
Azure AI Search(旧: Cognitive Search)のチャンク分割+ベクトル化でアナライザーを無理やり日本語にする!

Azure AI Searchで「チャンキング分割したベクトル化 + セマンティック」検索において2023年11月、現状のベストプラクティスだと思われる手法を記載しておきます。
事前準備
Azure Blob Storageの作成
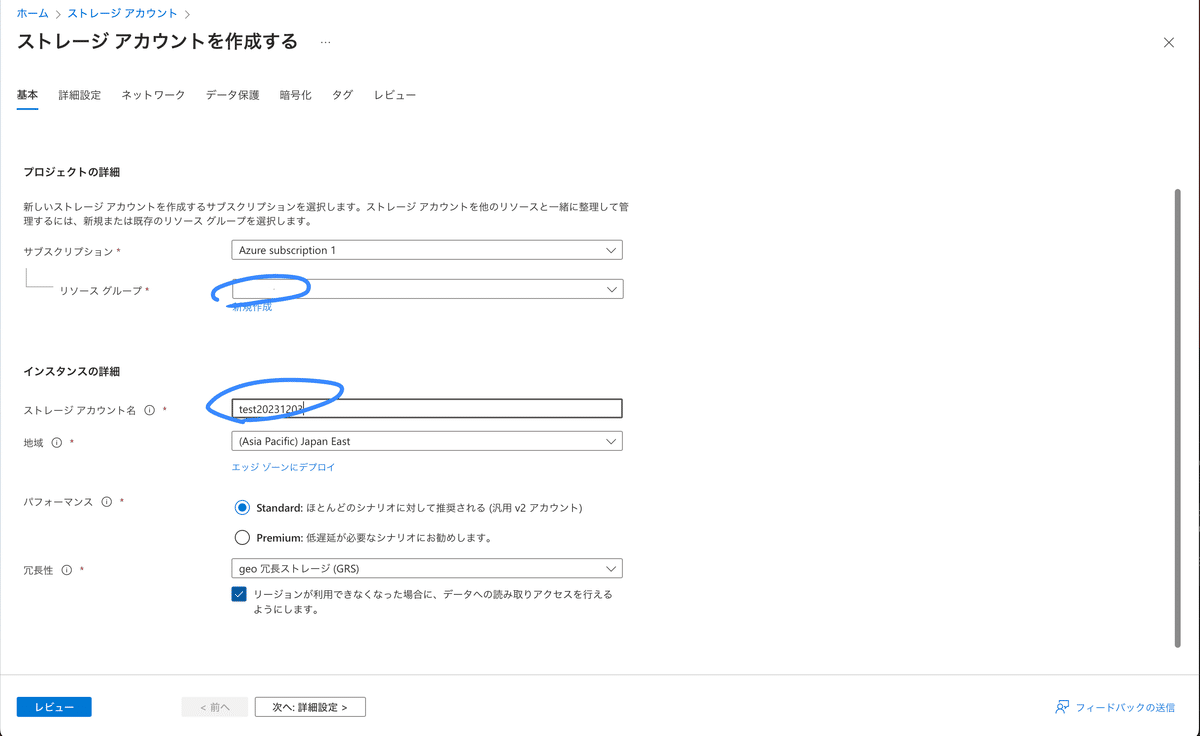
詳細設定の"階層型名前空間を有効にする"にチェックすることで、ファイルとディレクトリのセマンティクスが有効化され、ビッグ データ分析のワークロードが高速化され、アクセス制御リスト (ACL) が有効化されます。
制作したblobに入り、コンテナ(保存先のフォルダ)を作成後、ファイルのアップロードを行います。


AI Searchの作成
検索サービを作成
価格レベルの変更はbasicかstandardの悩ましい選択。



(費用は掛け算でアップします 涙)
インデックスの作成
作成したリソースに移動して概要にある"データのインポートとベクター化"からインデックスを作成します。


日本語の検索精度を上げるために、セマンティックランカーを有効にチェックしてから"レビューと作成"に進みインデックスを作成します。

20秒くらいでインデックスが作成されドキュメントがチャンク分割されて46レコード作成されました。

アナライザーを日本語にする(かなり無理やりです)
作成されたインデックスを開き、JSONの編集をクリック→メモ帳などにコピーします。

既存のインデックスはもう必要ないので削除。
インデックスの追加から"インデックスの追加(JSON)"を選択します。

最初に書かれているJSONを削除してから、先ほどメモ帳にコピーしたJSONをコピペで貼り付けます。

赤く警告されている行を削除していきます。
下の方にもあるのでここも削除。


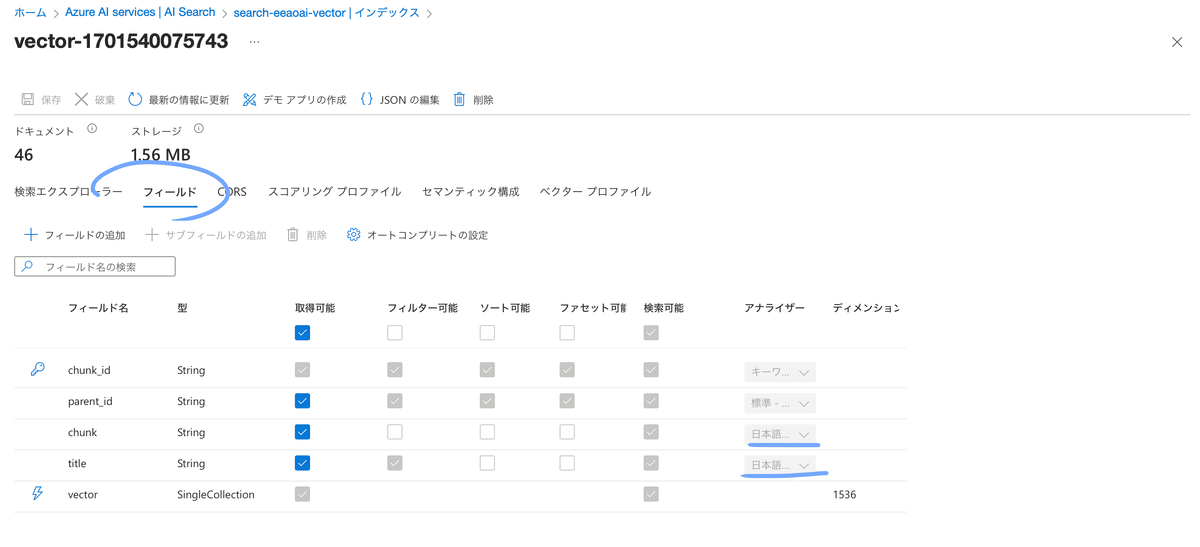
"chunk"フィールドと"title"フィールドのアナライザーを"null" → "ja.lucene"に変更して保存。

インデックスの画面で日本語のアナライザーになっているか確認します。
次にスキルセットへ移動。

「Microsoft.Skills.Text.SplitSkill」スキルの「defaultLanguageCode」を"ja"に変更します。(チャンクサイズは「maximumPageLength」オーバーラップは「pageOverlapLength」で数値の変更可能です)

インデクサーの再実行
インデクサーをクリックして中に入ります。

"リセット"をクリック
リセットされたら"実行"をクリック。

終わりに
Azure OpenAI on your data経由ではチャンクを日本語で作れなかったので、公式がGithubに用意してくれているデータ準備ツールなどを利用する必要がありました。コードを変更してリソースをBasicに変更すると色々エラーが出ちゃって2,3日ハマり続けましたが、23/11/16の大幅なアップデートでチャンキング+ベクトル化機能がプレビュー版としてAzure AI Searchに統合されてたのでドキュメント解説をGPTにお願いしながら何とかできました。やっぱり公式のドキュメントがベストプラクティスですね!(ドキュメントがわかりにくすぎて途中なんど挫折しかけたか...OpenAiを見習って欲しいよ)
この記事が気に入ったらサポートをしてみませんか?