
Daiki YANO
この記事が気に入ったらサポートをしてみませんか?