Langchain Indexes機能について

始めに
本日はLngchainの6つの機能のうちの1つであるIndexesについて解説していきます。
Langchain Indexesとは
Langchain ③Indexesは、PDFやCSVなどの外部データを用いて回答を生成しています。例えば、ローカルにあるPDFを用いてチャットボットを作りたいときなどに利用できます。ローカル環境で作成することで、秘密情報をオープンAI以外のサーバーに送信しなくても使えるチャットボットの作成が可能となります。
Langchain Indexesの主な機能
ラングチェーンインデックスの機能は主に以下の4つ存在します。
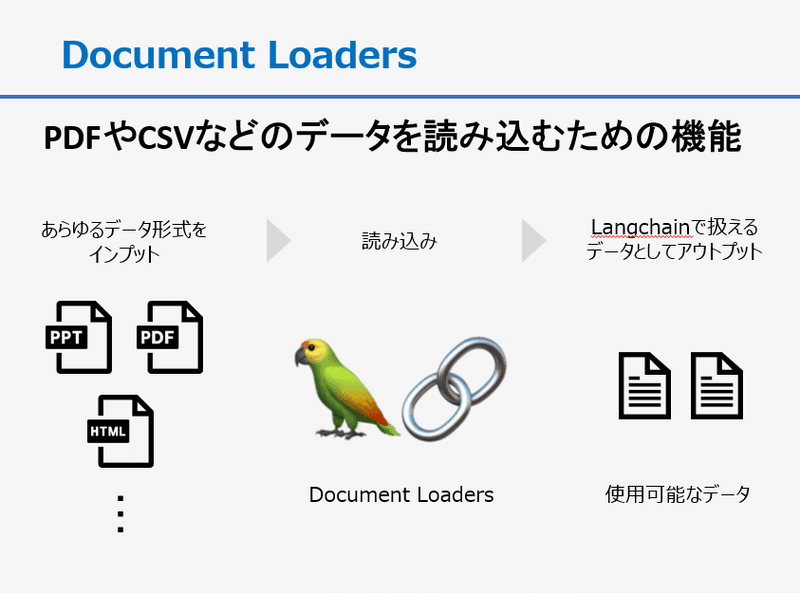
1. Document Loaders
Document LoadersはPDFやCSVなどのデータを読み込むための機能です。パワーポイント、ワード、HTML、マークダウン、Eメール、URLなども読み込むことが可能です。さらに、notion、figma、Evernote、Googleドライブ、スラック、YouTubeなどのサービスとも利用可能で、クラウド関連サービス(Azure、GCP、AWSなど)との連携も可能です。
2. Text Splitters
Text Splittersは文章データを分割する機能です。単純な文章だけでなく、マークダウンやPythonのコードも分割することができます。また、トークン数で分割することもでき、フロントのトークン数を制御する際にも便利です。

3. Vectorstores
Vectorstoresは、エンべディング(ベクトル化)されたデータを管理する機能です。この機能を用いて自然言語のデータを管理することができます。
4. Retrievers
Retrieversはドキュメント検索をするための機能です。長い文章を複数のドキュメントという塊に分割し、その中からプロントと関連のある情報が入ったドキュメントを検索することができます。
Pythonを用いた具体的な実装方法
環境構築
ラングチェインを用いるためには、まずpip install langchainを実行してインストールします。
!pip3 install langchain openaiまた、OpenAIのモデルを用いるためにはpip install openaiを実行します。ライブラリのインストールが完了したら、OpenAIのAPIキーを設定します。
import os
os.environ["OPENAI_API_KEY"] = "your openai_API_key"1. Document Loadersの使い方
PDFファイルを読み込み、質問するという流れで説明します。
ここではパッケージ「pypdf、tiktoken、chromadb」が必要となるため、インストールしましょう。
!pip3 install pypdf tiktoken chromadbインストール後はPDFを読み込みます。
今回はPyPDFLoaderというライブラリを使って、令和4年版「防衛白書」のPDFをURLから読み込みます
そして、この後説明するvectorstoresというモジュールの中のChromaというツールを使って、『北朝鮮の動向について教えて。』と検索しています。
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
loader = PyPDFLoader("https://www.mod.go.jp/j/press/wp/wp2022/pdf/wp2022_JP_Full_01.pdf")
pages = loader.load_and_split()
print(pages[0])
chroma_index = Chroma.from_documents(pages, OpenAIEmbeddings())
docs = chroma_index.similarity_search("「北朝鮮の動向について教えて。", k=2)
for doc in docs:
print(str(doc.metadata["page"]) + ":", doc.page_content)
これに対する実行結果は次の通りです。以下がその出力結果です。
page_content='防衛2022_00_本冊表紙.indd 3防衛2022_00_本冊表紙.indd 3 2022/06/16 15:25:402022/06/16 15:25:40' metadata={'source': '/tmp/tmp_8u0l6ul/tmp.pdf', 'page': 0}
88: いるほか、 累次にわたり核武力の強化に言及するな
ど、 国際社会に背を向けて核・弾道ミサイル開発の
ための活動を継続する姿勢を依然として崩していな
いのみならず、 さらなる挑発行動に出る可能性も考
えられ、 こうした傾向は近年より一層強まっている。
北朝鮮の核兵器保有が認められないことは当然
であるが、 同時に、 弾道ミサイルなどの開発・配備
の動きや朝鮮半島における軍事的対峙、 北朝鮮によ
る大量破壊兵器やミサイルの拡散の動きなどにも注
目する必要がある。
その閉鎖的な体制などから、 北朝鮮の動向の詳細
や意図の明確な把握は困難だが、 わが国として強い
関心を持って注視していく必要がある。 また、 拉致
問題については、 引き続き、 米国をはじめとする関
係国と緊密に連携し、 一日も早い全ての拉致被害者
の帰国を実現すべく、 全力を尽くしていく。
2 軍事態勢
(1) 全般
北朝鮮は、 全軍の幹部化、 全軍の近代化、 全人民
の武装化、 全土の要塞化という四大軍事路線4に基
づいて軍事力を増強してきた。
北朝鮮軍は、 冷戦構造の崩壊による旧ソ連圏から
の軍事援助の減少や経済低迷による国防支出の限
界、 韓国の防衛力の近代化といった要因により、 韓
国軍及び在韓米軍に対して通常戦力の著しい質的格
差がみられ、 その装備の多くは旧式である。 一方、
北朝鮮の総兵力は陸軍を中心とした約128万人で
あり、 DMZ付近に展開する砲兵部隊を含め、 依然
として大規模な軍事力を維持している。
さらに、 北朝鮮は、 体制を維持するため、 大量破
壊兵器や弾道ミサイルなどの増強に集中的に取り組
むことで、 独自の核抑止力構築や、 米韓両軍との紛
争における対処能力の向上を企図していると考えら
れる。 特に、 2019年5月以降、 低空を変則的な軌道
で飛翔することが可能な新型の短距離弾道ミサイル
4 1962年に朝鮮労働党中央委員会第4期第5回総会で採択された。
5 例えば、 2021年1月の朝鮮労働党第8回大会において、 金正恩委員長は 「現代戦において作戦任務の目的と打撃対象に応じ様々な手段で適用することの
できる戦術核兵器を開発」 する、 「朝鮮半島地域における各種の軍事的脅威を、 主動性を維持しつつ徹底的に抑止して統制、 管理する」 と表明している。(SRBM) などを繰り返し発射し、 急速にミサイル関
連技術や運用能力の向上を図っており、 その発射態
様も鉄道発射型や潜水艦発射型など多様化させつ
つ、 より実戦的なSRBM戦力の拡充に努めていると
みられる。 また、 近年では長距離巡航ミサイルの実
用化も追求しているほか、 2022年4月17日には、
「戦術核運用の効果性」 を強化するなどとして、 「新
型戦術誘導兵器」 と称するミサイルを発射した旨発
表した。 一連の開発・発射の背景には、 体制維持・
生存のため、 核兵器及び長射程弾道ミサイルの保有
による核抑止力の獲得に加え、 米韓両軍との間で発
生し得る通常戦力や戦術核を用いた武力紛争におい
ても対処可能な手段を獲得するという狙いがある可
能性も考えられる5。 北朝鮮は、 2021年1月の党大
会において 「国防科学発展及び武器体系開発5か年
計画」 という計画が示されたことを累次にわたって
明らかにしており、 引き続きこれに沿って各種兵器
の開発に注力していくものとみられる。
加えて、 北朝鮮は情報収集や破壊工作などに従事
する大規模な特殊部隊などを保有している。 さらに、
北朝鮮の全土にわたって多くの軍事関連の地下施設
が存在するとみられていることも、 特徴の一つであ
る。
(2) 軍事力
陸上戦力は、 約110万人を擁し、 兵力の約3分の
2をDMZ付近に展開しているとみられる。 その戦
力は歩兵が中心だが、 戦車3,500両以上を含む機甲
戦力と火砲を有し、 また、 240mm多連装ロケット
や170mm自走砲といった長射程火砲をDMZ沿い
に配備していると考えられ、 ソウルを含む韓国北部
の都市・拠点などが射程に入っている。
海上戦力は、 約800隻、 約11万トンの艦艇を有す
るが、 ミサイル高速艇などの小型艦艇が主体である。
また、 旧式のロメオ級潜水艦約20隻のほか、 特殊部
隊の潜入などに用いるとみられる小型潜水艦約40
隻とエアクッション揚陸艇約140隻を有している。
79 令和4年版 防衛白書
わが国を取り巻く安全保障環境 第Ⅰ部
諸外国の防衛政策など
第3章
防衛2022_1-3-4.indd 79防衛2022_1-3-4.indd 79 2022/06/16 13:25:472022/06/16 13:25:47
106: 過することのできない危険ラインに至った」 との評
価のもと、 「暫定的に中止していた全ての活動を再
稼働する問題を迅速に検討」 することを指示した。
実際に北朝鮮は、 2022年2月以降ICBM級弾道ミ
サイルを発射しており、 同年3月24日の発射後に
は、 米国との長期的対決を徹底的に準備していくと
述べている。 このように、 北朝鮮は2018年4月に
自ら表明した、 「大陸間弾道ロケット試験発射」 の停
止を含む決定に反する行動をとっており、 一方的な
挑発をさらにエスカレートさせる可能性も含め、 今
後の動向が注目される。
(2) 韓国との関係
2018年、 南北関係は大幅に進展した。 3回にわた
る南北首脳会談で、 南北の敵対行為の全面的な中止
や、 朝鮮半島の非核化の実現を共通の目標として確
認することなどを含む 「板門店宣言文」 、 軍事的な敵
対関係の終息などを含む 「9月平壌共同宣言」 、 軍事
的な緊張緩和のための具体的な措置について盛り込
んだ 「 「板門店宣言文」 履行のための軍事分野合意
書」 に合意した。
しかし、 2019年は、 南北間の対話や協力事業に
大きな進展はなく、 2020年には、 南北関係に一時
緊張の高まりが見られた。 同年6月以降、 脱北者団
体が金正恩委員長を非難するビラなどを散布したこ
とへの反発をはじめ、 北朝鮮は、 開ケソン
城の南北共同連
絡事務所の爆破、 DMZ付近での軍事態勢の強化な
どを含む軍事行動計画の検討発表 (後にこれを保留
したと発表) といった動きを見せた。
一方、 韓国に対しては硬軟織り交ぜた姿勢で臨ん
でいる様子も見受けられる。 2021年1月、 朝鮮労働
党第8回大会において金正恩委員長は、 韓国側の態
度次第では、 南北関係が平和と繁栄の新たな出発点
へと戻ることもありうると言及した。 同年7月には
1年以上断絶していた南北間の通信連絡線が復元
(その後、 同年8月に不通となったが同年10月に再
度復元) された。 また、 金正恩委員長は、 同年9月、
韓国の文ムン ・ ジェイン
在寅大統領 (当時) が同月の国連総会で提
31 大韓貿易投資振興公社の発表による。案した 「終戦宣言」 に対して、 まずは北朝鮮への 「偏
見的な見方と不公正で二重的な態度、 敵視の視点と
政策」 を撤回すべきと述べつつ、 南北関係の先行き
は韓国側の態度にかかっているとの考えを示した。
さらに、 同年10月、 韓国が手出しをしなければ朝鮮
半島の緊張は誘発されない、 韓国を対象として国防
力を強化するのではないとしたうえで、 「同族同士
で武装を使用する」 歴史を繰り返してはならないと
述べた。
2022年5月に発足した 尹ユン ・ ソンニョル
錫悦政権による対北朝
鮮政策や北朝鮮の反応も含め、 今後の南北関係の動
向が注目される。
(3) その他の国との関係
①中国との関係
北朝鮮にとって中国は極めて重要な政治的・経
済的パートナーであり、 北朝鮮に対して一定の影響
力を維持していると考えられる。 1961年に締結さ
れた 「中朝友好協力及び相互援助条約」 が現在も継
続している。 また、 中国は北朝鮮にとって最大の貿
易相手国であり、 2020年の北朝鮮の対外貿易 (南
北交易を除く) に占める中国との貿易額の割合は約
9割31と極めて高水準で、 北朝鮮の中国への依存が
指摘されている。
北朝鮮情勢や核問題に関して、 中国は、 「デュア
ルトラックの並進」 (朝鮮半島の非核化及び休戦メ
カニズムから平和メカニズムへの転換) 構想と 「段
階ごと、 同時並行」 という原則に基づき、 対話と協
議を通じて問題を解決すべきであり、 半島の平和と
安定の擁護、 半島の恒久的な平穏実現のために建設
的な役割を発揮したい旨表明している。 このような
中、 2021年10月には中国はロシアと共同で、 北朝
鮮は多くの非核化措置を既に講じている、 経済・民
生分野における一部制裁措置の調整を行うべきとし
て、 北朝鮮に関する国連安保理決議案を提出した。
中朝首脳会談は2018年3月以降5回実施された
が、 2021年1月、 金正恩委員長は、 こうした中朝首
脳会談について、 「戦略的意思疎通と相互理解」 を深
97 令和4年版 防衛白書
わが国を取り巻く安全保障環境 第Ⅰ部
諸外国の防衛政策など
第3
章
防衛2022_1-3-4.indd 97防衛2022_1-3-4.indd 97 2022/07/15 16:38:502022/07/15 16:38:5その結果、精度は低いですが、この質問文と関連度の高いPDFのページのindexとその内容を表示することができました。
2. Text Splittersの使い方
次は、軍隊に関しての文章に対してsplit_textというメソッドを用いて、「\n\n」(改行2つ)でテキスト分割を行なっています。
さらにchunk_sizeを100に設定していることにより、テキスト分割された塊が100文字を超えないほどの塊になるようにしています。
from langchain.text_splitter import CharacterTextSplitter
long_text = """
軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。
軍隊の主な任務は以下の通りです。
国家防衛: 軍隊は外敵からの攻撃に対抗し、国家の安全と領土の完全性を維持するための主要な力です。
国際的な平和維持活動: 多くの軍隊は、国際連合の一部として、または二国間協定に基づいて平和維持活動に参加します。
内部の治安維持: 一部の国では、軍隊が国内の治安維持や社会秩序の維持を担当することがあります。
人道的任務: 災害救助、救急医療、食糧供給など、非戦闘の人道的任務を担当することもあります。
威嚇と抑止: 軍隊は他国に対する威嚇や抑止力としても機能します。これにより、敵対的行動を起こす前に他国を思いとどまらせることができます。
。
"""
print(len(long_text))
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 100,
chunk_overlap = 0,
length_function = len,
)
text_list = text_splitter.split_text(long_text)
print(text_list)
print(len(text_list))
document_list = text_splitter.create_documents([long_text])
print(document_list)
print(len(document_list))
これに対する実行結果は次の通りです。
427
['軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。', '軍隊の主な任務は以下の通りです。\n\n国家防衛: 軍隊は外敵からの攻撃に対抗し、国家の安全と領土の完全性を維持するための主要な力です。', '国際的な平和維持活動: 多くの軍隊は、国際連合の一部として、または二国間協定に基づいて平和維持活動に参加します。', '内部の治安維持: 一部の国では、軍隊が国内の治安維持や社会秩序の維持を担当することがあります。\n\n人道的任務: 災害救助、救急医療、食糧供給など、非戦闘の人道的任務を担当することもあります。', '威嚇と抑止: 軍隊は他国に対する威嚇や抑止力としても機能します。これにより、敵対的行動を起こす前に他国を思いとどまらせることができます。\n\n。']
5
[Document(page_content='軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。', metadata={}), Document(page_content='軍隊の主な任務は以下の通りです。\n\n国家防衛: 軍隊は外敵からの攻撃に対抗し、国家の安全と領土の完全性を維持するための主要な力です。', metadata={}), Document(page_content='国際的な平和維持活動: 多くの軍隊は、国際連合の一部として、または二国間協定に基づいて平和維持活動に参加します。', metadata={}), Document(page_content='内部の治安維持: 一部の国では、軍隊が国内の治安維持や社会秩序の維持を担当することがあります。\n\n人道的任務: 災害救助、救急医療、食糧供給など、非戦闘の人道的任務を担当することもあります。', metadata={}), Document(page_content='威嚇と抑止: 軍隊は他国に対する威嚇や抑止力としても機能します。これにより、敵対的行動を起こす前に他国を思いとどまらせることができます。\n\n。', metadata={})]
5実行すると、5つの塊に分割されたことがわかります。
また、1つの塊の長さを見てみましょう。
len("軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。")これに対する実行結果は次の通りです。
128
最初の塊を見てみると、126文字であり、100文字よりやや多いですが、100文字に近い塊であることが確認できます。(イマイチで申し訳ない…)
3. Vectorstoresの使い方
ここでは、TextLoaderというDocument Loadersのモジュールを使って文字列を読み込み、その中のデータを参考に、質問に答えさせたいと思います。
質問文に答える際には、便利なパッケージであるVectorstoreIndexCreatorというクラスを利用します。
text_splitterには、先ほど使用した約2行の文章を1塊にするクラス(100文字のチャンクで区切ってくれるSpilitter)を代入します。
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 100,
chunk_overlap = 0,
length_function = len,
)
VectorstoreIndexCreatorに、vectorstoresのクラスとembeddingのモデルとtext_splitterのクラスを入れると、質問に答えるクラスが出来上がります。
index = VectorstoreIndexCreator(
vectorstore_cls=Chroma,
embedding=OpenAIEmbeddings(),
text_splitter=text_splitter,
).from_loaders([loader])
また、通常のqueryというメソッドのほかにquery_with_sourcesというメソッドを用いると、質問文と参考したデータのファイル名も表示できます。
answer_with_sources = index.query_with_sources(query)
print(answer_with_sources)
最初のプロンプトとしては「自衛隊は何のために訓練しているのか?」と質問してみます。
query = "軍隊は何のために訓練しているのか?"
print(f"\n\n{query}")
docs = docsearch.similarity_search(query)
print(docs[0].page_content)
「long_text」の中で軍隊とは何かの説明はインプットされているので、それらを参考に答えが出力されることが想定されます。
ここまでのプログラムをまとめると、次の通りです。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.indexes import VectorstoreIndexCreator
from langchain.document_loaders import TextLoader
long_text = """
軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。
軍隊の主な任務は以下の通りです。
国家防衛: 軍隊は外敵からの攻撃に対抗し、国家の安全と領土の完全性を維持するための主要な力です。
国際的な平和維持活動: 多くの軍隊は、国際連合の一部として、または二国間協定に基づいて平和維持活動に参加します。
内部の治安維持: 一部の国では、軍隊が国内の治安維持や社会秩序の維持を担当することがあります。
人道的任務: 災害救助、救急医療、食糧供給など、非戦闘の人道的任務を担当することもあります。
威嚇と抑止: 軍隊は他国に対する威嚇や抑止力としても機能します。これにより、敵対的行動を起こす前に他国を思いとどまらせることができます。
"""
print(len(long_text))
with open("./long_text.txt", "w") as f:
f.write(long_text)
f.close()
loader = TextLoader('./long_text.txt')
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 100,
chunk_overlap = 0,
length_function = len,
)
index = VectorstoreIndexCreator(
vectorstore_cls=Chroma, # Default
embedding=OpenAIEmbeddings(), # Default
text_splitter=text_splitter,
).from_loaders([loader])
query = "軍隊は何のために訓練しているのか?"
print(f"\n\n{query}")
answer = index.query(query)
print(answer)
answer_with_sources = index.query_with_sources(query)
print(answer_with_sources)
query = "戦争はなくならないのか?"
print(f"\n\n{query}")
answer = index.query(query)
print(answer)
answer_with_sources = index.query_with_sources(query)
print(answer_with_sources)
これに対する実行結果は次の通りです。
軍隊は何のために訓練しているのか?
国家の防衛や、必要に応じてその国益を保護するために訓練されています。
{'question': '軍隊は何のために訓練しているのか?', 'answer': ' 軍隊は国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織で、主な任務として国家防衛、威嚇と抑止、内部の治安維持、人道的任務があります。\n', 'sources': './long_text.txt'}
戦争はなくならないのか?
いいえ、戦争はなくならないと考えられています。軍隊は、国家防衛や威嚇と抑止などの目的のために存在しています。
{'question': '戦争はなくならないのか?', 'answer': ' It is possible that wars will not be eliminated.\n', 'sources': './long_text.txt'}
しっかり返答してくれていることが確認できました。
また、query_with_sourcesを用いたことで、質問文と参照としたファイル名を出力してくれています。
<補足説明>
VectorstoreIndexCreatorというクラスについて、詳細をお伝えいたします。
VectorstoreIndexCreatorでは、以下のような一連の操作を行うことで、テキスト情報の処理と管理を実現しています。
Text Splittersを活用してテキストを適切な単位に分割します。
次に、エンベディングモデルを利用し、この分割されたテキストをベクトル形式に変換します。
このベクトル化された情報とそのインデックスを、ChromaなどのVectorStoresに保管します。保管された情報は、後にクエリ(プロンプト)の検索や分析に活用されます。
新たなクエリが与えられたとき、それを同じくエンベディングモデルを用いてベクトル化します。
このクエリベクトルとVectorStores内のベクトルとの間で関連性を計算し、関連度の高いデータ群を探索します。
この関連度の高いデータ群を基に、LLM(Language Model)を用いて適切な回答を生成します。
4. Retrieversの使い方
Retrieverを使って、エンベディングされたvectorstoresを対象に、as_retrieverメソッドを適用することで、Retrieverのインスタンスを作り出すことが可能です。
その後、Retrieverのインスタンスに対してget_relevant_documentsメソッドを呼び出すことにより、関連性のあるドキュメントを探索することができます。
それでは、実際に実行してみましょう。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
long_text = """
軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。
軍隊の主な任務は以下の通りです。
国家防衛: 軍隊は外敵からの攻撃に対抗し、国家の安全と領土の完全性を維持するための主要な力です。
国際的な平和維持活動: 多くの軍隊は、国際連合の一部として、または二国間協定に基づいて平和維持活動に参加します。
内部の治安維持: 一部の国では、軍隊が国内の治安維持や社会秩序の維持を担当することがあります。
人道的任務: 災害救助、救急医療、食糧供給など、非戦闘の人道的任務を担当することもあります。
威嚇と抑止: 軍隊は他国に対する威嚇や抑止力としても機能します。これにより、敵対的行動を起こす前に他国を思いとどまらせることができます。
"""
print(len(long_text))
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 100,
chunk_overlap = 0,
length_function = len,
)
document_list = text_splitter.create_documents([long_text])
print(document_list)
print(len(document_list))
db = Chroma.from_documents(document_list, OpenAIEmbeddings())
retriever = db.as_retriever()
query = "軍隊はなぜ訓練しているのか?"
print(f"\n\n{query}")
docs = retriever.get_relevant_documents(query)
print(docs[0].page_content)
これに対する実行結果は次の通りです。
WARNING:langchain.text_splitter:Created a chunk of size 129, which is longer than the specified 100
424
[Document(page_content='軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。', metadata={}), Document(page_content='軍隊の主な任務は以下の通りです。\n\n国家防衛: 軍隊は外敵からの攻撃に対抗し、国家の安全と領土の完全性を維持するための主要な力です。', metadata={}), Document(page_content='国際的な平和維持活動: 多くの軍隊は、国際連合の一部として、または二国間協定に基づいて平和維持活動に参加します。', metadata={}), Document(page_content='内部の治安維持: 一部の国では、軍隊が国内の治安維持や社会秩序の維持を担当することがあります。\n\n人道的任務: 災害救助、救急医療、食糧供給など、非戦闘の人道的任務を担当することもあります。', metadata={}), Document(page_content='威嚇と抑止: 軍隊は他国に対する威嚇や抑止力としても機能します。これにより、敵対的行動を起こす前に他国を思いとどまらせることができます。', metadata={})]
5
軍隊はなぜ訓練しているのか?
軍隊は、一般的に、国家の防衛や、必要に応じてその国益を保護するために訓練された武装組織のことを指します。軍隊は通常、陸軍、海軍、空軍などの軍種に分けられます。一部の国では、さらに特殊部隊、サイバー戦力、宇宙軍など、特定の戦略的目的を持った部門も存在します。
すると「軍隊はなぜ訓練しているのか?」という質問に対し、関連する文章を検索して出力してくれています。
最後に
次回はChains機能について解説してまいりますので引き続きよろしくお願いします!
この記事が気に入ったらサポートをしてみませんか?