ChatVRMのバックエンドとしてLangChain(とFastAPI)を使う

ChatVRM
PixivさんがChatVRMという素晴らしいアプリケーションを公開してくれました。ブラウザ上でVRMモデルを表示し、Koeiro APIによる文章読み上げや、感情表現をしてくれます。MITライセンスなので、改変などもしやすそうです。
ChatVRMでは、以下のようにOpenAIのChat Completion APIを直接叩いてキャラクターの返答を生成しています。stream: trueとすると、SSE (Server-Sent Events)というものを使って順次生成された情報を返してくれます。ChatGPTで文章が少しずつ表示されていくアレです。
const res = await fetch("https://api.openai.com/v1/chat/completions", {
headers: headers,
method: "POST",
body: JSON.stringify({
model: openAiModel,
messages: messages,
stream: true,
max_tokens: 200,
}),
});やりたいこと
シンプルにメッセージを送って会話するだけなら十分ですが、出来ることなら、LangChainなどと組み合わせて、履歴・記憶面の対応や外部情報の参照を可能にしたくなってきます。
以前の記事(↓)で「返答に合わせて3Dモデルを動かしたい」なんてことを書きましたが、うまくいけばこれで対応できそうです。
ということで、LangCahinとFastAPIを使って、ChatVRMのバックエンドとして使えるAPIの作成を試みました。
※ JS/TS版のLangChainもあるようですが、フロントにあれこれ詰め込みたくないことと、TypeScriptが全然分からない。
API(LangChain×FastAPI)の実装
私のTypeScriptの知識に問題があるので、フロント側で新たな受信処理などを考えなくて済むように、OpenAIと同じような形式でSSE (Server-Sent Events)でレスポンスを返すようにしました。
ChatVRMからmessagesを受け取って、ユーザのメッセージ、システムメッセージ、会話履歴(LangchainのChatMessageHistoryの形式に変換)に分割して扱っています。履歴などはChatVRM依存ですが、とりあえず動きます。
# langchain_sse.py
import asyncio
import json
from typing import Any, Dict, List, Union, Optional
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from sse_starlette.sse import EventSourceResponse
from langchain.callbacks import AsyncIteratorCallbackHandler
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
)
from langchain.schema import messages_from_dict
import dotenv
dotenv.load_dotenv()
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class ChatRequest(BaseModel):
messages: List[Dict[str, str]]
temperature: Optional[float] = 0.7
model: Optional[str] = "gpt-3.5-turbo"
timeout: Optional[float] = 60.0
class CustomAsyncIteratorCallbackHandler(AsyncIteratorCallbackHandler):
async def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
self.queue.put_nowait(json.dumps({
"choices": [{"delta": {"content": token}}],
}))
def convert_messages(messages: List[Dict[str, str]]) -> List[Dict[str, Union[str, Dict[str, Any]]]]:
# Converts a list of chat messages from a chatcompletion format to a LangChain format.
return [
{
"type": "human" if item["role"] == "user" else "ai",
"data": {
"content": item["content"],
"additional_kwargs": {},
},
}
for item in messages
]
async def start_llm(stream_handler: CustomAsyncIteratorCallbackHandler, request: ChatRequest) -> None:
chat = ChatOpenAI(
temperature=request.temperature,
streaming=True,
model=request.model,
request_timeout=request.timeout
)
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(request.messages[0]["content"]),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
conversation = ConversationChain(
llm=chat,
memory=ConversationBufferMemory(return_messages=True),
prompt=prompt
)
conversation.memory.chat_memory.messages = messages_from_dict(convert_messages(request.messages[1:-1]))
await conversation.apredict(input=request.messages[-1]["content"], callbacks=[stream_handler])
@app.post("/chat")
async def chat(request: ChatRequest) -> EventSourceResponse:
stream_handler = CustomAsyncIteratorCallbackHandler()
asyncio.create_task(start_llm(stream_handler, request))
async def event_generator(acallback: CustomAsyncIteratorCallbackHandler):
ait = acallback.aiter()
async for token in ait:
yield token
yield "[DONE]"
return EventSourceResponse(event_generator(stream_handler))
これに機能を追加していくことで、いろいろな返答の生成が可能になると思います。
※ リポジトリのtestディレクトリ内では、API側での会話履歴管理等も試行中。
実装では以下のDiscussionsを参考にしました。
試行錯誤とChatGPTの助けでとりあえず動いたは良いものの、非同期処理が絡むと知識不足ゆえに理解が難しいです。どのように動いているかはまだ十分に理解できていません。
フロント(ChatVRM)側の実装
ChatVRMを改変します。私は、以下を行いました。
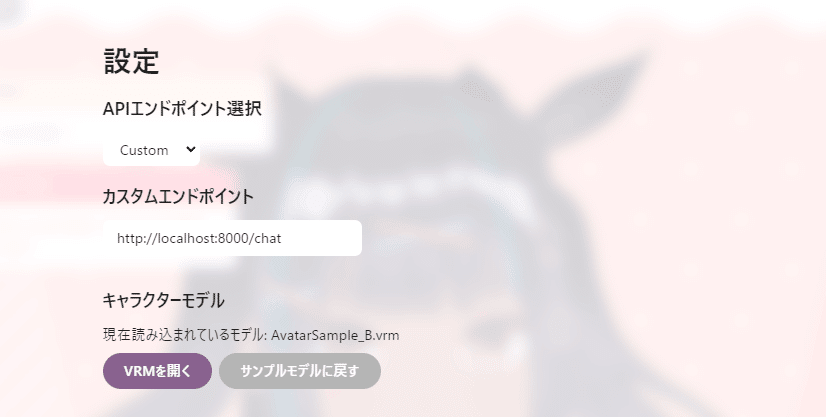
・メニュー画面にAPIのURL指定を追加(OpenAI⇔Customで切り替え)
index.tsx, menu.tsx, settings.tsxなどを編集
・指定したURLをたたく関数を別途作成
APIのURLと、渡すパラメータの数以外はopenAiChat.tsのgetChatResponseStream関数とほぼ共通なので、直接書き換えてもたぶん動きます。
// langChainChat.ts
import { Message } from "../messages/messages";
export async function getChatResponseStreamLangChain(
messages: Message[],
customApiEndpoint: string
) {
const headers: Record<string, string> = {
"Content-Type": "application/json"
};
const res = await fetch(customApiEndpoint, {
headers: headers,
method: "POST",
body: JSON.stringify({
messages: messages,
}),
});
const reader = res.body?.getReader();
if (res.status !== 200 || !reader) {
throw new Error("Something went wrong");
}
const stream = new ReadableStream({
async start(controller: ReadableStreamDefaultController) {
const decoder = new TextDecoder("utf-8");
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
const data = decoder.decode(value);
const chunks = data
.split("data:")
.filter((val) => !!val && val.trim() !== "[DONE]");
for (const chunk of chunks) {
const json = JSON.parse(chunk);
const messagePiece = json.choices[0].delta.content;
if (!!messagePiece) {
controller.enqueue(messagePiece);
}
}
}
} catch (error) {
controller.error(error);
} finally {
reader.releaseLock();
controller.close();
}
},
});
return stream;
}
この記事が気に入ったらサポートをしてみませんか?