
調達、購買部門向け生成AI、Python活用(PDFをChatGPTに書かせたPythonコードで加工)

突然ですが、会社PCにアクロバット入れてますか?
アクロバットリーダーではなく、編集できるやつ。
私のPCには入ってないです。別に購入しても文句は言われませんが、月に数回しか使わないからもったいないと思う貧乏性です。
しかし、月に数回、PDFを加工(回転、抜粋、結合)したいことがあります。でもフリーのアプリをインストールするのもなんとなく気持ち悪いので、いまはChatGPTに書かせたPythonで編集しています。
ChatGPTにPDFをアップロードすれば、ChatGPT側で加工してもらうことも可能ですが、会社の資料はアップロードはできません。
よって、ここでは、ChatGPTにPythonのコードを書いてもらい、自分のPC上でPDF加工を完結させる方法を説明します。
PythonとJupyterのインストールはたくさん記事があるので、説明しません、自力でなんとかお願いします。
※ChatGPTは有料版を使ってますが、無料版やCopilot無料版でもできると思います(試行錯誤は必要かも)
(参考)PythonとJupyterのインストール方法
https://note.com/okapi1/n/n88490c4d4ff5
ChatGPTへPDFをアップロードする方法(参考)
まず、参考までにChatGPT(有料版)にPDFをアップロードして、加工してもらう方法です。

日本語での回答を指示しなかったので、英語での回答になってますが、リンクをダウンロードすると、10~12ページが抜粋されたファイルになってました。
これはChatGPT上でPythonコードが実行されており、赤線部分のView analysisで実際のコードを見ることができます。
ChatGPTでPythonコードを作成し、Jupyterで実行
ここからは、ファイルのアップロードができない場合を想定して、もう少し細かい指示をして、ChatGPTにPythonコードを書いてもらい、それをPCのJupyter上で実行します。
まず、pypdfというPDFを操作するモジュールを使用しますが、pypdfの使い方が書いてある以下のサイトを理解してもらうよう指示します。
これをすることで、作成されたコードのエラーが減りました。

次にコードを作成する指示を書きます。
PyPDF2で回答されることが多いのですが、PyPDF2は今後pypdfへ引き継がれるという記事があったので、今回はPyPDF2ではなく、pypdfを指定しています。
”加工前PDFの保存先”、”加工後のPDF保存先”は、自身の編集したいPDFが保存されているアドレスに変更してください。
(エクスプローラーのファイル上で"Shift+右クリック"→"パスのコピー")

回答されたコードが以下となります。
from pypdf import PdfReader, PdfWriter
# 加工前PDFのパス
input_pdf_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb.pdf"
# 加工後PDFの保存先パス
output_pdf_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb_加工後.pdf"
# PDFリーダーを作成してファイルを読み込む
reader = PdfReader(input_pdf_path)
writer = PdfWriter()
# すべてのページを右に90度回転
for page in reader.pages:
page.rotate(90) # 右に90度回転
writer.add_page(page)
# 加工後のPDFを保存
with open(output_pdf_path, 'wb') as out:
writer.write(out)これをこのままJupyterへ貼り付けて実行すると、PDFが全て90度回転された状態で保存できました。
加工前のPDFパス、加工後のPDFパスはよく確認してください。
\\が2重になってるのは、説明省略します。
\\とするか、パスの最初にrをつけてください。
path = 'C:\\Windows\\system32\\cmd.exe'
path = r'C:\Windows\system32\cmd.exe'
Pythonでエスケープシーケンスを無視(無効化)するraw文字列 | note.nkmk.me
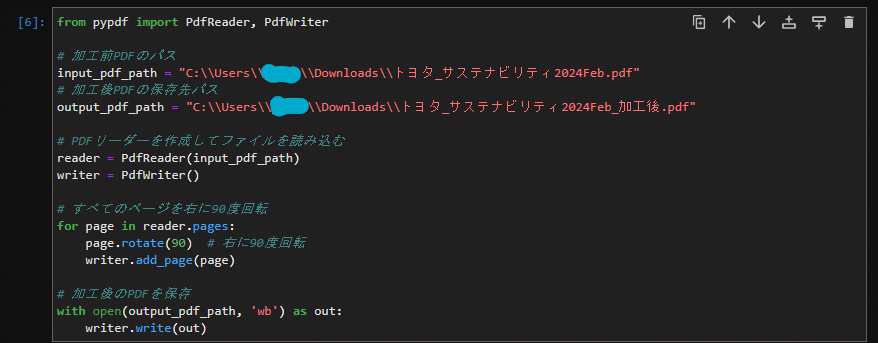
左に90度回転する場合は、"page.rotate(90) "の90を270へ変更するだけです。よって、回転であれば、このコードのみで対応できます。
次に特定ページの切り出しのコードを書いてもらいます。

from pypdf import PdfReader, PdfWriter
# 加工前PDFのパス
input_pdf_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb.pdf"
# 加工後PDFの保存先パス
output_pdf_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb_加工後.pdf"
reader = PdfReader(input_pdf_path)
writer = PdfWriter()
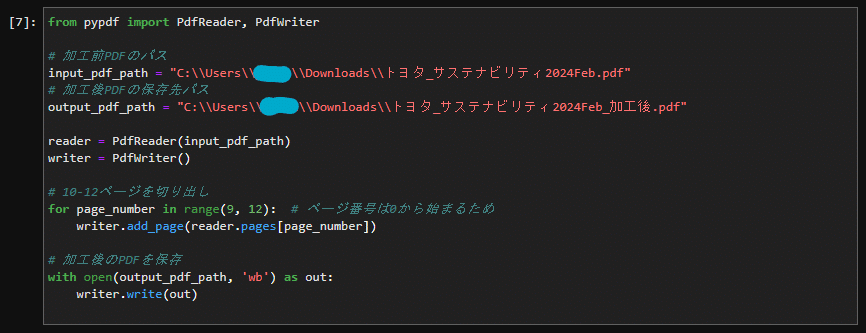
# 10-12ページを切り出し
for page_number in range(9, 12): # ページ番号は0から始まるため
writer.add_page(reader.pages[page_number])
# 加工後のPDFを保存
with open(output_pdf_path, 'wb') as out:
writer.write(out)これをJupyterにそのまま貼り付けて実行すると、10~12ページが切り出され、PDFファイルとして保存されました。
ページ番号はプログラム内では0から始まるので、プログラム内では9~11ページになります。しかし、range(9, 12)と、後ろが12となっているのは、Pythonで範囲を示す場合、後ろの数字は、その一つ前までを示すためです。
そういうものとして理解してもらうしかないです。ChatGPTに聞いた回答も載せておきます。
range()範囲の説明

次に分割するコードを聞きます。

from pypdf import PdfReader, PdfWriter
input_pdf_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb.pdf"
output_pdf_front_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb_加工後_前.pdf"
output_pdf_back_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb_加工後_後.pdf"
reader = PdfReader(input_pdf_path)
writer_front = PdfWriter()
writer_back = PdfWriter()
# 10ページ目で分割(ページ番号は0から始まるため、9が10ページ目)
for i, page in enumerate(reader.pages):
if i < 9: # 10ページ目より前
writer_front.add_page(page)
else: # 10ページ目以降
writer_back.add_page(page)
# 加工後のPDFを保存
with open(output_pdf_front_path, 'wb') as out_front:
writer_front.write(out_front)
with open(output_pdf_back_path, 'wb') as out_back:
writer_back.write(out_back)
このままJupyterに貼り付けて実行すると、ファイルが指定箇所で分割されて保存されました。
最後にPDFの結合です。
先程分割したファイルを結合してみます。

from pypdf import PdfReader, PdfWriter
# 加工前のPDFファイルパス
pdf1_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb_加工後_前.pdf"
pdf2_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb_加工後_後.pdf"
# 結合後のPDF保存先
output_pdf_path = "C:\\Users\\****\\Downloads\\トヨタ_サステナビリティ2024Feb_再結合.pdf"
# PdfWriterインスタンスを作成
writer = PdfWriter()
# 最初のPDFファイルを読み込み、ページを追加
reader1 = PdfReader(pdf1_path)
for page in reader1.pages:
writer.add_page(page)
# 2番目のPDFファイルを読み込み、ページを追加
reader2 = PdfReader(pdf2_path)
for page in reader2.pages:
writer.add_page(page)
# 結合したPDFを保存
with open(output_pdf_path, 'wb') as output_pdf:
writer.write(output_pdf)これらのコードをJupyterの各セルに貼り付け、ipynbファイルとして保存しておけば、だいたいのPDF加工は、このどれかで実行できます。
1ページごとに右90度、左90度なんかも指示すれば問題なくできます。
(両面印刷のスキャンを失敗したときとか)
調達系とは関係ない内容ですが、、
以上
この記事が気に入ったらサポートをしてみませんか?