
高度な音声モード こと Realtime API を試してみる

こんにちは、ニケです。
皆さん、ChatGPTの高度な音声モードは試されしたでしょうか?
10/4現在、ChatGPTアプリを持ってる方なら無料プランでも使用できるらしいのでまだの方はぜひ試してみましょう(無料プランは上限あり)。
かなり体験の良いAIとの対話が楽しめるはずです。
その熱も冷め止らぬうち、10/2 OpenAI DevDayでついにそのAPI版が発表されました。
その名も Realtime API。
これで自前のアプリに高度な音声モードライクな機能を実装することができます。
心待ちにしていたエンジニアの方も多いでしょう。
そこで今回は Realtime API について、公式のサンプルコードを基に簡単に使い方を解説していきたいと思います。
⚠ Realtime APIでは Function Callingも使用できますが、執筆時点で私が理解できていないので説明を省きます。
公式ガイド
https://platform.openai.com/docs/guides/realtime
APIドキュメント
https://platform.openai.com/docs/api-reference/realtime-client-events
Realtime APIとは
Realtime APIの何がすごいのかを説明します。
従来のAIチャットボットでは、主に下記のような流れで処理が進んでいました。
ユーザーが音声で話しかける
音声を文字起こししてテキストにする
テキストをAIに渡してテキストで回答を得る
テキストを音声に変換して再生する
Realtime APIでは、音声での読み込みと音声での返答が可能です。
つまり、
ユーザーが音声で話しかける
音声をAIに渡して音声で回答を得る
このようにテキストの仲介がなくなるため、ユーザーの質問からAIの返答までの遅延を少なくすることが可能になります。
また、音声をそのままAIに渡すことにより、抑揚などのニュアンスを理解した回答を得ることもでき、その出力された回答自体にも感情表現を乗せることが可能です。
※ ちなみに音声だけでなく、Realtime APIは従来通りのテキストベースでやり取りすることも可能です。
WebSocket
Realtime APIはWebSocketを介して、OpenAIサーバーとやり取りすることでこれらの機能を実現しています。
WebSocketは、ウェブブラウザなどのクライアントとサーバー間でリアルタイムの双方向通信を可能にする技術です。
一般的なHTTP通信と異なり、接続を一度確立すると、クライアントとサーバーが自由にデータを送受信することが可能です。
これにより、チャットアプリやリアルタイムゲームなど、即時性が求められるアプリケーションで利用されることが多いです。
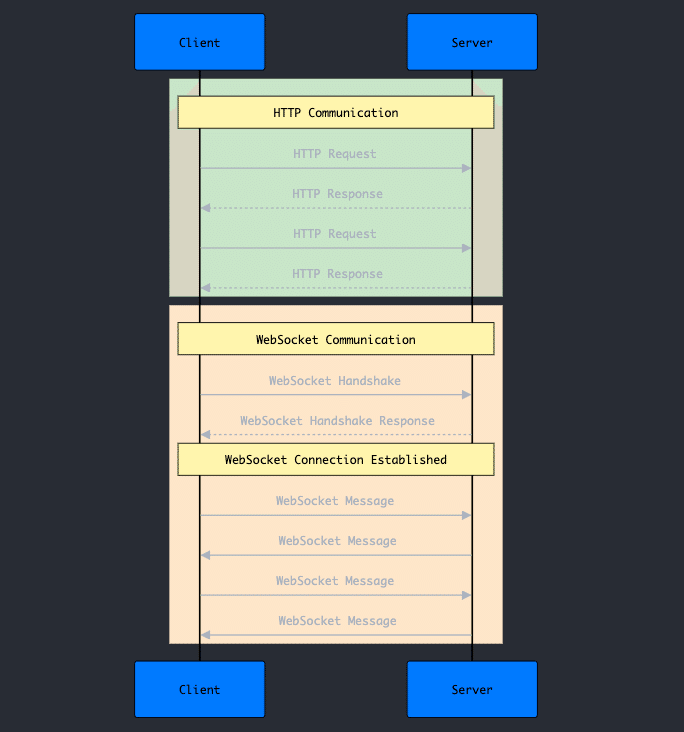
WebSocketでは、まずクライアントからサーバーにリクエストを投げてサーバーはそれにリクエストを返します。
一見通常のHTTPと同じですが、このときにクライアントとサーバーの接続が確立されるのがWebSocketです(ハンドシェイク通信と呼びます)。
接続が完了したらクライアントからもサーバーからも自由に送信することができます。
Realtime APIを使う場合は、我々エンジニアが作るアプリがクライアントで、サーバーはOpenAIのサーバーになるかと思います。
コード解説
では、早速使い方を見ていきましょう。
以降はOpenAI公式ドキュメントのサンプルコードを多用します。
私の解説で不十分な場合や、もっと知りたくなった場合はぜひ公式ドキュメントを読んでください。
なお、サンプルコードがJavaScriptで書かれているため、解説もそれを元に行っていきます。
接続を確立する
まずはOpenAIサーバーと接続を確立します。
import WebSocket from "ws";
const url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01";
const ws = new WebSocket(url, {
headers: {
"Authorization": "Bearer " + process.env.OPENAI_API_KEY,
"OpenAI-Beta": "realtime=v1",
},
});
ws.on("open", function open() {
console.log("Connected to server.");
ws.send(JSON.stringify({
type: "response.create",
response: {
modalities: ["text"],
instructions: "Please assist the user.",
}
}));
});
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});wsという変数にWebSocketクラスのインスタンスを格納しています。
以降はこのws変数を利用してWebSocket関連の処理を進めていきます。
ws.on("open", function open() {このように、ws.on で始まっているのがイベントリスナーの設定です。WebSocketオブジェクトには様々なイベントが存在し、それぞれのイベントに対して特定の処理を行うことができます。
この例では、"open"(接続時)と"message"(リクエスト受信時)という2つのイベントに対してリスナーを設定していますが、他にも、"error"(エラー発生時)や"close"(接続が閉じられたとき)などのイベントがあり、必要に応じてリスナーを追加することができます。
これらのイベントリスナーを適切に設定することで、WebSocketを使用した双方向通信を効果的に管理することができます。
サーバーにリクエストを送る
"open"のときの処理に注目すると、ws.send という処理があるのがわかると思います。
ws.on("open", function open() {
console.log("Connected to server.");
ws.send(JSON.stringify({
type: "response.create",
response: {
modalities: ["text"],
instructions: "Please assist the user.",
}
}));
});これがサーバーにリクエストを送るときの処理です。
Realtime APIでは、JSON形式でtypeキーを指定して送信するのが基本になります。
この場合は "response.create" というタイプの送信をしていますね。
これは「これまでの処理に従って応答を作成してください。」という命令です。
今回はWebSocketの接続が "open" したときに、応答形式(modalities)がテキストで、システムプロンプト(instructions)が "Please assist the user." の応答を返してください、といった命令を投げています。
※ ちなみにこれは、いわばシステムプロンプトだけ設定してユーザーインプット空文字で送っているようなものなので、あまり良い例だとは思いません。
"response.create" のようなタイプが全部で9種類あって、それらを使い分けてサーバーに様々な命令を送ることになります。
他の例も見てみましょう。
const event = {
type: 'conversation.item.create',
item: {
type: 'message',
role: 'user',
content: [
{
type: 'input_audio',
audio: base64AudioData
}
]
}
};
ws.send(JSON.stringify(event));
ws.send(JSON.stringify({type: 'response.create'}));ここでは、"response.create" の前に "conversation.item.create" というタイプのリクエストを送っていますね。
これはOpenAIサーバーに対してアイテム(ここでは会話の中身という意味で理解してください)を送っています。
今回の場合は、base64形式の音声データを送信しています。
ちなみにテキストデータも同じようにアイテムとして送信することが可能です。
その直後に "response.create" を送っていますが、先ほど説明したようにこれは「これまでの処理に従って応答を作成してください。」という命令なので、送信した音声データを理解した上でクライアントに回答を返すようにリクエストを送っています。
もう一つ見てみましょう。
const files = [
'./path/to/sample1.wav',
'./path/to/sample2.wav',
'./path/to/sample3.wav'
];
for (const filename of files) {
const audioFile = fs.readFileSync(filename);
const audioBuffer = await decodeAudio(audioFile);
const channelData = audioBuffer.getChannelData(0);
const base64Chunk = base64EncodeAudio(channelData);
ws.send(JSON.stringify({
type: 'input_audio_buffer.append',
audio: base64Chunk
}));
});
ws.send(JSON.stringify({type: 'input_audio_buffer.commit'}));
ws.send(JSON.stringify({type: 'response.create'}));今回は音声ファイル3つを1つずつ "input_audio_buffer.append" で送っていますね。
これはユーザーが喋った音声をストリーミングで送信したというのを現した例です。
音声データをサーバーに送る方法はいくつかありますが、このように小さいデータ単位で送るというのはよくある手法です。
"input_audio_buffer.append" という命令は、「音声データをたくさん送るのでサーバー側で結合しておいてね」という意味だと思ってもらえればよいです。
これでサーバー側で良しなに意味がつながるようにつなぎ合わせておいてくれます。
次に、"input_audio_buffer.commit" を送っていますが、これは「今まで送った音声データを確定してユーザーメッセージとして保存しておいてね」という命令です。
最後に "response.create" を送信してAIの回答生成を促しています。
サーバーからレスポンスを受け取る
では次にOpenAIのサーバーから返ってきたデータを処理する方法を説明します。
最初に提示したコードの中に以下のような記述がありました。
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});これはサーバーからのレスポンスを受け取ったときのイベントリスナーで、Realtime APIの回答もすべてこの方式で取得できます。
リクエストにもタイプが存在します。なんと28種類。リクエストの4倍、多い。
全てが必要なわけではないので欲しい情報だけ処理するようにしましょう。
例えば下記のようなものがあります。
response.created
{
"event_id": "event_2930",
"type": "response.created",
"response": {
"id": "resp_001",
"object": "realtime.response",
"status": "in_progress",
"status_details": null,
"output": [],
"usage": null
}
}これは "response.created" というタイプのレスポンスです。先程たくさん出てきた "response.create" 実行後に返ってくるレスポンスです。
これは「レスポンスを作り始めたよ」という意味の回答なのでこれ自体に意味のある内容は含まれていません。
response.done
{
"event_id": "event_3132",
"type": "response.done",
"response": {
"id": "resp_001",
"object": "realtime.response",
"status": "completed",
"status_details": null,
"output": [
{
"id": "msg_006",
"object": "realtime.item",
"type": "message",
"status": "completed",
"role": "assistant",
"content": [
{
"type": "text",
"text": "Sure, how can I assist you today?"
}
]
}
],
"usage": {
"total_tokens": 50,
"input_tokens": 20,
"output_tokens": 30
}
}
}これは回答がすべて終わったときに返ってくるレスポンスです。
ストリーミングだと細かくテキストや音声データを返答する事があるのでそのまとめみないなものですね。
最終的にどのような文章を送ったのかや、どれくらいのトークン数だったのかを教えてくれます。
response.audio_transcript.delta
{
"event_id": "event_4546",
"type": "response.audio_transcript.delta",
"response_id": "resp_001",
"item_id": "msg_008",
"output_index": 0,
"content_index": 0,
"delta": "Hello, how can I a"
}ストリーミングが返ってきた場合のレスポンスがこれです。
見てわかるようにテキストが中途半端に返却されていますね。
上述した2つの丁度間に返ってくるレスポンスのタイプになります。
実際にはこのようなデータを逐一処理して、リアルタイムに画面に文字を表示していくのが最近のアプリの主流になるかなと思います。
response.audio.delta
{
"event_id": "event_4950",
"type": "response.audio.delta",
"response_id": "resp_001",
"item_id": "msg_008",
"output_index": 0,
"content_index": 0,
"delta": "Base64EncodedAudioDelta"
}こちらは音声データバージョンです。
指定すればテキストと音声の両方のリクエストを受け取ることができるので、画面に文字を表示させて音声も再生させる、みたいなこともできます。
実際に触ってみる
以下のリポジトリがかなりわかり易いので、こちらを使って実際に Realtime API を体験してみましょう。
環境構築
READMEにも親切に書いてありますが念の為。
# githunからクローン
git clone https://github.com/openai/openai-realtime-console.git
# フォルダ移動
cd openai-realtime-console
# ライブラリインストール
npm i
# デモサーバー起動
npm run devこの状態で localhost:3000 にアクセスしてください。
最初にOpenAIのAPIキーが求められると思うのでそれを入力したら準備は完了です。
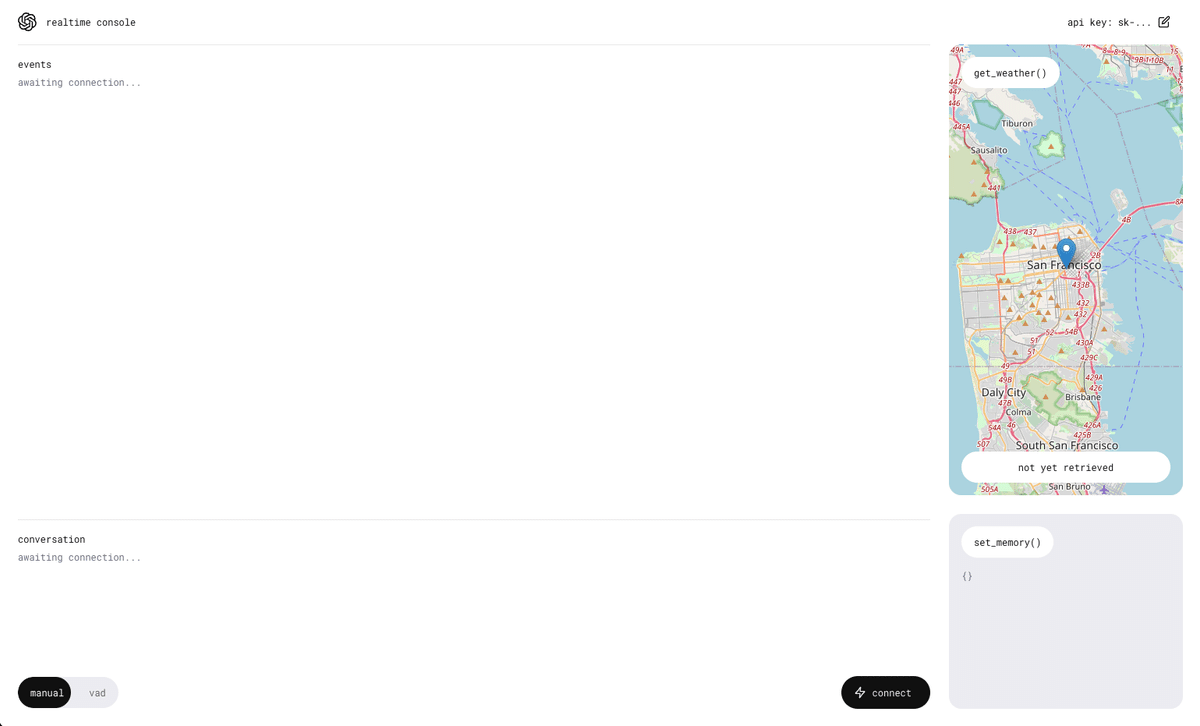
試してみる
それでは右下の「connect」ボタンを押してみましょう。
するといきなり話しかけられると思います。

色々とログが出てきたので見てみましょう。
clientとserverに分かれていますね。
実はこれ、先程説明したそれぞれのタイプが列挙されています。
クリックするとどのようなリクエストを送信して、どのようなリクエストが送られてきたのか見えるはずです。
良くでてきた "response.create" と "response.created" のペアもちゃんとありますね。
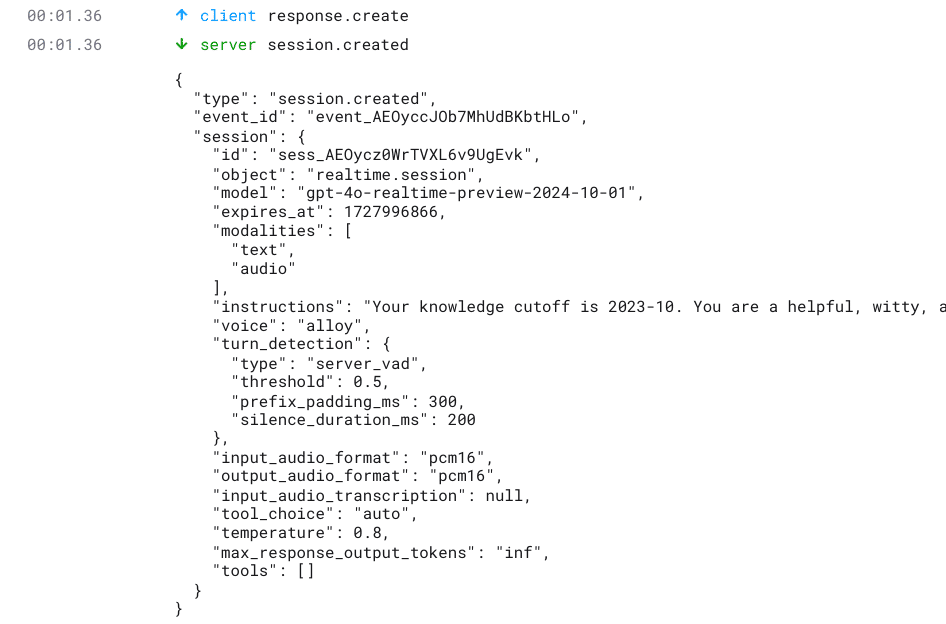
これらを確認することで、Realtime APIを使ったアプリを作成するときの参考になるはずです。
今回は説明しきれなかった、Function Callingの機能も入っているので、ぜひ試して確認してみてください。
使用上の注意
Realtime APIはベータ版として公開されており、まだ完全な機能が出揃っていません。
音声モデルの選択肢が少なかったり、過去の履歴を簡単に制御できないなどの問題が残っています。
特に後者の過去の会話歴の制御については、MAXトークン数をあらかじめ決めておくみたいなことができず、何も考慮しないとダルマ式にトークン量が増えていくトラップが潜在していたりします。
ので、そのまま会話し続けるとレスポンスが遅くなったり、気づかぬうちに大量の請求が来てしまう可能性もあります。
会話アイテム(テキストや音声データ)のIDを指定することで、1つずつ削除することができるリクエスト "conversation.item.delete" があるので、必要に応じて使用するのも良いでしょう。
また、会話歴はWebSocketのセッション毎に保持されるので、会話が数秒続かなかったらセッションを切り、再開したら新しく接続し直すなどの処理を入れることも一つの方法かと思います。
初期のAssistants APIで起こった事件に関してはこちらから。
終わりに
以上、OpenAIのRealtime APIについて、その特徴や使用方法、そして実際に試してみる方法までを解説しました。
Realtime APIは、リアルタイムの音声対話やテキストチャットを可能にする革新的な技術で、AIとのインタラクションをより自然で即時的なものにします。
ぜひ、紹介したOpenAIのデモリポジトリを使って、実際にRealtime APIを体験してみてください。
APIの動作を理解し、各種イベントやレスポンスを確認することで、ご自身のプロジェクトでの活用方法がより明確になるはずです。
宣伝
AITuberKitという誰でも簡単にAIキャラチャット、AITuber開発ができるOSSを開発しています。
まだ未実装ですが、Realtime API も追加して、より低遅延で自然な会話ができるAIチャットを実現する予定です。
興味のある方はぜひ試していただけると嬉しいです!

いいなと思ったら応援しよう!
