
リミナル未来大を作ろう Part1

はじめに
本記事は「あらた界隈とそのまわりとそのまわりとそのまわり 訳: だれでも参加可能 なアドカレ 2023 ドキッ!?オタクだらけのアドベントカレンダー(完走するとは言っていない)」、略してあらた界隈アドベントカレンダー6日目の記事です。書いてて文章力のなさに気が付きましたが、温かい目でご覧ください。
リミナルスペース
さて、早速ですが皆様はリミナルスペースなるものをご存じでしょうか?
リミナルスペース (Liminal Space) とは、インターネット上で、簡素で不気味、超現実的な空間をいうインターネット・ミーム。もとは建築用語で、廊下、階段、ロビーなどの、移動のために使われる人工的構造物のことを指す。それが転じて上記の通りとなった。リミナルスペースは建築における不気味の谷に当たるのではないかという指摘がある。 また、リミナルスペースの不気味さは見慣れた場所が通常の文脈を欠いて提示されることに起因するという指摘もある。(Wikiより)
と書かれていますが、実際に画像を見ていただいた方が早いと思います。

The Backroomsというインターネットミームでもよく見ますね。最近話題の8番出口というゲームもリミナルスペースにインスパイアされたらしいです。
画像生成AI
話は変わりますが、私は最近「画像生成AI」なるものをよく触っています。というのも、プロジェクト学習でそれをメインに研究を行っていたからです。画像生成AI(主に扱っていたのはStableDiffusion)は、テキストの入力に応じて画像を出力するというAIです。
実際に生成している画像をお見せしましょう。
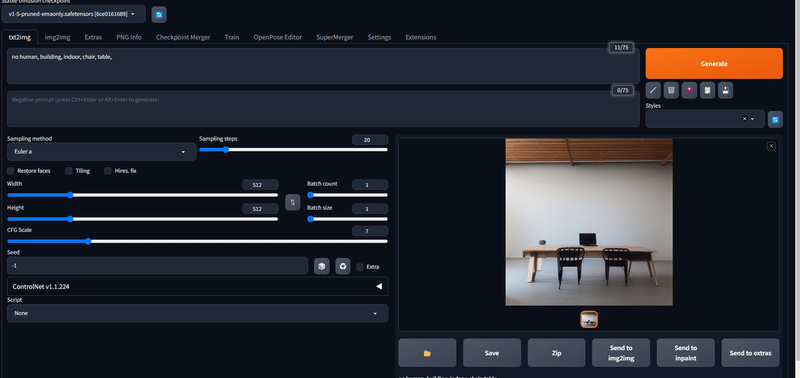
少し見づらいですが、「no human, building, indoor, chair, table,」という入力に対して右のような画像を生成しています。
この画像を見ていただいたらわかると思うのですが、なんというか少し不気味…リミナルスペース味を感じないでしょうか?もしかしたら、画像生成AIを使えばそれっぽいリミナルスペースを再現できるのでは?と思ったのがこの記事を書こうと思い至った経緯です。
とはいったものの…
実は、画像生成AIを用いてリミナルスペースを再現したというモデルはもう存在していて、単にリミナルスペースを生成するというのは特に新しいことではないのです。
ここで、リミナルスペースはなぜ不気味で不安な感覚に陥るかをもう一度考えてみます。私が思うに、それは「知っているようで知らない」ということに起因するのではないかと考えました。つまり、リミナルスペース味を感じるために必要な要素として、その空間を「知っている(が見たことない)」必要があります。
自分含め、周りの人間が知っている空間…察しのいい皆さんなら気づかれたかと思いますが、未来大生が共通に知っている建物が一つあると思います。それが公立はこだて未来大学本棟です。
つまり、未来大っぽい空間をAIで生成することで、全未来大生がリミナルスペース味を感じる画像が作れるのではないかと考えたわけです。
制作開始
前書きが長くなりましたが、リミナル未来大を作っていきましょう。
「どのようにして作るのか」ですが、簡単に説明すると未来大構内の写真を30枚ほど追加学習することで、(理論上は)それっぽい画像を出力することができます。実際に未来大内の写真を撮ってきました。

(撮っているときに何回か同じ人にすれ違って不審者か何かと思われてたかも…)
で、これを高性能PCにぶち込んで学習させました。第一弾の学習は約10分で終わりました。(とはいえVRAMを15GB消費しています)
Liminal-FUN 第一弾
できた画像がこちら


それっぽい!!物ができましたが、もうちょっとリミナル感ほしいところではあります。これはかなり短時間で学習させたものだったので、次は設定を変えて1時間ほど学習させてみましょう。
Liminal-FUN 第二弾
設定を変えて1時間ほど学習させてみました。結果は…


皆さんに伝わるかはわかりませんが、最初のものより多少きれいに生成できているかなといった印象を受けました。(まぁほぼ変わってないと言ったら変わっていないのですが)
リミナル感がたりない
ただ、やはりリミナル感がどうしてもないと感じてしまいます…どうしたものか…
そこで、(他の方が作ってくれている)リミナルスペースモデルをベースモデルとして扱っていこうと思います。何言ってるのかわからないと思いますが、とにかくよりリミってる感じを出したいということです。
(気になる人はstable diffusionのLoRAとかの話を調べてみてね!今回は、未来大LoRAを作って出力しています)
ベースとなるモデル単体でこんな感じの画像を出力してくれます。

ちょっと荒いですが、もともとの入力テキストがトリガーワードのみだったのでかなりいい感じ!
では、このモデルを使って生成した未来大がこちら




どうでしょうか?結構リミナルスペースっぽいのでは!?
さいごに
いかがでしたでしょうか?
最後に作ったものは、最初の方よりかなりリミってる!けど、今度はあんまり未来大っぽくないというのが正直な感想です。みんなが思う未来大っぽさって何だろう?
今回はここまでとなりますがPart2ではもう少し工夫して、よりリミナルな未来大を作っていきたいですね。(忙しいのでやるとは言ってない)
この記事が気に入ったらサポートをしてみませんか?