
ComfyUIでアップスケールを試す

はじめまして。X(twitter)の字数制限が厳しいうえにイーロンのおもちゃ箱状態で先が見えないので、実験系の投稿はこちらに書いていこうと思います。
Upscale
AI画像生成にはローカル生成であるStable Diffusion 1.5(SD1.5)やStable Diffusion XL(SDXL)、クラウド生成のDALL-E3など様々なモデルがあります。いずれの場合もポン出しの解像度はそれほど高くなく、それなりの作品に仕上げるには高解像度化(upscale)が必要になってきます。
そしてupscaleにも多くの手法があり、それぞれによって得られる結果もまるで違います。ではどれを選べばよいのでしょう・・・?
ここでは、私が普段使っているupscale手法についてworkflow詳細とともに比較してみます。なにぶん我流が多いですが、手法を選ぶに当たっての一助となれば幸いです。
比較にはこちらのかわいい猫画像を使います。API版DALL-E3で生成したあと部分的にSDXLでimg2imgした画像で、幅1792✕縦1024ピクセルです。

ちなみに普通にPhotoshopで拡大して一部を切り出すとこんな感じです。
当たり前ですが、ぼやけてますね。

Hires.fixモドキ
まずは一番簡単な方法から。
元画像をシンプルに拡大してからKSamplerでサンプリング(img2img)します。プロンプトは元画像と同じか、少なくとも元画像の内容を説明するようなプロンプトにします。
(2024.1.16 フロー画像を差し替えました。Upscale Imageが何故か抜けてた)

denoiseは0.5付近の値を指定してください。1.0に近いと元の画像をほぼ無視します。逆に0.0付近だとノイズを残すことがあります。
左側の解像度を自動計算しているところはちょっと複雑ですが、決まったサイズであれば直接設定してもいいと思います。式を使って解像度を計算するノードにはMath Expression(https://github.com/pythongosssss/ComfyUI-Custom-Scripts)を使っています。
できあがった画像がこちら。

雰囲気合っていますが、ところどころ元画像とは違う感じになってしまいました。猫じゃらしが猫に化けてますし。
いわゆるアーティファクトというやつです。
この方法はお手軽な一方でとにかくアーティファクトが出やすく、また細部(特に指)の破綻が起きやすい欠点があります。1.x倍程度拡大するぶんには良いですが、大きく拡大するケースには向いていません。
ESRGAN系upscale
画像拡大用に作られたESRGAN系のupscaleモデルを使う方法です。例えばRealESRGAN_x4plus_anime_6B.pthとか。これらはテキストによる条件付けをしておらず、常に安定した結果を生み出せます。一方で画像を大きく変化させることはできません。

upscaleモデルによっては4倍になることもあります。これだと大きすぎたので、ここでは出力を半分に縮小してトータル2倍になるようにしました。

今回使ったupscaleモデルがアニメ画像用ということもあり、ディティールが潰れてしまっていますね。
また人物の目がおかしくなってしまいました。このタイプのupscaleは縮小したら元に戻るように拡大するので、元画像に含まれていたノイズのようなピクセルに過剰反応しがちです。
元画像の雰囲気をよく残してくれるため、どうしても解像度が欲しければ使うという感じでしょうか。私は使っていませんが・・・
ESRGAN系upscale + Detailer (SDXL)
https://github.com/ltdrdata/ComfyUI-Impact-Pack に含まれるDetailerを使います。
Detailerは画像をタイルに分割してタイルごとに拡大後、タイル間のつなぎ目をうまく処理しながら再結合してくれます。拡大にはSD1.5やSDXLのモデルを使ったimg2imgが使われるようです(よくわかってない)。
接続方法とパラメータの例がこちら。ここではSDXLのHKXL v2.0を使いました。プロンプトには元画像と同じものを入れます。
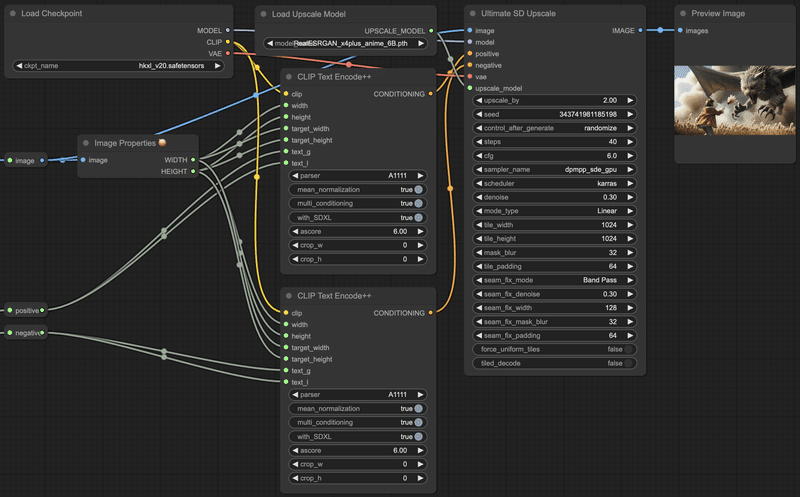
処理時間は結構かかります。元の解像度がそこそこ高いこともあって、数分ぐらい。

ESRGAN系upscale単独の場合よりも細部がしっかりしてくれました。人物の目も妥当な感じに作り直してくれています。猫のヒゲが途切れるようなこともありません。
一方でアニメ系モデルらしく、ややフラットな塗りでディティールが控えめです。元画像がDALL-E3で細部ノリノリだったので、猫さんについては気になる仕上がりになってしまいました。
このあたりはリアル系モデルを使うことで改善できる可能性もありますし、Stable Diffusion系列(というよりLatent Diffusion系モデル)の限界の可能性もあります。またDetailerのパラメータによっても結果は変わります。
ESRGAN系upscale + Detailer (SD1.5)
同じくDetailerを使い、SD1.5と組み合わせた場合です。
こちらの場合は、というかこちらがDetailer本来の使い方だと思うのですが、ControlNet Tileと組み合わせることができます。
(SDXL用のControlNet Tileはまだないみたい?)
一方で、SDXLよりもtile_widthとtile_heightを小さくする必要があります。
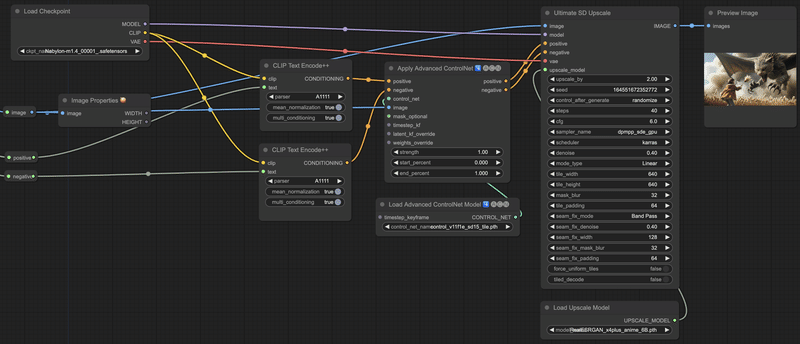
結果がこちら。SDXLよりもタイル数が多くなるからか、さらに時間がかかりました。

他のControlNetを組み合わせることもできそうです。
これはさらにControlNet Depthを組み合わせた例。Depth推定には拙作NegiTools https://github.com/natto-maki/ComfyUI-NegiTools のDepth Estimation by Marigoldノードを使用しました。
ここは普通のDepth推定でもいいと思います。


人物は元の雰囲気を残しつつも、いつもの絵柄になってくれました。
人物以外は微妙かも・・・?
猫さんの質感が風呂上がりみたい。あと粉塵に妙な模様が増えてますね。
ControlNet Tileが使えることで、denoiseにより大きい値を使えるようになります。モデル本来の絵柄に寄せやすい点はメリットです。SD1.5を使うメリットは絵柄の制御をしやすい(あとnsfwが出る)点にあるので、そういう意味ではDetailerと組み合わせるメリットは大きいと言えるでしょう。
一方でタイルサイズが小さくなるからか、絵全体の奥行き感や立体感が減ってしまう気がしました。特に猫さんはSDXLのとき以上に油絵感のある仕上がりで、このケースでは合ってないですね。
違うモデルを使えばマシかもしれません。
Photoshopのニューラルフィルター
ComfyUIからは利用できないのですがAIつながりということで。
Photoshopを使えるなら、ニューラルフィルターでスーパーズームという手もあります。
2xに設定して、シャープは3前後。パラメータは調整の余地があると思います。

写真に対してはかなりの高性能だと思います。毛や布の質感は他にはない精細感があります。エッジの立ち方も自然です。
一方で、イラストには弱い点と、元画像の作り変えはしない(例えばヒゲの不連続はそのまま)という点が欠点です。
まとめ
ここまでに紹介した手法による結果を一箇所に集めてみました。

いかがでしょうか? ざっくりとした印象では
イラスト寄りならDetailer (SDXLかSD1.5)がよさげ
写真寄りだとPhotoshopのニューラルフィルターが第一候補。でも細部が修復されない
といったところで、残念ながら「これ使っておけば完璧!」という手法は今のところ無いようです。
状況によって使い分けることになりそう。
特に今回のテスト画像のように複数の主題を含むような画像では、画面内の部分部分によっても最適な方法が違ってきます。
それじゃどうするのが良いかというと、
「全部作って混ぜる」
しかないですね。クッソ面倒
合成してみた
今回のかわいい猫さん画像で混ぜてみました。
猫さんはPhotoshopのニューラルフィルターをベースにする。ただ他とのバランスが取れないため、少しDetailer (SD1.5)を混ぜる
人物の顔と手はDetailer (SD1.5)を採用
背景、特に粉塵部分はPhotoshopのニューラルフィルター出力を元に、平滑化フィルタをかけてソフトな描写にする
猫さんのヒゲのみ部分的にDetailer (SD1.5)の出力を合成
こんな感じです。最後に色調整してできあがり。


この記事が気に入ったらサポートをしてみませんか?