OpenAI Dev Dayで発表されたOpenAI TTS(Text to Speech)を試してみた!

OpenAI Dev Day、期待を超えてきましたね。淡々とすごい発表がありましたが、その一つにTTSのAPI公開がありました。これを早速試してみました。
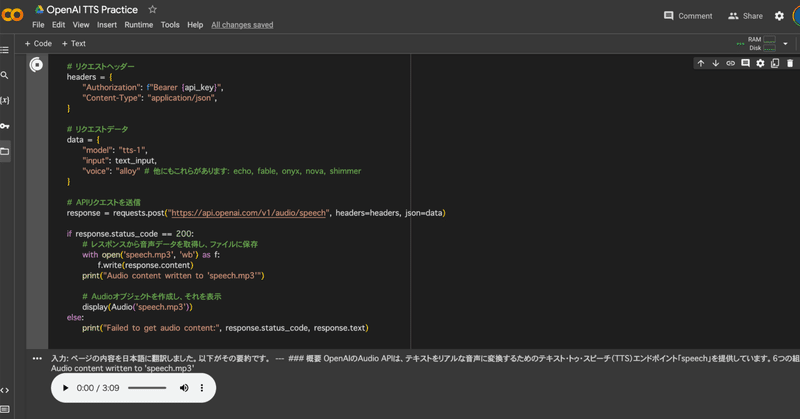
以下にColabを作成しましたので、API Keyさえあればすぐ試せます!
以下、但し書き
StreamingはColabでは実装できなさそうだったので、一旦普通のTTSのみ対応してます
Pythonのopenaiパッケージ(v1.0.1)はまだバージョンが対応していないのか実装エラーが出ましたので、requestsを使ってそのままAPIリクエストを行っています
追記: openai(v1.1.0)がリリースされましたので、以下にpython-openaiを使ったコードを実装しています。
公式ドキュメントの翻訳
概要
OpenAIのAudio APIは、テキストをリアルな音声に変換するためのテキスト・トゥ・スピーチ(TTS)エンドポイント「speech」を提供しています。6つの組み込みボイスがあり、以下のような用途に使用できます。
書かれたブログ投稿のナレーション
複数言語での音声コンテンツの生成
ストリーミングを使用したリアルタイム音声出力
AI生成のTTSボイスを使用する際は、エンドユーザーに対してAIが生成した音声であることを明確に開示する必要があります。
クイックスタート
`speech` エンドポイントは、モデル名、音声に変換するテキスト、および音声生成に使用するボイスの3つの主要な入力を受け取ります。簡単なリクエストの例を以下に示します。
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)音声品質
リアルタイムアプリケーションの場合、標準の`tts-1`モデルは最低の遅延を提供しますが、`tts-1-hd`モデルに比べて品質は低くなります。音声は状況によっては`tts-1-hd`よりも多くのノイズを含む可能性があります。
ボイスオプション
異なるボイス(alloy, echo, fable, onyx, nova, shimmer)を試して、望むトーンと聴衆に合ったものを見つけてください。デフォルトのボイスはalloyです。
サポートされている出力フォーマット
デフォルトの応答フォーマットは「mp3」ですが、「opus」、「aac」、「flac」などの他のフォーマットも利用可能です。
リアルタイム音声のストリーミング
Speech APIは、チャンク転送エンコーディングを使用したリアルタイム音声ストリーミングをサポートしています。これにより、完全なファイルが生成されてアクセス可能になる前に音声を再生することができます。
FAQ
生成された音声の感情の範囲をどのように制御できますか?
音声の感情的な出力を直接制御するメカニズムはありません。大文字や文法などの要素が出力音声に影響を与える可能性がありますが、これらを使用した内部テストでは混在した結果が得られています。
自分の声のカスタムコピーを作成することはできますか?
いいえ、これはサポートしていません。
出力された音声ファイルを所有することはできますか?
はい、APIからのすべての出力と同様に、それを作成した人が出力を所有します。ただし、エンドユーザーにAIによって生成された音声であることを通知する必要があります。
価格
TTS: 1,000文字あたり$0.015
TTS HD: 1,000文字あたり$0.030

感想
本当にサクっと試せて良いです。Eleven LabsなどのTTSサービスでは漢字が混じると中国語の発音になってしまうなどがありましたが、こちらはありませんでした。違和感は少し伴うものの、情報を伝えるコミュニケーションとしては十分に活用ができそうです。
日本語ネイティブの発音ではなく、どちらかというと日本語がめちゃくちゃ上手い外国の方の発音に近い気がします。
処理速度も結構早いです。どれくらいのテキスト量まで試せるのか、そこの制約については見つけられなかったので、見つかったら追記します。
この記事が気に入ったらサポートをしてみませんか?